Git-Tutorial: Leistungsfähige und einfache Versionsverwaltung

Code im Blick

Mit einer Versionsverwaltungs-Software verfolgen Sie die Geschichte Ihres Projekts Byte für Byte, und machen jede beliebige Änderung rückgängig, falls Sie sich doch anders entscheiden. Außerdem lassen sich mehrere Versionen oder Zweige innerhalb eines Projekts anlegen und verfolgen.
Projekte in der Software-Entwicklung nutzen immer eine Form von Versionskontrolle, und immer mehr von ihnen verwenden Git [1] . Das Tool wurde ursprünglich von Linus Torvalds für das Entwicklerteam des Linux-Kernels geschrieben, aber wegen seiner Flexibilität, Schnelligkeit und verteilten Struktur verbreitete es sich bei sehr vielen Projekten sehr schnell. Dieser Artikel zeigt Ihnen, wie Sie Git für die Erfassung einzelner Schritte in Ihrem Projekt erfolgreich anwenden.
Git ist auf hochverteilte, sehr schnelle und sehr flexible Leistung ausgelegt. "Hochverteilt" bedeutet in diesem Sinne, dass Git im Gegensatz zu anderen Versionsverwaltungssystemen, wie etwa CVS oder Subversion, eigentlich gar kein zentrales Repository benötigt. Stattdessen haben alle Repositories den gleichen Status, und jedes Repository kann mit jedem anderen verglichen und aktualisiert werden. Das prädestiniert Git für Projekte mit vielen kooperierenden Teilnehmern [2] .
Chaos im Griff
Eines der Hauptmerkmale von Git ist, dass es für die Unterstützung nicht linearer Entwicklungsarbeiten konzipiert wurde: Es geht davon aus, dass Änderungen immer wieder zusammengeführt werden, sobald sie von den verschiedenen Testern und Entwicklern eingereicht werden. Somit ist es ein Leichtes, Zweige zusammenzuführen oder sogar ganze Bäume, unabhängig davon, ob sie eine gemeinsame Vorversion haben. Im Gegensatz zu vielen anderen Versionskontrollsystemen ist es mit Git auch einfach, nicht versionierte Dateien in einen existierenden Baum einzubinden. Das macht es zum idealen Werkzeug für Projekte mit stark verteilter Entwicklung; aber wegen seiner beispiellosen Flexibilität auch für die heimische Verwendung.
Installieren Sie das Paket
»git-core«
unter Ubuntu/Debian und openSUSE/Fedora, um die Grundlagen zu erhalten; nützlich ist auch das Paket
»git-doc«
mit der Dokumentation. Verschiedene andere Pakete sind noch als Erweiterung erreichbar, wie
»git-svn«
, das die Subversion-Interoperabilität ermöglicht und
»gitweb«
, das ein Web-Interface zur Verfügung stellt. Alternativ installieren Sie Git direkt aus dem Quellcode
[3]
.
Haben Sie Git einmal installiert, erstellen Sie im Nu Ihr erstes Repository. Der dezentralisierte Charakter von Git zeigt sich darin, dass jede Arbeitskopie ihr eigenes Repository überall mit sich trägt (im
».git«
-Unterverzeichnis), anstatt wie bei CVS oder SVN ein zentrales Online-Repo zu pflegen.
Haben Sie ein bestehendes Verzeichnis, das Sie unter Versionskontrolle stellen wollen, ist der Vorgang äußerst einfach:
cd my_directory git init git add . git commit
Haben Sie Ihr von Git kontrolliertes Verzeichnis eingerichtet (
Abbildung 1
), legen Sie nun in der Konsole über
»touch
Datei
«
eine neue Datei an und tippen
»git status«
ein. Es erscheint eine Warnung, dass sich im Verzeichnis eine Datei befindet, deren Version noch nicht verfolgt wird. Sie fügen diese Datei mit
»git add
Datei
«
Git hinzu, und mit
»git commit«
übertragen Sie die Datei ins Repository. Daraufhin öffnet sich zuerst ein Texteditor, in dem Sie einen Kommentar zur gemachten Änderung hinterlegen müssen. Möchten Sie den Kommentar gleich mit übertragen, dann benutzen Sie dazu den Befehl
»git commit -m "
Kommentar
"«
. Sämtliche Anmerkungen speichert Git im Protokoll mit. Gewöhnen Sie es sich deshalb an, gute Kommentare zu schreiben, für den Fall, dass Sie später eine Änderung wieder rückgängig machen wollen.
 Abbildung 1: Einrichten eines Verzeichnisses als Git-Repository: schmerzlos!
Abbildung 1: Einrichten eines Verzeichnisses als Git-Repository: schmerzlos!
Mit folgenden zwei Befehlen fügen Sie alle bis jetzt noch nicht erfassten Dateien eines Verzeichnisses zu Git hinzu und übertragen Sie diese ins Repository:
