I/O-Benchmarks mit Fio

Blockweise

Der Maintainer der Blockgeräte-Ebene des Linux-Kernels Jens Axboe entwickelte Fio, um die Performance in unterschiedlichen Anwendungsfällen zu messen. Einfache Benchmarks wie
»hdparm«
oder
»dd«
sind zu beschränkt und testen beispielsweise nur sequenzielles I/O, das in üblichen Workloads mit vielen kleinen Dateien keine große Rolle spielt. Für jeden Workload ein eigenes Testprogramm zu schreiben, ist indes ziemlich aufwendig.
Aktuell ist die Version 1.57. Für Debian gibt es ein vom Artikel-Autor erstelltes Paket, das Ubuntu-Entwickler in Ubuntu übernommen haben. Für Suse-Versionen ab SLES 9 sowie Open Suse 11.3 stellt das Benchmark-Repository ein aktuelles Paket bereit [1] .
In Fedora ist Fio ebenfalls enthalten. Die Quellen aus dem Tarball oder dem Git-Repository lassen sich mit den Entwicklerdateien zur
»libaio«
, bei Debian und Abkömmlingen als
»libaio-dev«
, bei RPM-basierten Distributionen üblicherweise als
»libaio-devel«
, mit einem simplen Make übersetzen
[2]
[3]
. Auch unter verschiedenen BSD-Varianten und Windows lässt sich Fio zum Laufen bringen, wie die Dokumentation erklärt.
Ein I/O-Workload besteht aus einem oder mehreren Jobs. Die Job-Definitionen nimmt Fio als Parameter auf der Befehlszeile oder als Job-Dateien in dem von Windows und KDE bekannten Ini-Format entgegen.
So richtet Fio mit dem einfachen Aufruf
fio --name=zufälliglesen --rw=randread--size=256m
den Job
»zufälliglesen«
ein und führt ihn aus: Fio erstellt dazu im aktuellen Verzeichnis eine Datei mit der Größe 256 MiB und einen Prozess für den Job. Dieser Prozess liest den gesamten Datei-Inhalt in zufälliger Abfolge. Fio führt dabei Buch über bereits gelesene Bereiche und liest jeden Bereich nur einmal. Währenddessen misst das Programm die CPU-Auslastung, die erzielte Bandbreite, die Anzahl der I/Os pro Sekunde und die Latenzen. Das Ganze funktioniert natürlich auch als Job-Datei:
[zufälliglesen] rw=randread size=256m
Von da aus lässt sich der Workload beliebig erweitern. So definiert
[global] rw=randread size=256m [zufälliglesen1] [zufälliglesen2]
zwei Jobs, die jeweils eine 256 MiB große Datei in zufälliger Reihenfolge einlesen. Alternativ erreicht die Option
»numjobs=2«
den gleichen Effekt.
Fio führt standardmäßig alle Jobs aus. Mit der Option
»stonewall«
wartet Fio, bis alle vorher laufenden Jobs fertig sind, bevor es weitermacht. So liest Fio mit
[global] rw=randread size=256m [zufälliglesen] [sequenzielllesen] stonewall rw=read
zunächst eine Datei zufällig und dann die zweite Datei sequenziell (
Abbildung 1
). Die Optionen in der Sektion
»global«
gelten dabei für alle Jobs und lassen sich pro Job abändern. Möchte man jeweils zwei Gruppen von zwei gleichzeitig laufenden Jobs hintereinander laufen lassen, muss die Option
»stonewall«
beim dritten Job stehen. Vor dem Ausführen einer Job-Gruppe verwirft Fio den Pagecache, wenn nicht
»invalidate=0«
gesetzt ist.
