
Wurzelspaltung
Lehman und Yao sind von uniquen Indexen ausgegangen. Aber nicht alle Indexe sind unique. Ein Wert kann in einem Index mehrfach vorkommen. Es können mehrere Pages Einträge für den gleichen Wert haben. PostgreSQL hat daher die Lehman-Yao-Formel Schlüssel < Wert <= nächster Schlüssel abgewandelt in Schlüssel <= Wert <= nächster Schlüssel. Wie ein nicht-uniquer Indexbaum aussehen könnte, zeigt Abbildung 2 .
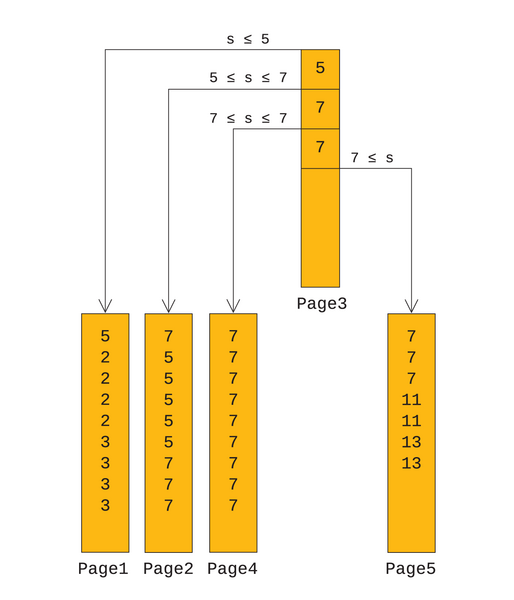 Abbildung 2: So könnte ein nicht-uniquer Indexbaum aussehen.
Abbildung 2: So könnte ein nicht-uniquer Indexbaum aussehen.
Daneben haben Lehman und Yao nicht ursprünglich vorgesehen, dass die Wurzel geteilt werden müsste. Beim Teilen der Wurzel beziehungsweise der inneren Knoten verfährt PostgreSQL genauso wie beim Teilen der Blätter.
Werden Datensätze in die Tabelle eingefügt oder geändert, so schaut PostgreSQL im Index nach, an welche Stelle die neuen Werte eingefügt werden müssten. Ist dort noch Platz, wird der Wert dort eingefügt. Ist dort kein Platz, wird das Blatt geteilt und die inneren Knoten bei Bedarf bis hin zur Wurzel entsprechend angepasst. Muss aufgrund der Einfügung auch die Wurzel oder ein innerer Knoten geteilt werden, so wird auch das erledigt. Aufgrund von MVCC muss hierbei jedoch sichergestellt werden, dass der Baum nicht inkonsistent wird. Daher kommen diese Aktionen nicht um Locking herum. Für eine Teilung werden neben den beteiligten Pages auch die linken und die rechten Nachbarinnen der Pages gelockt.
Damit nicht bei jedem Einfügen eine Teilung passiert, werden Pages, die neu hinzukommen, maximal nur bis zu einem bestimmten Prozentwert gefüllt. Die Wurzel, und die inneren Knoten werden bei ihrer Erzeugung maximal bis 70 Prozent gefüllt, die Blätter per Default zu 90 Prozent. Der maximale initiale Füllfaktor der Blätter lässt sich für jeden Index einstellen:
CREATE INDEX ... ON ... WITH (FILLFACTOR = Wert); ALTER INDEX ... SET (FILLFACTOR = Wert);
Das passiert beim Löschen
Werden Datensätze aus der Tabelle gelöscht oder geändert, so werden die alten Daten erst im Index und dann in der Tabelle für tot erklärt. Genauso wie bei Tabellen werden die Tupel erst nach einem
»VACUUM«
entfernt. Wird auf diese Weise eine komplette Index-Page geleert, so entfernt
»VACUUM«
den Link vom inneren Knoten beziehungsweise der Wurzel, ändert den Höchstwert der linken Nachbarin auf den ersten Eintrag der rechten Nachbarin und erzählt ihr, wer ihre neue rechte Nachbarin ist. Danach setzt es den Schlüssel im Knoten auf den neuen Höchstwert der Nachbarin und erzählt auch noch der rechten Nachbarin, wer ihre neue linke Nachbarin ist.
Abbildung 3
zeigt, wie der Index aus
Abbildung 2
nach Löschen der Sieben und nach Ausführung von
»VACUUM«
aussehen könnte.
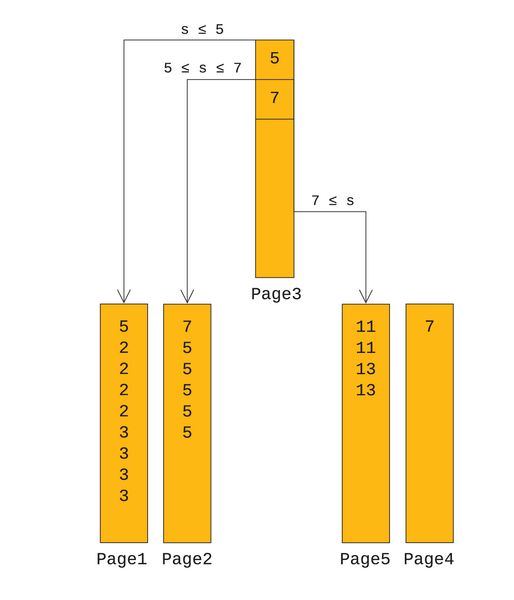 Abbildung 3: So könnte der Index aus
Abbildung 3: So könnte der Index aus
Die gelöschte Indexpage kann aus verschiedenen MVCC-Gründen nicht sofort wiederverwendet werden. Daneben muss für die Wiederverwendung der Page auch erst einmal sichergestellt sein, dass die Werte auch aus der Tabelle entfernt wurden. Egal, ob in der Mitte oder rechts außen Werte dazukommen, ein einzelnes
