Anwendungen tracen mit Oprofile und Systemtap

Ozapft is

Üblicherweise
greift der versierte Admin auf Tools wie
»ps«
,
»vmstat«
oder ähnliche zurück, wenn es darum geht, Statistiken über einzelne Subsysteme wie Netzwerk, Speicher oder Block-I/O einzuholen. Sie helfen ihm dabei, Engpässen auf Hardware- oder Software-Seite auf die Schliche zu kommen. Diese Tools sind für einen ersten Überblick sicher hilfreich, wer aber einen tieferen Blick hinter die Kulissen werfen möchte, der braucht weitere Werkzeuge.
Auch hier gehören einige Tools zur Standardausrüstung. Zum Tracen von Anwendungen existiert beispielsweise das bekannte
»strace«
(siehe den Artikel in diesem Heft). Das Tool listet im einfachsten Fall alle Systemaufrufe (Syscalls) und deren Argumente mit Returncode für eine beliebige Anwendung auf. Durch eine Auswahl entsprechender Optionen ist eine sehr selektive Ausgabe von Strace möglich. Möchte der Administrator beispielsweise überprüfen, ob eine Anwendung auch die mit viel Mühe erzeugte Konfigurationsdatei einliest, ruft er Strace wie folgt auf:
strace -e trace=open -o mutt.trace mutt
In der Ausgabedatei
»/tmp/mutt.trace«
landen nun alle Aufrufe des Syscall
»open«
für die Anwendung
»mutt«
. Mit
»grep«
ist dann leicht nach der gewünschten Konfigurationsdatei zu suchen.
Einen Schritt weiter gehen Anwendungen aus der Kategorie Profiler. Hierzu zählt beispielsweise das bekannte Tool Oprofile [1] . Es gibt Auskunft über die Performance einzelner Anwendungen, des Kernels oder auch des kompletten Systems. Hierzu greift Oprofile bei aktueller Hardware auf so genannte Performance-Counter der eingesetzten CPU zurück. Diese enthalten Informationen darüber, wie oft ein bestimmtes Event stattgefunden hat. Als Events bezeichnet man in diesem Zusammenhang etwa Zugriffe auf den Arbeitsspeicher oder die Anzahl von Interrupts. Diese Informationen sind zum Auffinden von Engpässen oder zum Debuggen des Systems recht hilfreich.
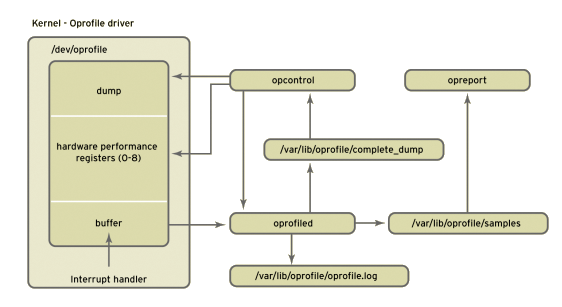 Abbildung 1: Die Architektur von Oprofile.
Abbildung 1: Die Architektur von Oprofile.
Zur Installation von Oprofile ist das Paket
»kernel-debuginfo«
[2]
notwendig. Es enthält die Zuordnung so genannter Symbole auf den passenden Maschinencode. Wichtig dabei ist, dass die Version des Pakets
»kernel-debuginfo«
identisch mit der Version des eingesetzen Kernels ist. Sie installieren es ganz einfach aus dem Standard-Repository der eingesetzten Distribution, unter Fedora beispielsweise mit Yum:
yum install oprofile kernel-debuginfo
Der Aufruf von RPM sollte dann bestätigen, dass
»kernel«
und
»kernel-debuginfo«
die gleiche Versionsnummer besitzen:
rpm -q kernel-PAE kernel-PAE-debuginfo oprofile kernel-PAE-2.6.32.10-90.fc12.i686 kernel-PAE-debuginfo-2.6.32.10-90.fc12.i686 oprofile-0.9.5-4.fc12.i686
Zum Profilen des Kernels müssen Sie Oprofile den Ort des Kernel-Image mit der Option
»--vmlinux«
mitteilen:
opcontrol --setup --vmlinux=/usr/lib/debug/lib/modules/`uname -r`/vmlinux
Bei regulären Anwendungen können Sie die Image-Angabe weglassen. Eine Übersicht der mit Oprofile zählbaren Events liefert der Befehl
»opcontrol --list-events«
(
Listing 1
).