git add . git commit -m "Anmerkungen"
Bearbeiten Sie nun eine der vorhandenen Dateien, und geben Sie dann den Befehl
»git status«
ein. Git zeigt dann diese Datei als "Changed but not updated" ("verändert, aber nicht aktualisiert") an. Im Gegensatz zu einigen anderen Systemen übernimmt Git keine Änderungen, bis Sie es dem Tool nicht ausdrücklich befehlen. Um alle bereits erfassten aber inzwischen geänderten Dateien dem Repository hinzuzufügen, benutzen Sie den Befehl
»git commit -am "Anmerkungen"«
; hierbei werden nur die bereits erfassten und verfolgten Dateien berücksichtigt, für die noch nicht erfassten Dateien müssen Sie immer
»git add .«
eingeben.
Ihre vorhin erstellte Test-Datei löschen Sie mit
»git rm
Datei
«
und dann
»git commit«
. Wurde die Datei aber seit der letzten Übergabe an das Repository geändert, erscheint eine Warnung. Um die Datei dennoch zu löschen, benutzen Sie
»git rm -f
Datei
«
.
Ob es in Ihrem Verzeichnis Dateien gibt, die von Git noch nicht erfasst wurden, erfahren Sie aus der Ausgabe von
»git status«
. Allerdings haben Sie möglicherweise einige Dateien in diesem Verzeichnis, die Sie nie hinzufügen möchten (Backup-Dateien oder temporäre Dateien). Normalerweise erscheinen diese auch in der Ausgabe von
»git status«
, da sie per
»git add .«
auch hinzugefügt wurden. Um dies zu vermeiden, erstellen Sie eine einfache Textdatei mit dem Namen
».gitignore«
in Ihrem Arbeitsverzeichnis. Listen Sie darin alle zu ignorierenden Dateien auf. Eine
».gitignore«
Datei sieht gewöhnlich etwa so aus:
.*.sw* tmp images
Mit diesen Einstellungen werden Dateien mit Namen wie
».myfile.swp«
(die temporären Dateien von Vim) sowie der Inhalt der Unterverzeichnisse
»tmp/«
und
»images/«
ignoriert.
Möchten Sie nun nach all diesen Experimenten, dass die Versionskontrolle dieses Verzeichnis nicht weiter verwaltet (sprich: es soll nicht länger als Git-Repository funktionieren), entfernen Sie einfach das
».git«
Unterverzeichnis mit
»rm -rf .git«
. Geben Sie jetzt den Befehl
»git status«
ein, dann erscheint eine Nachricht, dass dieses Verzeichnis kein Git-Repository ist.
Dieser Schritt ist so einfach, dass Sie nicht vergessen sollten, regelmäßig Backups des Git-Repositorys anzulegen!
Git konfigurieren
Früher oder später erhalten Sie bei den Arbeiten mit Git eine Warnmeldung, dass Ihr Name und Ihre E-Mail-Adresse fehlt. Sämtliche Commits in Git führen den Namen und die E-Mail-Adresse der Person, die den Code eingecheckt hat (Commiter). Git selbst versucht diese Informationen selbstständig herauszufinden, aber das geht in den meisten Fällen schief. Am besten nehmen Sie diese Einstellungen einmalig von Hand vor, wie es die folgenden Zeilen demonstrieren:
git config --global user.name Juliet Kemp git config --global user.email juliet@earth.li
So werden Sie nicht nur die lästige Warnmeldung los, sondern sind auch gleich für die Zukunft gerüstet. Die Angaben gelten für sämtliche Repositories, die Sie unter diesem Benutzernamen auf diesem Rechner vornehmen. Wenn Sie also einen Beitrag zu einem anderen Projekt leisten, das auch Git als Versionskontrolle benutzt, übermittelt Git auch diese Standardangaben. Die Angaben lassen sich für ein bestimmtes Repository auch ändern, wie in Listing 1 gezeigt.
Listing 1
Git-Konfiguration
Es sind auch noch zahlreiche andere Einstellungen möglich. Sie können zum Beispiel festlegen, dass Git in seiner
»diff«
-,
»status«
- und
»branch«
-Ausgabe verschiedene Farben verwendet (
Abbildung 2
):
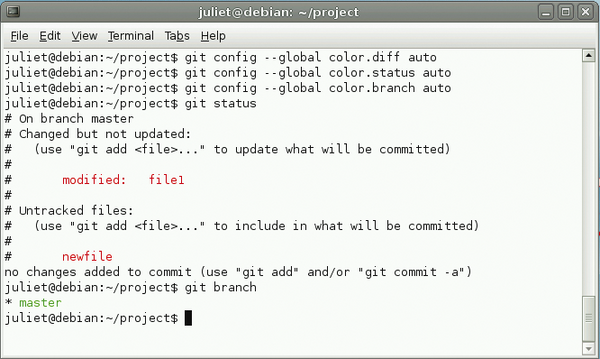 Abbildung 2: Die drei oberen Aufrufe stellen die farbige Ausgabe von "git status" und "git branch" ein, die weiter unten folgt.
Abbildung 2: Die drei oberen Aufrufe stellen die farbige Ausgabe von "git status" und "git branch" ein, die weiter unten folgt.
git config --global color.diff auto git config --global color.status auto git config --global color.branch auto
Für weitere Einstellungen lesen Sie das Handbuch [4] und das Git-Tutorial [5] .
Ähnliche Artikel




Konfigurationsmanagement

Themen


