
Job-Agentur
Um Aufträge anzulegen, editieren Sie die XML-Dateien direkt oder im Job Editor. Führen Sie unter Linux dazu das Skript
»jobeditor.sh«
aus, das in
»$HOME/scheduler/bin/«
liegt. Als Beispiel soll ein Backup der Systemkonfiguration entstehen. Das zuständige Skript ist
»/usr/local/bin/config_backup.sh«
.
Beginnen Sie mit dem Job Editor und wählen
»New | Hot Folder Element | Job«
. Geben Sie im ersten Formular die Basisinformation für den Job ein (
Abbildung 1
), zum Beispiel
»Configuration Backup«
als Job-Name. Wenn Sie im linken Feld
»Execute«
auswählen, können Sie die Details für das Programm oder Skript eingeben, das ablaufen soll.
Für das Backup-Skript wählen Sie den Radio-Button
»Run executable«
und nennen den vollständigen Pfad zum oben erwähnten Skript. Hier geben Sie auch zusätzliche Parameter ein, die das Programm oder Skript verarbeitet. Alternativ können Sie, wenn Sie den Typ
»Script«
wählen, auch direkt den Code in das
»Source Code«
-Feld eingeben.
Wenn Sie den Job zum ersten Mal speichern, fragt der Scheduler nach dem Dateinamen. Navigieren Sie dann nach
»../config/live«
und geben
»ConfigurationBackup«
ein, die Erweiterung
».xml«
ergänzt das Programm selbst. Durch das Speichern im Live-Verzeichnis ist die Änderung sofort wirksam. Dieses Verzeichnis ist als Hot Folder vorgegeben, den das System regelmäßig überprüft.
Sie haben nun den Job hinzugefügt, aber noch nicht zur Ausführung eingeplant. Dazu wechseln Sie ins Operations-GUI, indem Sie mit dem Webbrowser zu
»http://localhost:4444«
navigieren. Es erscheint ein GUI, ähnlich dem in
Abbildung 2
gezeigten.
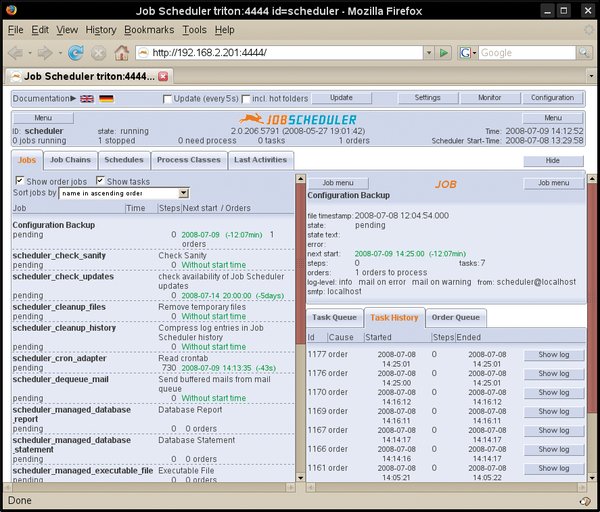 Abbildung 2: Im Operations-GUI verwaltet der Administrator die angelegten Jobs.
Abbildung 2: Im Operations-GUI verwaltet der Administrator die angelegten Jobs.
Um die Details zu sehen, doppelklicken Sie in der linken Spalte auf einen Job. Mit
»Start task now«
, das sich hinter dem
»Job menu«
-Schalter verbirgt, starten Sie ihn sofort. Das ist ziemlich unspektakulär, denn das könnten Sie genauso gut auf der Kommandozeile machen. Zurück im Job Editor können Sie aber über
»Run Time«
(siehe
Abbildung 1
) festlegen, wann der Job starten soll.
