Programmieren mit Go

Kanalisiert

Der Workshop
in der letzten ADMIN-Ausgabe
hat vorgeführt, wie man mit wenigen Zeilen Go-Code ein kleines Programm schreibt, das unter Linux die laufenden Prozesse auflistet
[1]
. Die Funktionalität ist rudimentär, aber das Projekt hat gezeigt, wie man mit Go auf Dateien und Verzeichnisse zugreift, Unicode verarbeitet sowie Schleifen und Funktionen verwendet. Verbesserungsmöglichkeiten gibt es noch viele, aber es ist nicht übermäßig sinnvoll, die Funktionalität des Linux-eigenen
»ps«
bis ins Letzte nachzuprogrammieren.
In der letzten Version hat das Beispielprogramm
»lap«
für jeden Prozess aus der UID den Benutzernamen über die Funktion
»user.LookupId()«
der Go-Standardbibliothek ermittelt. Weil typischerweise jeder Benutzer eine Reihe von Prozessen besitzt, kommt es hier zu einer Menge unnötiger Lookups. Je nachdem, wie das Betriebssystem die dafür nötige Funktion
»getpwuid()«
implementiert, führt das wiederum zu vielen Zugriffen auf das Dateisystem. Deshalb ist hier ein Cache sinnvoll, der die Zuordnung von der UID zum Benutzernamen speichert und für den sich eine Map als Datenstruktur anbietet. Das Go-Keyword hierfür lautet
»map«
, wobei der Schlüssel in eckigen Klammern steht, gefolgt vom Wert. Das Builtin
»make«
initialisiert die Map und reserviert initial etwas Speicherplatz:
var usermap map[string]string usermap = make(map[string]string)
Um die Map als Cache für den Benutzer-Lookup zu verwenden, überprüft man zuerst, ob sich der gesuchte Wert schon in der Map befindet. Fehlt er, schlägt die Funktion
»user.LookupId()«
ihn nach und speichert ihn fürs nächste Mal in der Map. Etwas ungewöhnlich gestaltet sich die Überprüfung, ob der Wert schon in der Map steckt. Es gibt nämlich keine spezielle Funktion dafür wie in anderen Programmiersprachen (etwa
»hasKey()«
), sondern man versucht den Wert direkt auszulesen und überprüft dann den gleichzeitig zurückgegebenen Fehlercode. Packt man den Aufruf in eine If-Abfrage, geht das in einer Zeile, und man hat anschließend gleich den Wert aus der Map, wenn es ihn gibt:
if val, ok := mymap[key]; ok {
...
Hier wird der Variablen
»val«
der Hash-Wert zugewiesen (sofern vorhanden) und
»ok«
der Error-Code, den die If-Abfrage nach dem Semikolon prüft. Diese Kombination von Zuweisung und Bedingung ist typisch für Go-Code und wird als "comma ok"-Idiom bezeichnet. Der komplette Code-Abschnitt für das
»lap«
-Tool ist in
Listing 1
zu sehen. Weiteres Optimierungspotenzial birgt das Auslesen der Proc-Dateien, das beim aktuellen Entwicklungsstand des Tools noch sequenziell abläuft. Prinzipiell sind solche Annahmen mit Vorsicht zu genießen: Man sollte vor jeder Optimierung erst mit einem Profiler oder anderen Tools untersuchen, in welchen Abschnitten ein Programm wirklich viel Zeit verbringt. So würde die Parallelisierung von Dateizugriffen im Normalfall wohl kaum zu einer Beschleunigung führen, weil der Massenspeicher (etwa eine Festplatte) dann der Flaschenhals wäre. Unter Umständen kann es sogar zu einer Verschlechterung der Performance kommen, wenn durch unbedachte Parallelisierung vorhandene Cache-Effekte zunichte gemacht werden.
Listing 1
usermap
Virtuelle Dateien