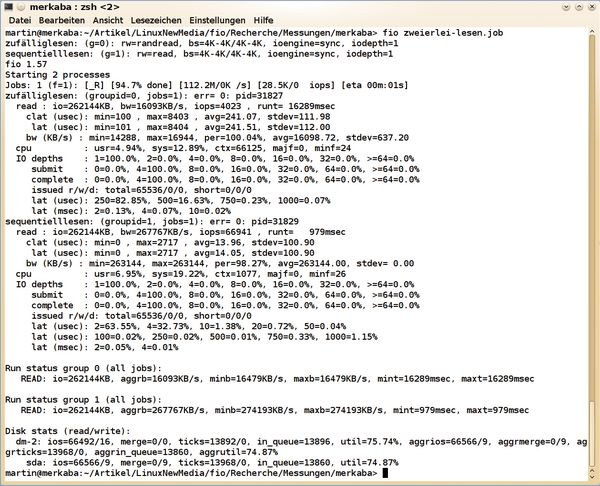 Abbildung 1: Ein einfacher Testlauf mit zwei Jobs, die Fio hintereinander durchführt.
Abbildung 1: Ein einfacher Testlauf mit zwei Jobs, die Fio hintereinander durchführt.
Während Fio den Workload ausführt, informiert es über seine Fortschritte:
Jobs: 1 (f=1): [rP] [64.7% done] [16948K/0K /s] [4137 /0 iops] [eta 00m:06s]
Im Beispiel läuft der erste Job mit sequenziellem Lesen, in den eckigen Klammern markiert als
»r«
, während Fio den zweiten noch nicht initialisiert hat, markiert als
»P«
. Der Buchstabe
»R«
steht für sequenzielles Lesen,
»w«
für zufälliges Schreiben,
»W«
für sequenzielles Schreiben und so weiter (siehe Manpage unter
»OUTPUT«
). Das Programm gibt zusätzlich den prozentualen Fortschritt der aktuellen Job-Gruppe, dann die aktuelle Lese- und Schreibgeschwindigkeit, die aktuellen Lese- und Schreib-IOPS sowie die voraussichtliche Dauer des Tests aus.
Sind alle Jobs fertig, präsentiert das Programm die Ergebnisse. Neben der erreichten Bandbreite und den IOPS zeigt Fio unter anderem die CPU-Auslastung und die Anzahl der Kontext-Switches. Im Abschnitt
»IO«
findet sich die prozentuale Verteilung, wie viele I/O-Requests Fio in Bearbeitung hatte (
»IO depths«
) und wie lange deren Abarbeitung dauerte (
»lat«
für Latenz).
Abbildung 1 zeigt die Ergebnisse eines Testlaufs auf einem ThinkPad T520 mit einer 300 GB Intel SSD 320 und dem Linux-Kernel 3.0. Bei Performance-Messungen empfiehlt es sich, vorher zu überlegen, was man misst, und dann nachzuprüfen, ob die Ergebnisse glaubwürdig sind.
Das Programm verwendete die Standard-Blockgröße von 4 KiB wie ganz am Anfang in der Ausgabe bei den Job-Gruppen zu sehen. Die etwa 16 000 KiB/s und 4000 I/O-Operationen pro Sekunde (IOPS) für zufälliges Lesen liegen im Rahmen des für eine SSD Möglichen (siehe Tabelle und Kasten IOPS-Richtwerte). Bei den über 65 000 IOPS und 260 MiB/Sekunde für sequenzielles Lesen hatten jedoch Readahead und Pagecache ihre Finger im Spiel.
IOPS-Richtwerte
Wie viele IOPS ein Laufwerk erreichen kann, richtet sich nach dessen Leistungsfähigkeit sowie dem definierten Workload. Der Schnittstellentyp wie SATA, SAS, Fibre Channel oder PCIe und der Controller üben ebenfalls einen Einfluss aus. In der Regel geht es darum, die Geschwindigkeit beim Arbeiten mit kleinen I/Os zu testen. Daher kommt typischerweise eine Blockgröße von 4 KiB zum Einsatz. In diesem Fall erreicht eine Festplatte mit 70 IOPS maximal eine Datentransferrate von 70 * 4 KiB also 280 KiB pro Sekunde – ein Wert, der deutlich unter der maximalen sequenziellen Datentransferrate bei großen Blockgrößen liegt. Die mittlere Zugriffszeit errechnet sich aus dem Kehrwert der IOPS und beträgt für die genannten 70 IOPS knapp 14,3 Millisekunden. Eine SSD braucht bei 4000 IOPS circa 0,25 Milli- oder 250 Mikrosekunden (siehe Abbildung 1 ).
