Ausfallsichere Systeme mit KVM-Cluster

Fangnetz

Beim Einsatz von Clustersystemen ist zwischen mehreren Varianten zu unterscheiden. Auf der einen Seite existieren die so genannten High-Availability-Cluster (HA), sie sorgen für eine möglichst hohe Verfügbarkeit eines bestimmten Dienstes. Fällt ein System aus, wandert der darauf laufende Dienst einfach auf einen anderen Clusterknoten. Ein Benutzer bekommt von dem Ausfall eines Systems somit überhaupt nichts mit.
Auf der anderen Seite sorgen so genannte Load Balancer für einen Lastenausgleich zwischen den verschiedenen Systemen. Üblicherweise leiten hier redundante Frontend-Systeme die eingehenden Anfragen an mehrere Backend-Systeme weiter. Je nachdem, welcher Algorithmus zum Einsatz kommt, verteilen die im Vordergrund laufenden Systeme ankommende Anfragen beispielsweise im Round-Robin-Verfahren an die eigentlichen Server im Hintergrund.
Es gibt auch Verfahren, bei denen der Admin anhand der Load der Systeme entscheidet, wohin eine Anfrage wandert. Fällt eines dieser Systeme aus, entfernen die Frontend-Router es aus ihren Routingtabellen. So ist sichergestellt, dass keine Pakete im Nirwana landen.
Schließlich existieren auch noch die so genannten High-Performance-Cluster (HPC), bei ihnen kommt es auf möglichst große Rechenleistung an. Um diese zu erreichen, unterteilt der Admin eine anstehende Aufgabe einfach in mehrere Happen und verteilt sie dann auf die einzelnen Systeme im Cluster. Somit stehen sämtliche Ressourcen (CPU, Speicher, Disks) allen Knoten des Clusters zur Verfügung. Solche Systeme kommen immer dann zum Einsatz, wenn es um extrem komplexe Berechnungen geht, beispielsweise in der Automobilindustrie, wo Crash-Simulationen einen immensen Rechenaufwand erfordern.
Hochverfügbar
In diesem Artikel geht es um den Aufbau eines High-Availability-Clusters (HA). Wie beschrieben kümmert dieser sich um die Ausfallsicherheit von Diensten, etwa eines Web- oder Mailservers. Was vielen gar nicht bekannt ist: Auch virtuelle Computer-Instanzen zählen zu den Clusterdiensten. Da mittlerweile die Virtualisierung von Computersystemen auch im x86-Umfeld einen sehr ausgereiften Stand erreicht hat, kommt diese auch hier zum Einsatz. Statt einzelne Dienste hochverfügbar anzubieten, kümmert sich der Clustermanager um die Bereitstellung und Überwachung von kompletten virtuelle Maschinen-Instanzen.
Das Ganze sieht dann so aus, dass die physischen Hostsysteme über eine bestimmte Anzahl von virtuellen Maschinen verfügen. Diese liegen in einem von allen Hostsystemen zugänglichen, gemeinsam genutzen Speicherbereich. Das kann beispielsweise ein iSCSI- oder Fibre-Channel-Storage sein. Zu Testzwecken ist auch eine NFS-Freigabe möglich, wobei aber die Performance leidet.
Der Clustermanager prüft in regelmäßigen Abständen, ob die einzelnen Hostsysteme noch verfügbar sind. Hierzu greift er auf unterschiedliche Methoden zurück. So ist jeder Clusterknoten dazu angehalten, in regelmäßigen Abständen so genannte Heartbeat-Meldungen über das Netzwerk zu versenden. Alternativ existieren auch Implementierungen, in denen die Systeme Statusmeldungen auf einem Datenträger hinterlegen oder so genannte Heuristiken ausführen müssen, beispielsweise das Anpingen eines zentralen Routers.
Bleiben die Lebenszeichen der einzelnen Clusterknoten aus, kümmert sich der Clustermanager um entsprechende Maßnahmen – beispielsweise den Neustart eines ausgefallenen Systems. Dieser Vorgang ist auch unter dem Namen Fencing, früher als STONITH (Shoot The Other Node In The Head) bekannt.