Im Beispielfall ist die Situation ein bisschen anders, weil es sich bei den Proc-Dateien nur um virtuelle Files handelt, die der Kernel zur Verfügung stellt, also ist die Parallelisierung nicht vollkommen sinnlos. Riesige Performance-Gewinne lassen sich hier im Normalfall dennoch nicht erzielen, da die Prozessliste nicht besonders lang ist, aber der Fall taugt als Beispiel für die parallele Verarbeitung in Go.
Zur parallelen Verarbeitung von Aufgaben bietet Go mit den Goroutinen ein eigenes Konstrukt an, das ein Zwischending zwischen Thread und Prozess darstellt. Eine Goroutine teilt den Speicher und damit die Variablen mit dem Hauptprogramm und gegebenenfalls anderen Goroutinen, was die Kommunikation vereinfacht. Goroutinen sind leichter zu handhaben als Threads, somit weniger fehleranfällig zu programmieren und verbrauchen auch noch weniger Ressourcen. Im einfachsten Fall ist nichts anderes zu tun, als dem Aufruf einer Funktion ein
»go«
voranzustellen:
go doSomeThing();
Damit führt das Programm die Funktion
»doSomeThing()«
in einer Goroutine aus und fährt mit der Ausführung fort. Wer in einer Goroutine Text ausgibt, bekommt davon eventuell nichts zu sehen, weil das Hauptprogramm vorher fertig ist. Das ist natürlich nicht im Sinne der Erfinder, die deshalb auch Synchronisationsmöglichkeiten vorgesehen haben.
Es gibt die bekannten Mutex-Locks und Waitgroups, aber der einfachste und passendste Mechanismus zur Synchronisation von Goroutinen sind Channels, die ähnlich funktionieren wie Unix-Pipes und zur Kommunikation zwischen Goroutinen vorgesehen sind. Buffered Channels blockieren bei Lese- und Schreiboperationen nicht (solange noch Platz ist), ungepufferte Channels aber schon, weshalb sie sich zur Synchronisation eignen. Ein Beispiel ist in Listing 2 zu sehen.
Listing 2
Channels
Die Main-Funktion erzeugt mit
»make«
einen Channel für Integer-Werte, der in der folgenden Zeile an die Funktion
»sayHello()«
übergeben wird. Weil die Funktion mit
»go«
als Goroutine aufgerufen wird, fährt die Main-Funktion mit der Verarbeitung fort. Das nun folgende Statement
»<-c«
liest aus dem Channel und blockiert, weil es derzeit nichts zu lesen gibt. In der Zwischenzeit verarbeitet die aufgerufene Funktion das Printf-Statement und schreibt den Wert 1 in den Channel. Nun macht auch das Hauptprogramm weiter, weil es aus dem Channel lesen kann. In diesem Beispiel dient der Channel nur der Synchronisation, die darüber mitgeteilten Werte spielen also keine weitere Rolle.
Meistens ist es sinnvoller, über Channels gleich Daten zwischen Goroutinen untereinander mit mit der Main-Funktion auszutauschen. Welcher Art diese Daten sind, bestimmt der deklarierte Typ des Channels. Für das
»lap«
bietet es sich an, in dem Channel die Informationen über jeden einzelnen Prozess zu sammeln, die jeweils ein Aufruf der Funktion
»getProcData()«
ermittelt.
Da die Funktionen unabhängig voneinander arbeiten, kann man auf Synchronisation verzichten und einen Buffered Channel verwenden, der soviele Einträge aufnehmen kann, wie es Prozesse gibt – dieser Wert ist ja bereits nach dem Lesen des Proc-Verzeichnisses bekannt. Die Einträge im Channel sollen vom selbstdefinierten Typ
»ProcData«
sein, der die Einträge
»name«
,
»pid«
,
»ppid«