Einige Messwerte für Festplatten, SSDs und das PCIe-Flash Fusion ioDrive finden sich unter [4] und [5] . Bei Festplatten setzt sich die mittlere Zugriffszeit aus der Spurwechselzeit (seek time) und der durchschnittlichen Latenz, also der Dauer einer halben Umdrehung der Festplatte [6] zusammen. Bei kleinen I/O-Größen ist die Datenübertragungsrate in der Regel vernachlässigbar, ebenso wie der Controller-Overhead.
Motorenvielfalt
Wie Fio die I/O-Operationen durchführt, hängt davon ab, welche I/O-Engine es mit welchen Einstellungen verwendet. Einen Überblick über die vielen beteiligten Komponenten gibt
Abbildung 2
. Mehrere Anwendungen lesen und schreiben Daten, indem sie mit einem oder mehreren Prozessen und etwaigen Threads System-Funktionen aufrufen. Die System-Routinen verwenden oder umgehen je nach Parameter den Pagecache. Zugriffe auf Dateien setzt ein Dateisystem in Zugriffe auf Blöcke um, während systemnahe Programme wie
»dd«
, der Linux-Kernel beim Auslagern auf ein Swap-Gerät sowie entsprechend konfigurierte Anwendungen wie einige Datenbanken oder der Newsfeeder/Reader Diablo direkt auf Blockgeräte schreiben
[7]
. Im Block Layer gibt der gerade laufende I/O-Scheduler die Requests nach festgelegten Regeln an die Gerätetreiber weiter. Der Controller schließlich spricht das Gerät an, das ebenfalls einen mehr oder weniger aufwendigen Controller mit eigener Firmware besitzt.
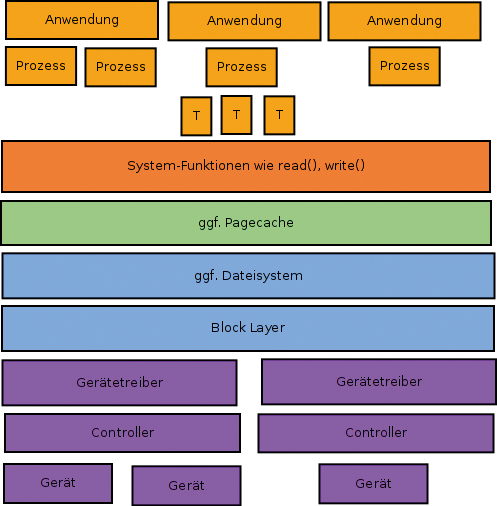 Abbildung 2: Viele Ebenen spielen ineinander, um Daten zu lesen und zu speichern.
Abbildung 2: Viele Ebenen spielen ineinander, um Daten zu lesen und zu speichern.
Für Ergebnisse von Performance-Messungen ist es ausschlaggebend, ob Requests asynchron oder synchron verarbeitet werden. Auch die Länge der Request-Warteschlange sowie der Einsatz oder das Überspringen des Pagecaches sind bedeutsam. Allerdings gibt es asynchrones und synchrones Verhalten sowie Warteschlangen sowohl auf der Anwendungsebene als auch auf der Geräte-Ebene.
So arbeitet die in den bisherigen Beispielen verwendete I/O-Engine
»sync«
, die die Systemfunktionen
»read«
,
»write«
und gegebenenfalls
»lseek«
verwendet, auf Anwendungsebene synchron, ebenso wie
»psync«
und
»vsync«
: Der Aufruf der Funktion kehrt erst zurück, wenn die Daten gelesen oder zum Schreiben im Pagecache gelandet sind. Daher ist die Länge der Warteschlange auf Anwendungsebene immer eins. Solange der Prozess aber nicht zu viele Daten auf einmal schreibt, landen diese erst einmal nicht auf der Platte (
Abbildung 3
). Der Kernel sammelt sie im Pagecache und schreibt sie auf Geräte-Ebene später doch asynchron.
