Security-Monitoring und -Logging mit Open Source (1)

Administration mit Ausblick

In dieser dreiteiligen Workshopserie beschreiben wir den Aufbau einer Security-Monitoring-Architektur basierend auf den Open Source-Produkten Graylog, Nagios, Cacti, Nagvis sowie einem SMS- und E-Mail-Gateway. Im ersten Teil der Serie stellen wir die Komponenten vor und zeigen deren Installation. Unsere Beispielarchitektur bildet darüber hinaus eine Basis für ein zukünftiges SIEM (Security Information and Event Management) – alle Komponenten lassen sich in der Regel nahtlos in eine geeignete Managementoberfläche einbinden.
Logging-Server-Architektur
Zunächst geht es an das Einsammeln von Daten. Unsere zentralen Komponenten der Logging-Architektur sind:
- Graylog-Server (graylog-server): Entgegennahme und Verarbeitung von Logmeldungen sowie Alarmierung
- Webinterface (graylog-web-interface): Web-basierter Zugriff auf die Logmanagementsoftware via Browser zur Administration, Konfiguration und Überwachung von Graylog
- MongoDB: Speicherung von Konfigurations- und Meta-Daten des Graylog-Servers
- Elasticsearch: Indexierung und Speicherung von Logmeldungen sowie Bereitstellung der Suchfunktion
- Loadbalancer (optional): Verteilung von Logmeldungen auf mehrere Graylog-Server
Graylog ist eine Open Source-Logmanagementsoftware, die eine zentrale Speicherung, Verarbeitung und Analyse von Logmeldungen von verschiedenen Logquellen wie Servern, Clients oder Netzwerkgeräten ermöglicht. Der Loggingserver Graylog basiert auf Java und bietet die Möglichkeit, mehrere sogenannte Server-Nodes in einem Cluster für Skalierbarkeit und Hochverfügbarkeit zusammenzufassen. Da andere Programme wie Octopussy [1] oder Logstash [2] die Sicherheitsanforderungen an Verfügbarkeit (Skalierbarkeit) nur zum Teil erfüllen, setzen wir in unserem Workshop Graylog ein in der aktuellen, stabilen Version 1.0.2.
Zwecks Lastverteilung nutzen wir mehrere Graylog-Server mit einem vorgeschalteten Loadbalancer. Auf diese Weise werden die Anfragen mit eingehenden Logmeldungen zur Verarbeitung auf mehrere gleichartige Graylog-Server verteilt. Als Loadbalancer empfiehlt sich Zen [3] in der Community Edition. Zum Einsatz kommt bei uns ebenfalls die aktuelle, stabile Version 3.05 vom Oktober 2014. Statt Zen können Sie natürlich auch andere Produkte verwenden. Allerdings ist die Auswahl nicht allzu groß, wenn Logmeldungen über das Netzwerkprotokoll UDP (User Datagram Protocol) übertragen werden sollen.
Der Zugriff auf das Webinterface (graylog-web-interface) findet über HTTP/ HTTPS via Browser statt. Die Authentifizierung des Graylog-Users kann hierbei neben eigenen Benutzerkonten auch über LDAP erfolgen. Die Kommunikation zwischen dem Webinterface und dem Graylog-Server (graylog-server) erfolgt wiederum über das REST-Protokoll (HTTP-basiert) und lässt sich ebenfalls dank HTTPS schützen.
Die Clients sind IT-Systeme, die ihre Logmeldungen zum Logging-Server übertragen. Diese werden via TCP oder UDP in den Formaten GELF (Graylog Extended Log Format) beziehungsweise Syslog übermittelt und können ebenfalls über TLS (falls TCP in "nxlog" beziehungsweise "syslog" zum Einsatz kommt) abgesichert werden. Auch die Kommunikation zwischen dem Graylog-Server und den Komponenten "ElasticSearch" sowie "MongoDB" findet über HTTP/REST sowie weitere proprietäre Anwendungsprotokolle statt.
Der Loadbalancer Zen nimmt die eingehenden Logmeldungen entgegen und leitet diese entsprechend der Konfiguration für die Lastverteilung an die Graylog-Server weiter. Auf dem Loadbalancer sind entsprechende TCP- und UDP-Ports für die Clients verfügbar. Je nach Einsatzzweck und Anforderungen können Sie den Loadbalancer auch redundant auslegen, um die Verfügbarkeit des Dienstes zu erhöhen.