Listing 1
Opcontrol-Events
Je nachdem, welche CPU zum Einsatz kommt, unterscheiden sich die Events. Im Verzeichnis
»/usr/share/oprofile«
existieren für die unterschiedlichen Architekturen entsprechende Listen. Ein Event setzt sich aus einem symbolischen Namen (
»L2_RQSTS«
), einem Counter (500) und einer optionalen Maske (
»0xc0«
) zusammen. Der Counter bestimmt die Genauigkeit eines Profils. Je niedriger der Wert ist, desto öfter wird ein Event abgefragt.
Mit Hilfe der Maske lassen sich spezielle Eigenschaften eines solchen Events abfragen. Das Event
»L2_RQSTS«
gibt beispielsweise Auskunft darüber, wie oft der L2-Cache der CPU abgefragt wurde. Mit der Maske
»0xc0«
aufgerufen liefert Oprofile den Wert für alle verfügbaren CPUs, mit
»0x40«
nur für jene CPU, die gerade den Oprofile-Prozess ausführt.
Möchten Sie ein bestimmtes Event überwachen, verwenden Sie dafür den Aufruf von
Listing 2
. Die Aufrufoption
»--event«
kann dabei durchaus mehrfach vorkommen, um mehr als ein Event zu überwachen. Um noch sicherzustellen, dass keine alten Daten das Ergebnis verfälschen, löscht die Option
»--reset«
sie, bevor Oprofile mittels
»--start«
neue Daten sammelt. Nach einer Weile beendet die Option
»--stop«
das Monitoring des Systems.
Listing 2
Opcontrol-Events
Die so eingesammelten Daten stehen nun im Verzeichnis
»/var/lib/oprofile/samples«
zur Verfügung. Um einen allgemeinen Überblick zu erhalten, rufen Sie diese mittels
»opreport«
auf, entweder als gesammelte Daten für das komplette System oder aber für eine bestimmte Anwendung (
Listing 3
)
Listing 3
Opreport für Mutt
Je nach ausgewähltem Event ergibt sich anhand dieser Informationen ein ziemlich klares Bild davon, was so alles auf dem System los ist. Weitere Informationen zu Oprofile finden sich auf der recht informativen Webseite der Tools [1] .
Systemtap
Das Tool Systemtap [3] hat den Anspruch, Funktionen der klassischen Tracing- und Profiling-Tools wie Strace und Oprofile, zu vereinen und dabei eine gleichzeitig einfache und leistungsfähige Schnittstelle für den Benutzer anzubieten. Ursprünglich wurde Systemtap zum Monitoring des Linux-Kernels entwickelt, neuere Versionen unterstützen auch Userspace-Applikationen.
Systemtap setzt auf dem Kernel-Subsystem
»kprobes«
auf. Es ermöglicht dem Anwender, allen Events im Kernelspace beliebigen Programmcode voranzustellen, zum Beispiel einer Kernelfunktion (
»kernel.function("Funktion")«
) oder einer Funktion innerhalb eines Kernelmoduls (
»module("Modul").function("Funktion")«
) oder eines Systemaufrufs (
»syscall.Systemcall«
). Das so eingeschleuste Programm überwacht das Event und sammelt dazu Informationen. Anders als bei Oprofile, das ein Event ja immer nur periodisch abfragt, ist hiermit ein wesentlich genaueres Ergebnis erzielbar.
Seit einiger Zeit unterstützt Systemtap auch die Abfrage so genannter statischer Tracepoints im Kernel (
»kernel.trace("Tracepoint")«
) und neuerdings auch von Userspace-Applikationen. Diese statischen Tracepoints sind von den jeweiligen Entwicklern an wichtigen Stellen im Programmcode hinterlegt. Da man wohl davon ausgehen kann, dass Entwickler ihre Programme am besten kennen, stellt diese Art von Informationen eine große Hilfe bei ihrem späteren Einsatz dar.