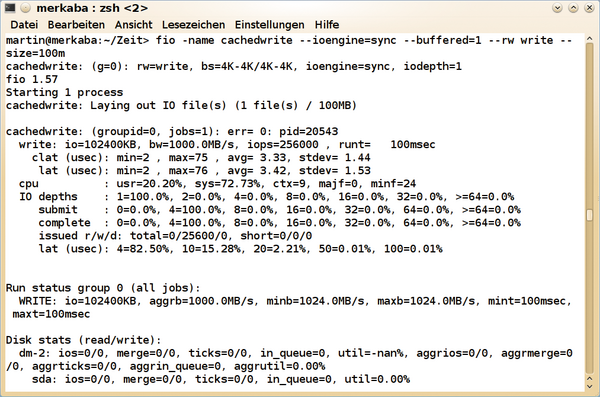 Abbildung 3: Knapp 1 GiB/s und 256000 IOPS sind auch für eine Intel SSD 320 unrealistisch.
Abbildung 3: Knapp 1 GiB/s und 256000 IOPS sind auch für eine Intel SSD 320 unrealistisch.
Das Lesen geschieht bei den synchronen Engines auch auf Geräte-Ebene synchron, es sei denn, mehrere Prozesse lesen gleichzeitig. Das ist dann aber nicht so effizient wie asynchrones I/O auf der Anwendungsebene. Wer den Pagecache umgehen und damit das Gerät selbst messen möchte, verwendet die Option
»direct=1«
. Auf Geräte-Ebene synchrones und damit unrealistisch langsames Arbeiten aktiviert die Option
»sync=1«
, die bei den meisten Engines der Funktion
»open()«
das Flag
»O_SYNC«
übergibt. Dann kehrt der System-Aufruf erst zurück, wenn die Daten auf dem Laufwerk sind.
Auf der Anwendungsebene asynchron arbeiten unter anderem die Engines
»libaio«
,
»posixio«
,
»windowsaio«
und
»solarisaio«
[8]
. Mit asynchronen I/Os setzt die Anwendung mehrere Requests ab, ohne auf jeden einzelnen Request zu warten. So rechnet sie mitunter mit bereits erhaltenen Daten, während weitere Requests in Bearbeitung (pending) sind. Wie viele Requests Fio maximal in Bearbeitung hält, kontrolliert die Option
»iodepth«
, wie viele das Programm auf einmal losschickt
»iodepth_batch«
und
»iodepth_batch_complete«
. Allerdings funktioniert dies unter Linux nur mit direktem I/O, also unter Umgehung des Pagecaches. Gepuffertes I/O ist unter Linux auf Anwendungsebene immer synchron. Zudem funktioniert direktes I/O nur mit einem Vielfachen der Sektorgröße als Blockgröße.
So ergibt der Job in Listing 1 deutlich weniger Bandbreite und IOPS für das sequenzielle Lesen Werte, die näher an den tatsächlichen Fähigkeiten des Laufwerks liegen (siehe Abbildung 4 ). Da die meisten Anwendungen auf die Vorzüge gepufferten I/Os zurückgreifen, machen Tests, die den Pagecache einbeziehen, durchaus Sinn. Für solche ist jedoch eine große Datenmenge von mindestens zweimal der RAM-Größe empfehlenswert. Ohnehin ist es sinnvoll, eine Messung mindestens dreimal durchzuführen und nach Abweichungen zu schauen.