Dies ist notwendig, damit ein Clusterknoten nach einer Unterbrechung nicht fälschlicherweise wieder auf seine Ressourcen zugreifen kann, nachdem ein anderer Knoten diese bereits übernommen hat. Klassisches Beispiel ist ein Datenspeicher, der als Cluster-Ressource definiert und einem Knoten exklusiv zugeteilt ist. Fällt dieser Knoten aus, übernimmt ein anderer den Datenspeicher und führt I/O-Operationen auf ihm aus.
Erwacht der vermeintlich defekte Knoten wieder, glaubt er immer noch exklusiven Zugriff auf den Datenspeicher zu haben. Es käme also dazu, dass zwei Knoten gleichzeitig auf dieselben Daten zugreifen – eine Beschädigung der Daten wäre die Folge. Um dies zu verhindern, führen Fencing-Methoden einen Neustart der Maschine durch. Üblicherweise geschieht dies über fernschaltbare Stromsteckdosen oder auch über integrierte Management-Boards, beispielsweise HP-ILO-Karten oder IBM-Managementsysteme.
Ein Clustermanager kann virtuelle Systeme auch online migrieren. Das ist besonders dann hilfreich, wenn der Admin an den bestehenden Servern Wartungsarbeiten durchführen möchte. In einem solchen Fall wandern alle virtuellen Systeme eines Clusterknotens auf ein anderes System im Clusterverbund. Der Benutzer bekommt von der Migration der virtuellen Systeme nichts mit und kann ganz normal weiterarbeiten.
Hypervisor-Wahl
Um virtuelle Maschinen als Clusterservice zu betreiben, sind einige Vorarbeiten notwendig. Zunächst muss der Admin den passenden Hypervisor aussuchen, den Vermittler zwischen virtuellen Maschinen und der tatsächlich vorhandenen Hardware. Neben diversen kleineren Lösungen bietet Linux mit Xen ( Abbildung 1 , [1] ) und KVM ( Abbildung 2 , [2] ) zwei quelloffene Lösungen, die sich in der Vergangenheit bewährt haben.
 Abbildung 1: Bei Xen bauen alle virtuellen Maschinen auf einem privilegierten Managementsystem auf. Dabei ist dieses System selbst bereits auch schon virtualisiert.
Abbildung 1: Bei Xen bauen alle virtuellen Maschinen auf einem privilegierten Managementsystem auf. Dabei ist dieses System selbst bereits auch schon virtualisiert.
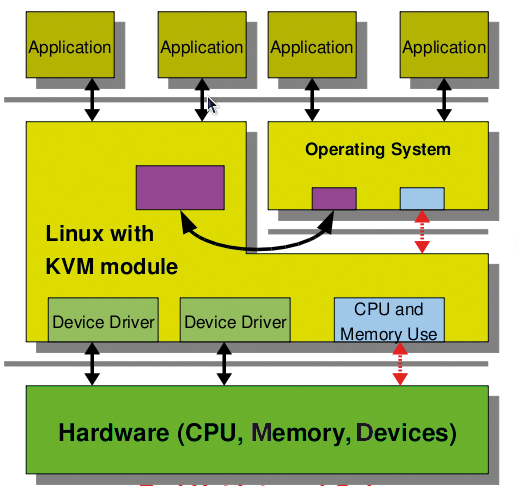 Abbildung 2: KVM ist durch ein einzelnes Kernelmodul implementiert. Alle virtuellen Maschinen laufen somit als reguläre Prozesse auf einem herkömmlichen Linux-Kernel.
Abbildung 2: KVM ist durch ein einzelnes Kernelmodul implementiert. Alle virtuellen Maschinen laufen somit als reguläre Prozesse auf einem herkömmlichen Linux-Kernel.
Xen bietet den Vorteil, dass bei seinem Einsatz nicht zwingend besondere Hardware notwendig ist, um virtuelle Maschinen-Instanzen unter Linux zu betreiben. Der Grund hierfür liegt in den modifizierten Treibern, die im Xen-Kernel zum Einsatz kommen. Diese sorgen dafür, dass die virtuellen Maschinen nicht direkt auf die Hardware zugreifen, sondern mit dem Hypervisior kommunizieren und dieser sich dann um die Vermittlung der diversen Anfragen an die tatsächliche Hardware kümmert.
Würden die virtuellen Maschinen direkt auf die Hardware zugreifen, könnte das zu einem Fehler führen, da diese in einer virtualisierten Umgebung, also in einem nicht privilegierten Modus ablaufen. Aus diesem Grund ist kein direkten Zugriff auf die Hardware möglich.
Ähnliche Artikel




Konfigurationsmanagement

Themen


