Live-Migration von VMs mit KVM

Wandertag

Auf Linux-Systemen hat der im Kernel integrierte Hypervisor KVM (Kernel-based Virtual Machine) seit langem die Oberhand gewonnen. Der Grund dafür ist, dass KVM in allen gängigen Linux-Distributionen ohne zusätzliche Konfiguration zur Verfügung steht und die großen Distributoren wie Red Hat und Suse kontinuierlich an der Verbesserung von KVM arbeiten. Dabei sind für die meisten Anwender die oberen Leistungsgrenzen hinsichtlich Speichernutzung und Anzahl an VMs wohl weniger interessant als Brot- und Butter-Features, die etwa der Konkurrent VMware schon anbot, als KVM noch in den Kinderschuhen steckte.
Mittlerweile hat KVM aufgeholt und bietet schon seit einigen Jahren die Live-Migration virtueller Maschinen [1], die eine Voraussetzung dafür ist, Dienste zuverlässig zu virtualisieren. Denn damit lassen sich VMs samt Diensten von einem Server zum anderen migrieren, was etwa für Lastverteilung oder Hardware-Updates nützlich ist. Auch die Hochverfügbarkeit von Services kann mit Hilfe von Live-Migration einfacher realisiert werden. Live-Migration bedeutet dabei, dass die virtuellen Maschinen, abgesehen von einer möglichst kurzen Zeitspanne, weiterlaufen. Im Idealfall merken Client-Rechner, die eine VM als Server verwenden, von einer Migration nichts.
Die Live-Migration wird durch einige ausgeklügelte Technologien umgesetzt, die sicherstellen sollen, dass einerseits die Unterbrechung des Diensts möglichst kurz ist, und andererseits der Zustand der migrierten Maschine genau demjenigen der Ursprungsmaschine entspricht. Dazu starten die beteiligten Hypervisoren die Übertragung des RAM-Speichers und beginnen gleichzeitig damit, die Aktivitäten der Ausgangsmaschine zu überwachen. Sind die verbliebenen Änderungen klein genug, um sie in der vorgesehenen Zeit zu übertragen, wird die Ursprungs-VM pausiert, der noch nicht übertragene Speicher an das Ziel kopiert und dort die neue Maschine gestartet.
Shared Storage notwendig
Eine Voraussetzung für die Live-Migration von KVM-Maschinen ist, dass die beteiligten Disks auf einem Shared Storage liegen, also einem Datenspeicher, der zwischen Ursprungs- und Ziel-Host geteilt wird. Dies lässt sich beispielsweise mit NFS, iSCSI, Fibre Channel, aber auch mit verteilten oder Cluster-Dateisystemen wie GlusterFS und GFS2 erreichen. Libvirt, die Abstraktionsschicht zum Management unterschiedlicher Hypervisor-Systeme in Linux, verwaltet Datenspeicher in sogenannten Storage Pools. Dies können neben den erwähnten Technologien beispielsweise auch konventionelle Disks sowie ZFS-Pools oder Sheepdog-Cluster sein.
Die verschiedenen Technologien für Shared Storage bieten unterschiedliche Vorteile und erfordern mehr oder weniger Konfigurationsaufwand. Verwenden Sie Storage-Appliances der bekannten Hersteller, können Sie deren Netzwerk-Storage-Protokolle verwenden, also iSCSI, Fibre Channel oder eben NFS. Beispielsweise bietet NetApp Clustered ONTAP auch Support für pNFS, das von neueren Linux-Distributionen wie Red Hat Enterprise Linux oder CentOS 6.4 unterstützt wird. iSCSI lässt sich dagegen dank Multipathing redundant betreiben, aber dafür muss wieder die entsprechende Netzwerkinfrastruktur vorhanden sein. Fibre Channel ist in dieser Hinsicht am aufwendigsten, denn es erfordert ein eigenes SAN (Storage Area Network). Dazu gibt es mit FCoE (Fibre Channel over Ethernet) noch eine kupferbasierte Alternative, die aber eigentlich nur von der Firma Mellanox angeboten wird. Eine noch exotischere Lösung ist SCSI RDMA über Infiniband oder iWARP.