Listing 1
Synchrones I/O
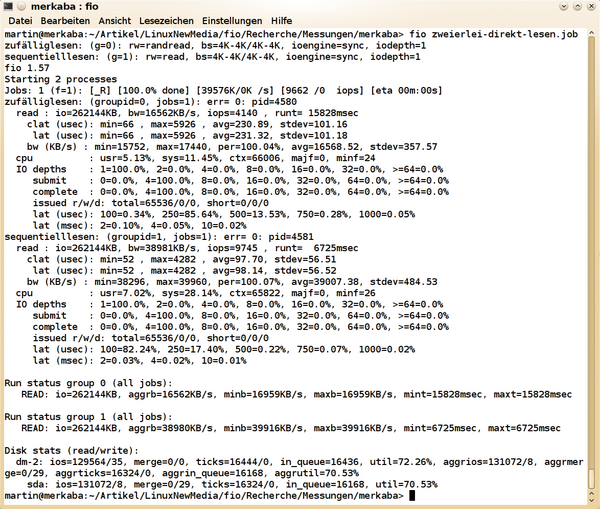 Abbildung 4: Direktes I/O unter Umgehung des Pagecache liegt näher an den tatsächlichen Fähigkeiten des Laufwerks.
Abbildung 4: Direktes I/O unter Umgehung des Pagecache liegt näher an den tatsächlichen Fähigkeiten des Laufwerks.
Durch die Angabe eines Dateinamens im allgemeinen Bereich verwenden beide Tests die gleiche Datei. Durch Jobs erstellte Dateien löscht Fio nicht. Das Programm füllt solche Dateien mit Nullen. Für Festplatten ist das in der Regel okay. In Zusammenhang mit Dateisystemen oder SSDs, die komprimieren, wie etwa SSDs mit neuerem Sandforce-Chipsatz oder BTRFS mit der entsprechenden Mount-Option, misst Fio so jedoch, wie effizient der Komprimier-Algorithmus Nullen zusammenfasst. Für zufällige Daten sorgt entweder das vorherige Anlegen der Datei mit
»dd«
aus
»/dev/urandom«
oder das vorherige Schreiben in die Datei mit Fio selbst. Die Option
»refill_buffers«
weist Fio an, den Schreibpuffer nicht nur einmal, sondern jedes Mal mit neuen zufälligen Daten zu füllen (
Listing 2
).
Listing 2
Puffer neu füllen
Die sequenzielle Transferrate bei großen Blöcken protokolliert Fio mit der Option
»write_bw_log«
in
»schreiben_bw.log«
oder
»lesen_bw.log«
, so lange man kein anderes Präfix angibt. Aus den Protokollen im aktuellen Verzeichnis erstellt das kleine Skript
»fio_generate_plots«
einen Graphen (
Abbildung 5
). Als Argumente nimmt es einen Titel und in der aktuellen Git-Fassung auch die Auflösung entgegen. Dieser Workload erreicht mit 54 großen IOPS beim Schreiben ungefähr 220 MiB/s und mit 68 IOPS beim Lesen circa 280 MiB/s und liegt damit nur knapp unter dem theoretischem Limit für eine SATA-300-Schnittstelle. Wichtig: Trotz 20 GBytes pro Tag für minimal 5 Jahre bei einer Intel SSD 320 ist es empfehlenswert, mit SSD-Schreibtests achtsam zu sein und die SSD mithilfe des
»fstrim«
-Befehls aus einem aktuellen
»util-linux«
-Paket zu entlasten
[9]
.
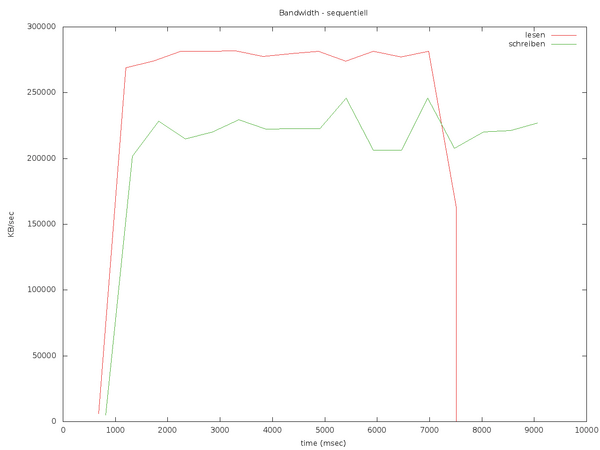 Abbildung 5: Ein kleines Skript erstellt Graphen aus Bandbreiten- oder Latenz-Protokollen.
Abbildung 5: Ein kleines Skript erstellt Graphen aus Bandbreiten- oder Latenz-Protokollen.