Systemtap-Programme sind in einer Awk-ähnlichen Sprache geschrieben. Ein Parser überprüft das Skript auf syntaktische Fehler, bevor es in die performantere Sprache C übersetzt wird, um anschließend als Modul im Kernel zu landen (
Abbildung 2
). Soll das Modul auf anderen Systemen, auf denen beispielsweise kein Compiler zur Verfügung steht, zum Einsatz kommen, ist dies auch kein Problem. Systemtap erlaubt es, Module auch für andere Kernelversionen zu übersetzen als jene, die auf dem aktuellen System läuft. Das so erzeugte Modul müssen Sie dann nur auf das Zielsystem kopieren und dort mittels
»staprun«
ausführen, dazu aber später mehr.
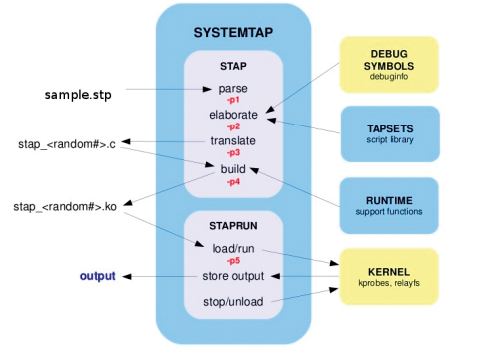 Abbildung 2: Nach einer syntaktischen Prüfung des Systemtap-Skripts wird dieses in C übersetzt und dann als Modul in den Kernel geladen.
Abbildung 2: Nach einer syntaktischen Prüfung des Systemtap-Skripts wird dieses in C übersetzt und dann als Modul in den Kernel geladen.
Da alle großen Linux-Distributionen Systemtap unterstützen, lässt es sich leicht über das Standard-Softwarerepository installieren. Wichtig ist, das Paket
»kernel-debuginfo«
und dieses Mal auch
»kernel-devel«
zu installieren:
yum install kernel-debuginfo kernel-devel systemtap sytemtap-runtime
Die jeweils aktuelle Version findet sich im Git-Repository des Projekts:
git clone http://sources.redhat.com/git/systemtap.git systemtap
Hat die Installation geklappt, überprüft der folgende Einzeiler die korrekte Funktion von Systemtap:
stap -v -e 'probe vfs.read {printf("Datenvon der Festplatte eingelesen.\n"); exit()}'
Findet nun ein Zugriff auf das VFS-Subsystem des Kernels statt, gibt
»stap«
eine Nachricht auf der Standardausgabe aus und beendet sich dann selbst. Das bekannte "Hello World" sieht in Systemtap aus wie in
Listing 4
.
Listing 4
"Hello World" in Systemtap
Dieses simple Beispiel zeigt sehr schön den allgemeinen Aufbau eines Systemtap-Skripts. Es besteht immer aus zwei Teilen, einem Event und einem Handler – vor beiden steht üblicherweise die Anweisung
»probe«
. Im oben genannten Beispiel ist das Event die Funktion
»read.vfs«
und der Handler die
»printf«
-Anweisung, die Text auf Stdout ausgibt. Der Handler gelangt immer dann zur Ausführung, wenn das angegebene Event eintritt. Events können Kernelfunktionen, Systemaufrufe (Syscalls) oder auch – wie im obigen Beispiel – vorgefertige Tapsets sein. Hierbei handelt es sich um vorgefertigte Codeblöcke für bestimmte Kernelfunktionen und Systemaufrufe.
Tapsets lassen sich prima in eigene Skripte einbauen. Diese Templates liegen üblicherweise unterhalb von
»/usr/share/systemtap/tapsets«
. Neben diesen als synchron bekannten Events gibt es auch so genannte asynchrone Events. Sie sind nicht an ein bestimmtes Ereignis im Kernel- oder Programm-Code gebunden und kommen meist dann zum Einsatz, wenn man einen Header oder Footer für ein Skript bauen möchte. Sie sind auch geeignet, um gewisse Ereignisse wiederholt ausführen zu lassen.
Listing 5
zeigt ein einfaches Beispiel mit zwei Probes, jeweils mit einem asynchronen und einem synchronen Event. Ersteres gibt im 1-Sekunden-Intervall einen Header aus, das zweite ruft das vorgefertigte Tapset
»tcp.receive«
auf. Die Definition hierfür ist in
Listing 6
zu sehen. Das Beispiel verdeutlicht, dass der Einsatz von Tapsets die Komplexität der eigenen Skripte deutlich verringert.
