Workshop: Analyse großer Datenmengen mit Apache Storm

Im Auge des Datensturms

Es spielt heute kaum noch eine Rolle, ob das eigene Unternehmen dem produzierenden Gewerbe oder der Dienstleistungsbranche angehört: Die Datenmengen, die es zu verarbeiten gilt, wachsen von Jahr zu Jahr. Heute spülen unterschiedlichste Quellen gigantische Informationen in die Rechenzentren und auf die Rechner der Mitarbeiter. Nicht umsonst ist in diesem Zusammenhang von Big Data die Rede – ein Schlagwort, das die IT-Branche regelrecht zu elektrisieren scheint.
Bei Big Data geht es um die wirtschaftlich sinnvolle Gewinnung und Nutzung entscheidungsrelevanter Erkenntnisse aus qualitativ unterschiedlichen und strukturell höchst diversifizierten Informationen. Erschwerend kommt hinzu, dass diese Rohdaten häufig einem schnellen Wandel unterliegen. Big Data stellt Konzepte, Methoden, Technologien, IT-Architekturen und Tools bereit, mit denen Unternehmen diese Informationsflut in vernünftige Bahnen lenken können.
Storm auf einen Blick
...Der komplette Artikel ist nur für Abonnenten des ADMIN Archiv-Abos verfügbar.
Ähnliche Artikel
-
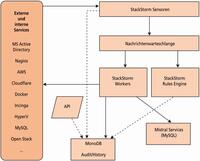
Automatisierung mit StackStorm
-
Postgres-XL realisiert Datenbank-Cluster mit ACID

Ein Projekt, das neuerdings unter einer Open-Source-Lizenz steht, erlaubt die transparente Skalierung von PostgreSQL über mehrere Rechner.
-
ADMIN-Tipp: Account-Management für SSH
Wer des vielen Tippens von Hostnamen beim Remote Login müde ist, kann sich einem kleinen Hilfsprogramm einige Anschläge sparen.
-
Kubernetes in vSphere ohne Cloud Foundation betreiben

-
Shellshock-Angriffe jetzt per E-Mail
In einer neuen Welle von Angriffen versuchen Spammer, die Bash-Lücke per E-Mail auszunutzen.
Konfigurationsmanagement

Themen