Der Workload aus
Listing 3
zum Messen der IOPS mit einer variablen Blockgröße von 2 bis 16 KiB verwendet die zuvor angelegte Datei weiter (
Abbildung 6
). Am Leistungslimit ist die SSD damit jedoch noch nicht, wie die 68 beziehungsweise 67 Prozent für
»util«
für das logische Laufwerk und die SSD selbst aussagen. Beim sequenziellen Workload lag die Auslastung bei 97 Prozent. Die maximale Laufzeit von 60 Sekunden unterschreitet die SSD bei einer 2 GiB großen Datei dennoch bei einigen Tests.
Listing 3
Variable Blockgrößen
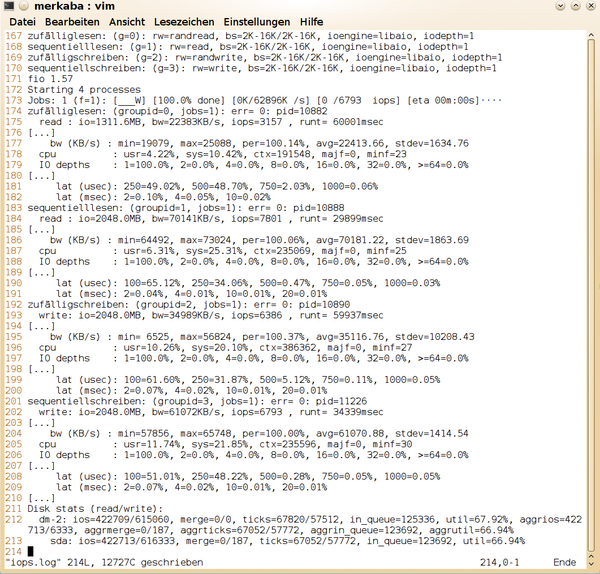 Abbildung 6: Das mit einer Warteschlangenlänge von eins quasi synchrone I/O lastet die Intel SSD nur zu etwa 67 Prozent aus.
Abbildung 6: Das mit einer Warteschlangenlänge von eins quasi synchrone I/O lastet die Intel SSD nur zu etwa 67 Prozent aus.
Mit einer Warteschlangenlänge von eins wartet auch die I/O-Engine
»libaio«
auf jeden Request, bevor sie den nächsten abschließt. Das lastet bei kleinen Blockgrößen die Warteschlange auf Geräte-Ebene nicht aus. Die SSD unterstützt Native Command Queuing mit bis zu 32 Requests:
$ hdparm -I /dev/sda | grep -i queue Queue depth: 32 * Native Command Queueing (NCQ)
Um immer noch ein paar zusätzliche Requests in Bearbeitung zu haben, empfiehlt sich ein Versuch mit der doppelten Anzahl. Mit
»iodepth=64«
steigt die Performance erheblich, Kernel und SSD-Firmware haben bei längeren Warteschlangen mehr Spielraum für Optimierungen (siehe
Abbildung 7
). Allerdings braucht die SSD durchschnittlich auch deutlich länger, um Requests zu beantworten.
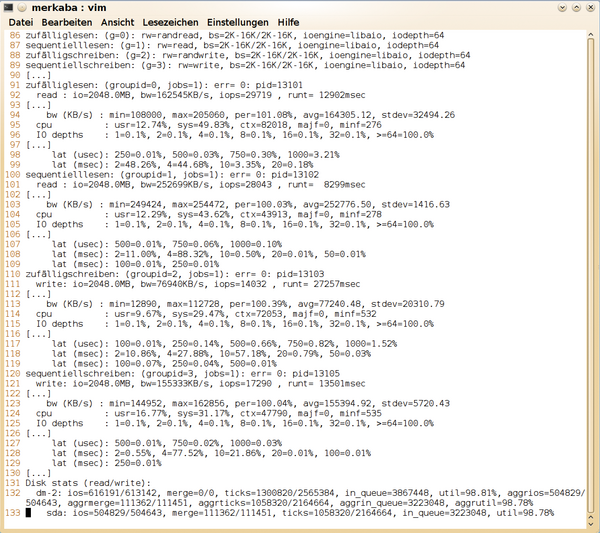 Abbildung 7: Hält Fio bis zu 64 Requests gleichzeitig in Bearbeitung, steigen Auslastung und Latenz.