Testumgebung mit NFS einrichten
Für die ersten Tests geht es auch eine Nummer kleiner, also mit NFS, denn ein solcher Storage lässt sich auch mit Hausmitteln realisieren. Beispielsweise mit einem Linux-Server auf Basis von CentOS 7 ist ein NFS-Server im Handumdrehen installiert. Weil der NFS-Server größtenteils im Linux-Kernel implementiert ist, fehlen nur noch der RPCBind-Daemon und die nötigen Tools zum Management von NFS, die sich über das Paket "nfs-utils" installieren lassen. Die vom Server zur Verfügung gestellten ("exportierten") Verzeichnisse listet die Datei "/etc/exports" auf. Den NFS-Dienst startet der folgende Aufruf:
systemctl start nfs
Über Erfolg oder Misserfolg gibt ein Aufruf von
»journactl -xn«
Auskunft. Die aktuell exportierten Verzeichnisse listet
»showmount -e«
auf. Im Prinzip ist die Syntax der Exports-Datei einfach: das exportierte Verzeichnis gefolgt von IP-Adresse oder Hostnamen derjenigen Rechner, die das Ver- zeichnis mounten dürfen, und dahinter noch die Optionen, die beispielsweise festlegen, ob die Shares nur zum Lesen oder auch zum Schreiben freigegeben sind. Von diesen Optionen gibt es freilich eine ganze Menge, wie ein Blick in die Manpage von "exports" zeigt. Um mit Root-Rechten von anderen Rechnern auf die Netzlaufwerke zu schreiben, müssen Sie das mit der Option "no_root_squash" erlauben. Eine entsprechende Zeile in "/etc/exports" sähe dann etwa so aus:
/nfs 192.168.1.0/ 24(rw,no_root_squash)
Damit dürfen alle Rechner aus dem Netz 192.168.1.0 mit Root-Rechten das Verzeichnis "/nfs" mounten und darauf schreiben. Den NFS-Server können Sie daraufhin neu starten oder ihn über die Änderungen einfach per
»exportfs -r«
unterrichten. Wenn Sie nun von einem Rechner versuchen, aus dem besagten Netz das Verzeichnis zu mounten, schlägt das unter Umständen fehl, weil Sie auf dem Server noch die Firewall anpassen müssen, also den TCP-Port 2049 öffnen.
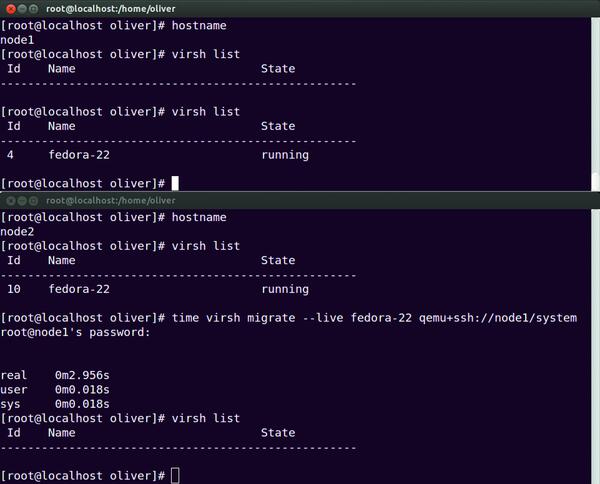 Bild 1: In knapp drei Sekunden wurde die virtuelle Maschine "fedora-22" vom Rechner node2 auf node1 übertragen.
Bild 1: In knapp drei Sekunden wurde die virtuelle Maschine "fedora-22" vom Rechner node2 auf node1 übertragen.
Ähnliche Artikel
-
Erstes Community-Release 3.0 von oVirt für KVM-Management
Das erste offizielle Release 3.0 der Software oVirt zum Management virtueller Umgebungen unter Linux ist fertig.
-
oVirt 3.3 unterstützt OpenStack
In der neuesten Version findet das Management-Tool oVirt auch Anschluss an die Cloud.
-
oVirt 3.1 KVM-Virtualisierungsmanagement verbessert
Mit einer Reihe von Verbesserungen lässt sich das KVM-Management-Tool oVirt leichter in bestehende Infrastrukturen integrieren.
-
Beta von Red Hat Enterprise Virtualization 3.1 veröffentlicht
Im anstehenden Release 3.1 des Virtualisierungsprodukts hat Red Hat dessen Fähigkeiten noch einmal erweitert.
-
Migration virtueller Maschinen

Konfigurationsmanagement

Themen