Listing 6
Tapset tcp.stp
Listing 5
Tcpdump via Systemtap
Starten Sie das Skript aus
Listing 5
mit
»stap tcpdump.stp«
, dann sehen Sie die im 1-Sekunden-Intervall eintreffenden Netzwerkpakete mit einer Reihe weiterer Informationen. Wenn Sie die Angabe von
»timer.s(1)«
im ersten Event weglassen, erscheint der Header nur einmal vor der Ausgabe des ersten Netzwerkpakets.
Der Handler, auch als Body bezeichnet, unterstützt Anweisungen, wie sie aus vielen Programmiersprachen bekannt sind. So ist es beispielsweise möglich, Variablen und Arrays zu initialisieren, Funktionen aufzurufen oder Positionsparameter mittels
»$«
(Integer) oder
»@«
(String) abzufragen, natürlich fehlen auch Schleifen (While, Until, For, If/Else) nicht. Hiermit lässt sich auch die Ausgabe eines Skripts sehr genau steuern.
Anstatt wie bei Strace in einem Wust von Daten lange nach den gewünschten Informationen suchen zu müssen, sorgt der Benutzer in Systemtap beispielsweise dafür, dass Informationen erst dann ausgegeben werden, wenn ein gewisser Schwellenwert überschritten oder ein bestimmtes Ereignis (Event) eingetreten ist. Auch Filtermöglichkeiten existieren dank der umfangreichen Sprachkonstrukte zur Genüge.
Das
Listing 7
zeigt ein weiteres Beispiel mit dem schon bekannten Tapset
»vfs.read«
. Bei der globalen Variablen
»total«
handelt es sich in diesem Fall um ein assoziatives Array. Es enthält den Prozessnamen und die Prozess-ID sämtlicher Anwendungen, die auf das VFS-Subsystem zugreifen, um Daten von der Festplatte einzulesen. Für jeden Zugriff erhöht sich der Counter um eins.
Listing 7
I/O-intensive Anwendungen finden
Ist ein bestimmtes Userspace-Programm von Interesse, müssen Sie zuerst das entsprechende Debuginfo-Paket hierfür installieren. Der Einfachheit halber kommt in diesem Beispiel das Tool
»ls«
zum Einsatz. Zum Tracen ist das Paket
»coreutils-debuginfo«
erforderlich. Einen Überblick aller Funktionen eines bestimmten Prozesses liefert
»stap«
mit dem Aufruf aus
Listing 8
.
Listing 8
Userspace-Anwendung tracen
Listing 9
Parameter-Tracing
Cross Compiling
Wer das fertige Systemtap-Skript auf mehreren Systemen einsetzen möchte, will jedoch wahrscheinlich nicht auf allen den Compiler und die Debug-Informationen für den Kernel installieren. Das ist aber auch nur auf einem Build-System notwendig. Auf dem Zielsystem ist nur das RPM
»systemtap-runtime«
mit dem darin enthalten Programm
»staprun«
erforderlich. Der folgenden Befehl erzeugt ein fertig kompiliertes Kernelmodul für das Zielsystem:
stap -r kernel-PAE-2.6.31.12-174.2.22 capt-io.stp -m read-io
Auf dem Build-System ist dazu auch das Paket
»kernel-debuginfo«
in der Version des Zielsystems nötig. Build- und Target-System müssen außerdem die gleiche Hardware-Architektur besitzen. Das so erzeugte Kernelmodul kopieren Sie dann auf das Zielsystem und rufen es mit
»staprun«
auf:
staprun capt-io.ko
Sollen auch Nicht-Root-Benutzer die Berechtigung erhalten, dieses Modul zu laden, müssen sie Teil der Gruppe
»stapusr«
sein. Mitglieder von
»stapdev«
dürfen zudem eigene Skripte kompilieren.
Ähnliche Artikel
-
Ein Blick in den Linux-Kernel mit Systemtap

-
Neues bei Fedora 13, Teil 2: Systemtap
-
Systemtap 3.0 veröffentlicht
Systemtap vereint klassische Tracing- und Profiling-Tools wie Strace und Oprofile und bietet dabei eine einfache und leistungsfähige Schnittstelle für den Benutzer.
-
Fedora 18 als Server-Distribution

Konfigurationsmanagement

Themen