Abbildung 7: Hält Fio bis zu 64 Requests gleichzeitig in Bearbeitung, steigen Auslastung und Latenz.
Da der Kernel auch mit synchronen I/O auf Anwendungsebene beim gepufferten Schreiben vieler Daten oder beim gleichzeitigen Lesen und Schreiben durch viele Prozesse auf Geräte-Ebene ebenfalls viele Requests in Bearbeitung hält, macht es durchaus Sinn, mit verschiedenen Warteschlangenlängen zu testen. Eine einfache Möglichkeit ist es, in der Job-Datei
»iodepth=$IODEPTH«
zu schreiben und Fio die Länge als Umgebungsvariable mitzuteilen.
Variation
Eine anderer Weg ist, mit vielen Prozessen gleichzeitig zu testen oder viele Daten gepuffert zu schreiben. So liefert ein Test mit
»numjobs=64«
ebenfalls deutlich höhere Werte, die die Option
»group_reporting«
pro Gruppe zusammenfasst. Die Befehlszeilen-Option
»--eta=never«
schaltet die überlange Fortschrittsanzeige ab. Hohe Latenzen bei der Reaktion auf Benutzereingaben selbst auf einem Intel Sandybridge i5 Dualcore und etwa 770 000 Kontext-Switches zeigen den höheren Overhead dieser Methode. Doch immerhin sind auch damit circa 160 bis 180 MB/s und 18 000 bis 19 000 IOPS beim Lesen und ungefähr 110 MiB/s und 12500 IOPS beim Schreiben drin. Die Messprotokolle stehen auf der ADMIN-Website zum Download bereit.
Damit sind die Möglichkeiten von Fio noch lange nicht ausgeschöpft. Das Programm arbeitet auch direkt mit der Hardware, wie der Beispiel-Job
»disk-zone-profile«
zeigt, der über die gesamte Größe eines Laufwerks in Abständen die Lese-Transferrate misst. Für hardwarenahe, realistische Messungen ist es bei Festplatten empfehlenswert, immer das ganze Laufwerk zu verwenden, da die Transferrate bei den außen liegenden Sektoren aufgrund des größeren Zylinderumfangs höher ist. So ergeben sich bei einer 2,5-Zoll-Hitachi-Platte mit 500 GByte via eSATA beim zufälligen Lesen von 2 bis 16 KiB-Blöcken mit
»iodepth=1«
noch etwa 50 IOPS (
Abbildung 8
). Alternativ verwendet man nur den Anfang der Platte. Bei Lese-Tests mit ganzen Laufwerken, die wertvolle Daten enthalten, bietet die Befehlszeilen-Option
»--readonly«
zusätzliche Sicherheit.
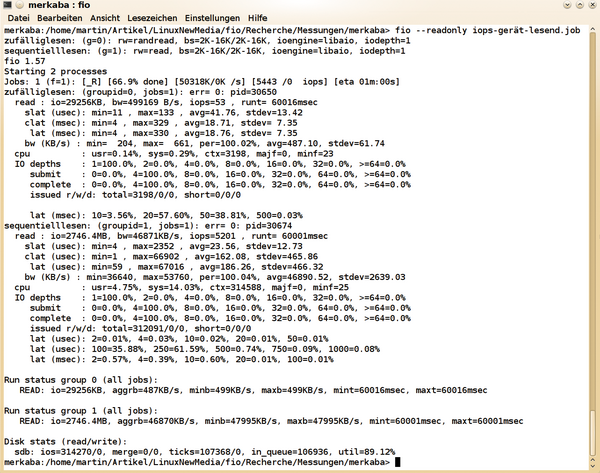 Abbildung 8: Eine 2,5-Zoll-Festplatte via eSATA schafft deutlich weniger IOPS als eine SSD.