»VACUUM«
reicht nicht aus, damit die Page wiederverwendet wird. Stattdessen werden bei Bedarf neue Pages alloziert. Erst nach einem zweiten
»VACUUM«
wird auch die gelöschte Page wieder mit eingebunden.
Da die Rechts-außen-Page niemals gelöscht wird, wird ein Index-Baum nie kleiner. Stattdessen führen Pages, die nach
»VACUUM«
nicht sofort wieder genutzt werden und viele Pages, die geteilt werden mussten, dazu, dass sich der Index aufblähen kann. Gerade bei Tabellen in denen viele Änderungen passieren, kann er schnell wachsen und viel ungenutzten Speicherplatz beinhalten.
Zur Demonstration wird eine Tabelle mit zehntausend Datensätzen angelegt und eine Spalte mit drei Indexen versehen. Einer mit Default-Fillfactor (90 Prozent) einer mit Fillfactor 100 und einer mit Fillfactor 50.
relname | relpages | reltuples ------------------+----------+----------- t_tabelle | 45 | 10000 index_ff_50 | 52 | 10000 index_ff_100 | 27 | 10000 index_ff_default | 30 | 10000
Anschließend werden diverse
»DELETE«
,
»UPDATE«
und
»INSERT«
und zwischendurch immer wieder
»VACUUM«
auf der Tabelle ausgeführt:
relname | relpages | reltuples ------------------+----------+----------- t_tabelle | 87 | 19457 index_ff_50 | 125 | 19457 index_ff_100 | 88 | 19457 index_ff_default | 71 | 19457
Die Tabelle enthält jetzt fast doppelt so viele Datensätze wie vorher. Sie nimmt etwas weniger als das Doppelte an Speicherplatz ein. Der fünfzigprozentige-Index dagegen ist ungefähr um das 2,4-Fache und der hundertprozentige fast um das Dreifache angewachsen. Der Default-Index nimmt jetzt 2,3-mal so viel Platz ein. Jeder der Indexe beansprucht jetzt schon mehr Speicherplatz als eigentlich nötig wäre. Die Indexe haben begonnen, aus dem Ruder zu laufen. Je stärker dieser Effekt ist, desto ineffektiver wird der Index.
Um Werte anhand des Index zu finden, aber auch um die Stelle zu finden, wo eingefügt, geändert oder gelöscht werden soll, muss der Index-Baum ab der Wurzel nach den entsprechenden Blättern suchen. Indexe müssen nicht unique sein. Es können viele Pages den gleichen Wert enthalten. Jede Page, die den Wert enthält, muss eingesehen werden. Eine Vielzahl von Pages zu durchlaufen, die immer nur zur Hälfte gefüllt sind, ist weniger effektiv als gut gefüllte Pages zu durchsuchen. Das Wachstum von Indexen sollte daher im Auge behalten werden. Wenn das Verhältnis zwischen Wachstum des Indexes und Wachstum der Tabelle aus dem Ruder läuft, empfiehlt es sich zu reagieren.
Ähnliche Artikel
-
Speicherplatz für PostgreSQL-Tabellen richtig nutzen

-
PostgreSQL 13 veröffentlicht

Die führende Open-Source-SQL-Datenbank ist in einer neuen Version erschienen: PostgreSQL 13 kommt vor allem mit neuen Features, welche die Performance verbessern.
-
Überblick zu PostgreSQL 14.4

-
Systeme: PostgreSQL 9.4

-
PostgreSQL 9.4 veröffentlicht

Die lange erwartete PostgreSQL-Version mit besserem JSON-Support und neuen Replikationsmechanismen wurde jetzt freigegeben.
Konfigurationsmanagement

Themen