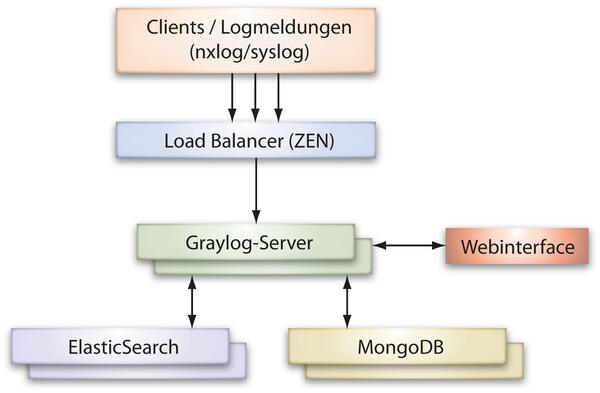 Bild 1: Eine vereinfachte schematische Darstellung unserer Graylog-Architektur.
Bild 1: Eine vereinfachte schematische Darstellung unserer Graylog-Architektur.
Skalierbarkeit und Hochverfügbarkeit von Graylog
Die Architektur des Logging-Servers "Graylog" ist clusterfähig und so mit relativ geringem Aufwand erweiterbar. Die in Bild 2 dargestellte Architektur umfasst die wesentlichen Komponentengruppen, die unabhängig voneinander als Cluster ausgelegt werden können:
- Loadbalancer-Cluster
- Graylog-Server-Cluster
- ElasticSearch-Cluster
- MongoDB Replica Set
Voraussetzungen für Graylog
Für den Einsatz von Graylog in der aktuellen Version (Version 1.0.2) sind folgende Software-seitigen Voraussetzungen für die einzelnen Komponenten zu erfüllen:- Graylog-Server (graylog-server): Java 7 oder höher (OpenJDK / Oracle (Sun) Java)- Webinterface (graylog-web): Java 7 oder höher (OpenJDK / Oracle (Sun) Java)- MongoDB: Aktuelle, stabile Version (mindestens Version v2.0)- Elasticsearch: Elasticsearch in der Version 1.3.7 oder höherGraylog wird lediglich von Linux-Betriebssystemen unterstützt, wie zum Beispiel- Ubuntu (Version 14.04 / 12.04)- Debian (Version 7)- CentOS (Version 6)
Um die Skalierbarkeit des Clusters bei steigendem Ressourcenbedarf zu erhöhen, ist in erster Linie die Erweiterung des Graylog-Server-Clusters und des ElasticSearch-Clusters erforderlich. Für eine Hochverfügbarkeit (HA) des Loadbalancers erweitern Sie den Loadbalancer-Cluster.
Den Graylog-Server-Cluster erweitern Sie durch das Hinzufügen weiterer Graylog-Server als Nodes, um eine höhere Anzahl an Logmeldungen pro Minute verarbeiten zu können. Hierbei ist primär Rechenleistung (CPU) erforderlich. Die Lastverteilung erfolgt durch einen vorgeschalteten Loadbalancer, der die Logmeldungen zur Verarbeitung auf einzelne Graylog-Server verteilt. Die hinzugefügten Nodes erhöhen gleichzeitig die Ausfallsicherheit, da beim Ausfall eines Graylog-Servers der Logging-Server weiterhin funktionsfähig ist.
Die Erweiterung des ElasticSearch-Clusters erfolgt analog zur Erweiterung des Graylog-Server-Clusters. Durch weitere ElasticSearch-Nodes lässt sich eine größere Anzahl an Logmeldungen speichern und verarbeiten. Hierbei sind primär Arbeitsspeicher (RAM) und Speicherplatz (HDD) erforderlich. Zusätzliche ElasticSearch-Nodes sorgen für eine Verbesserung der Verfügbarkeit des Clusters und mehr Performance bei Suchanfragen. Die im ElasticSearch-Cluster gespeicherten Logmeldungen werden zwischen dem Master und den Slaves automatisch repliziert.
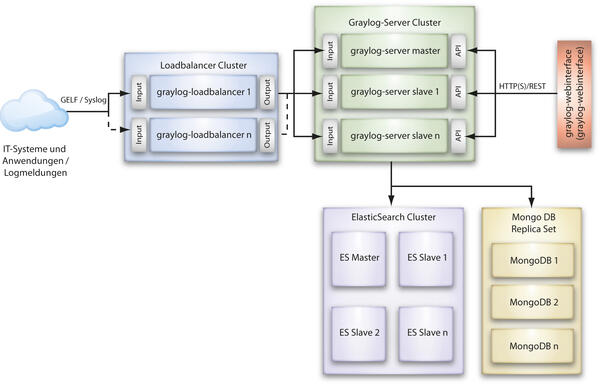 Bild 2: Die Komponenten von Graylog lassen sich als Cluster mit Skalierbarkeit und HA betreiben.
Bild 2: Die Komponenten von Graylog lassen sich als Cluster mit Skalierbarkeit und HA betreiben.
Wie in Bild 2 veranschaulicht, nutzen wir in unserem Szenario die Datenbank MongoDB als Replica Set, indem wir die erste Instanz der Datenbank (MongoDB1) im Modus "Master" und die zweite Instanz (MongoDB2) im Modus "Slave" ausführen. Die Master-Datenbank ist so konfiguriert, dass diese automatisch auf die zweite Instanz der Datenbank repliziert wird. Das Replica Set der Datenbank erhöht so die Verfügbarkeit von Daten und lässt sich um weitere Datenbankinstanzen erweitern.
Ähnliche Artikel
-
Security-Monitoring und -Logging mit Open Source (2)

-
Logdateien verwalten mit Graylog 3.0
-
Neue Version des Logging-Servers Graylog2
Graylog2 implementiert in Version 0.9.3 einige Verbesserungen im Web-GUI sowie im Backend.
-
Graylog 1.2 veröffentlicht
Die neue Graylog-Version bringt mehr Performance und einfacheres Management in LDAP-Umgebungen.
-
Neue Syslog-Implementation Graylog2 speichert in MongoDB
Eine neue Implementierung des Unix-Syslog sammelt Log-Informationen und speichert sie in einer NoSQL-Datenbank.
Konfigurationsmanagement

Themen