Abbildung 8: Eine 2,5-Zoll-Festplatte via eSATA schafft deutlich weniger IOPS als eine SSD.
Weiterhin simuliert Fio mit der Engine
»mmap«
Workloads, die Dateien in den Speicher einblenden, während
»net«
mit
»filename=host/port«
Daten über
»TCP/IP«
sendet oder empfängt und
»cpuio«
CPU-Zeit verbraucht. Zudem verwenden die Engines
»splice«
und
»netsplice«
die linux-spezifischen Kernel-Funktionen
»splice()«
und
»vmsplice()«
, um Kopien von Pages zwischen User- und Kernelspace zu vermeiden (Zero Copy). Auf
»splice()«
greift die Funktion
»sendfile()«
zurück, die zum Beispiel der Webserver Apache verwendet, um statische Dateien schneller auszuliefern.
Auch typische Workloads mit vielen gepufferten, asynchronen Schreibzugriffen und mehr oder weniger
»fsync«
-Aufrufen lassen sich mit den Optionen
»fsync«
,
»fdatasync«
oder gar
»sync_file_range«
simulieren. Gemischte Workloads mit einstellbaren Gewichtungen zwischen Lesen und Schreiben sowie zwischen unterschiedlichen Blockgrößen unterstützt Fio ebenfalls. Ein Blick in die Manpage und das Howto offenbart die ganze Funktionsvielfalt.
So sehr Workload und Test-Setup gemessene Performance-Werte beeinflussen, so individuell sind auch die Tuning-Möglichkeiten. Allgemein gilt die Regel: Use the defaults [10] – verwende die Standardwerte, so lange es keinen Grund gibt, daran etwas zu ändern. Denn erfahrungsgemäß bringt ein einfaches Drehen an Optionen oft nur wenige Prozent und reduziert mitunter sogar die Performance.
Die sinnvollen Maßnahmen hängen auch von der Intelligenz des Storage ab. Bei einem intelligenten und selbst puffernden SAN-System empfiehlt es sich, die Intelligenz im Linux zu reduzieren. Der I/O-Scheduler
»noop«
, durchaus auch für SSDs sinnvoll, erspart dem Kernel das möglicherweise gar nicht zu den Algorithmen im SAN-System passende Umsortieren von Requests (siehe dazu das Verzeichnis
»/sys/block/
Gerät
/queue«
). Bei Readahead im SAN ist es mitunter sinnvoll, mit
»blockdev -setra«
das Readahead auf Linux-Seite zu reduzieren, jedoch die Länge der Warteschlange zum SAN hin
»find /sys -name "*queue_depth*"«
) zu vergrößern, so weit das SAN mit der akkumulierten Wartenschlange aller Clients zurechtkommt.
Es ist sinnvoll, Partitionen und Dateisysteme an SANs, RAIDs, SSDs und Festplatten mit 4-KiB-Sektoren, die alle mit größeren Datenblöcken als 512 Byte arbeiten, auszurichten. Hier sind dann durchaus auch mal Geschwindigkeits-Zuwächse im zweistelligen Prozentbereich drin. Neuere Versionen von
»fdisk«
richten sich mit
»-c«
automatisch an 1-MiB-Grenzen aus. Das ist ein guter Standardwert, da es sich durch übliche Werte wie 4, 64, 128 und 512 KiB teilen lässt. So verwendet
»mdadm«
mittlerweile eine Chunksize von 512 KiB, frühere Versionen und Hardware-RAIDs oft 64 KiB. Gängige Dateisysteme wie Ext3 und 4 sowie XFS unterstützten entsprechende Parameter in ihren Mkfs- und Mount-Optionen. Für Dateisysteme gilt: Die Standardwerte aktueller Mkfs-Versionen bringen häufig die besten Ergebnisse. Das komplette Ausschalten der Atime-Aktualisierung via Mount-Option
»noatime«
reduziert Schreibvorgänge gegenüber
»relatime«
mitunter spürbar
[11]
.
Ähnliche Artikel





Konfigurationsmanagement

Themen