,
»uid«
und
»user«
umfasst. Einen passenden Channel definiert das folgende Statement:
cs := make(chan ProcData, len(pids))
In der folgenden Schleife startet das Hauptprogramm für jede Prozess-ID eine Goroutine, die ihr Ergebnis in diesen Channel schreibt ( Abbildung 1 ):
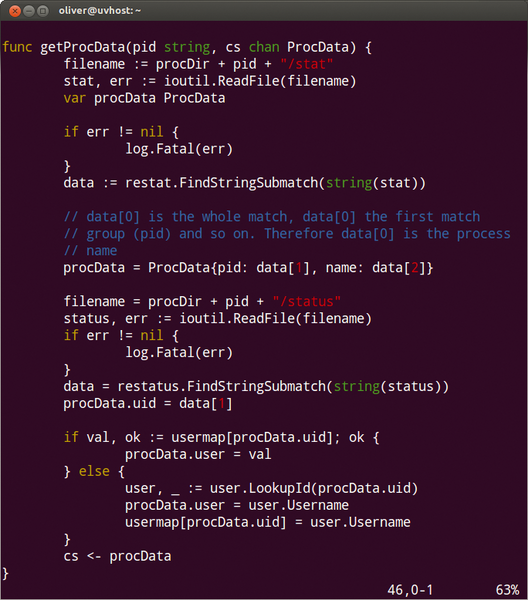 Abbildung 1: Parallelisiert: Am Ende schreibt die Funktion das Ergebnis in einen Channel.
Abbildung 1: Parallelisiert: Am Ende schreibt die Funktion das Ergebnis in einen Channel.
for _, pid := range pids {
go getProcData(pid, cs)
}
Praktisch gleichzeitig lesen nun alle Goroutinen die Informationen zu je einem Prozess aus und schreiben das Ergebnis in den Channel. Eine Schleife im Hauptprogramm liest aus dem Channel und gibt die Prozessinformation aus:
for i := 0; i < len(pids); i++ {
procData := <-cs
Steht eine Information noch aus, ist also ein Slot in dem Channel noch nicht gefüllt, wartet die Schleife, bis sie zur Verfügung steht. Man sollte also dafür sorgen, dass die Funktion
»getProcData()«
auch in den Channel schreibt, wenn ein Problem auftritt.
Baustellen
Potenzielle Fehlerursachen gibt es viele. Da das Programm die Prozess-IDs zuerst ausliest und erst danach die Informationen zu jedem Prozess ermittelt, kann in der Zwischenzeit ein Prozess verschwinden.
»getProcData()«
versucht dann, für eine Prozess-ID eine Proc-Datei zu öffnen, die es nicht mehr gibt. Das ist kein Weltuntergang, aber man muss den Fehler abfangen und die Tatsache, dass er aufgetreten ist, irgendwie dem Hauptprogramm mitteilen – und gleichzeitig die vorgesehenen Slots im Channel füllen.
Man könnte entweder die
»ProcData«
-Struktur um ein Feld
»valid«
erweitern, das angibt, ob die Abfrage der Prozessinformationen erfolgreich war. Alternativ, aber weniger sauber, ließe sich ein anderes Feld von
»ProcData«
zweckentfremden, das man im Fehlerfall mit einem passenden Wert belegt.
Auch der Zugriff auf den Cache der Benutzernamen
»usermap«
müsste eigentlich noch geschützt werden, denn möglicherweise greifen die diversen Goroutinen gleichzeitig darauf zu. Dies ließe sich beispielsweise klassisch mit einer Mutex-Variable bewerkstelligen. Go-typisch und schöner wäre es allerdings, auch dies mit Channels umzusetzen. Ein ungepufferter Channel würde dabei zum gleichen Ergebnis führen wie ein Mutex: Nur eine Goroutine dürfte zu einem Zeitpunkt auf die Map zugreifen. Weitere überschaubare Beispiele zur Anwendung von Goroutinen demonstriert Rob Pike in einem Video auf der Google-I/O-Konferenz
[2]
.
Infos
- Oliver Frommel, Programmieren in Go, ADMIN 2/2014, S. 100: http://www.admin-magazin.de/Das-Heft/2014/02/Programmieren-in-Go
- Google I/O 2012 – Go Concurrency Patterns: http://www.youtube.com/watch?v=f6kdp27TYZs
Ähnliche Artikel
-
Programmieren in Go

-
Ein Blick in den Linux-Kernel mit Systemtap

-
HA-Serie, Teil 8: OCF-Agenten selbst programmieren

-
ADMIN-Tipp: Arbeitsverzeichnis herausfinden
Etwa bei der Fehlersuche ist es oft nützlich zu wissen, in welchem Arbeitsverzeichnis beispielsweise ein Daemon gestartet wurde. Über das Proc-Filesystem von Linux lässt sich dies herausfinden.
-
Cluster-Dateisystem OCFS2 einfach gemacht

Programmieren in Go
Konfigurationsmanagement

Themen