Bisher haben sie praktisch nur Cron mit einem netten GUI, aber das war nur der Anfang. Spätestens bei den Job Chains entfaltet der Open Source Job Scheduler sein volles Potenzial. Angenommen Sie haben noch einen zweiten Job, der ein Datenbank-Backup macht. Er soll starten, wenn das erste Backup-Skript beendet ist. Theoretisch könnten Sie diese Abhängigkeit natürlich in ein Skript auslagern, das die beiden Backup-Skripte nacheinander ausführt, das wäre sozusagen der Cron-Weg. Job Chains sind aber im Open Source Job Scheduler der wesentlich bessere Weg, vor allem wenn die Setups noch komplexer sind als im Beispiel für diesen Artikel.
Legen Sie dazu wie im ersten Beispiel ein neues Element im Hot Folder an, aber wählen Sie dieses Mal
»Job Chains«
. Jeder Bestandteil der Kette wird als Element bezeichnet, deshalb heißt der entsprechende Button zum Hinzufügen
»New Chain Node«
. Sie können den Namen des Jobs manuell eingeben oder mit
»Browse«
danach suchen.
Im Feld
»State«
definieren Sie einen Status für diesen Node. Über diese Zustände lassen sich komplexe Arbeitsabläufe abbilden. Zum Beispiel könnten Sie einen Fehlerzustand namens
»Error«
definieren und dann, wenn ein Fehler auftritt, direkt zu diesem Job springen und alle anderen abbrechen. Genauso gut könnten Sie mehrere Fehlerzustände definieren, um damit unterschiedliche Fehlerarten zu behandeln.
Legen Sie noch einen zweiten Node für das Datenbank-Backup an und konfigurieren ihn analog zum ersten. Sie können den ersten Node als Start-Zustand benennen, den zweiten als Ende-Zustand, aber das ist nicht zwingend notwendig. Nach dem Speichern finden Sie die neue Job Chain im gleichnamigen Reiter des Operations-GUI. Ein Klick auf
»Show Jobs«
enthüllt die einzelnen Jobs. Genauso wie im Fall der Einzeljobs zeigt ein Doppelklick auf die Chain im rechten Fensterteil die näheren Details.
Damit die Job Chain endlich abläuft, fehlt ihr noch der nötige Marschbefehl, den Sie ihr über das
»Job Menu«
und den Punkt
»Add Order«
erteilen. In dem sich daraufhin öffnenden Fenster geben Sie je nach Bedarf eine ganze Menge Informationen ein, darunter Order-ID, Startzeit und den Zustand, zu dem die Chain springen sollen. Wenn Sie einfach alles leer lassen, dann legt der Scheduler selbst eine Order-ID an.
Wenn Sie keine Bedingungen definiert haben, startet die Job Chain sofort. Ist aber ein
»Time Slot«
für einen der enthaltenen Jobs definiert, wartet der Scheduler bis zu diesem Zeitpunkt. Die einzelnen Jobs müssen so eingerichtet sein, dass sie Orders akzeptieren. In den Hauptoptionen jedes Jobs muss dafür das Häkchen
»On Order«
gesetzt sein, sonst wird die Order den Job nicht starten.
Bisher haben Sie alle Jobs mehr oder weniger von Hand gestartet. Es stellt sich die Frage, woher nun die Orders kommen, die Sie bei der Job Chain eingerichtet haben. Ein Weg ist, eine Order zu einem bestimmten Zeitpunkt zu erzeugen, die dann die Chain startet. Das geht über das Menü
»New | Hot Folder Element | Order«
. Wählen Sie im
»Job Chains«
-Fenster die Chain aus, die Sie mit dieser Order verbinden wollen. Beachten Sie, dass eine Order nur mit einer Chain verknüpft sein kann.
Definieren Sie dann eine
»Time Period«
und einen Zeitpunkt
»Single Start«
von zum Beispiel
»09:00«
. Um die Änderungen sofort in Kraft zu setzen, speichern Sie sie im Hot Folder
»config/live«
. Zurück im Operations-GUI sehen Sie, dass die Order nun mit der Job Chain verknüpft ist. Darunter zeigt ein Eintrag den nächsten Startzeitpunkt an. Einen Überblick über Chains und Abhängigkeiten gibt die Job Chain Illustration (
Abbildung 3
).
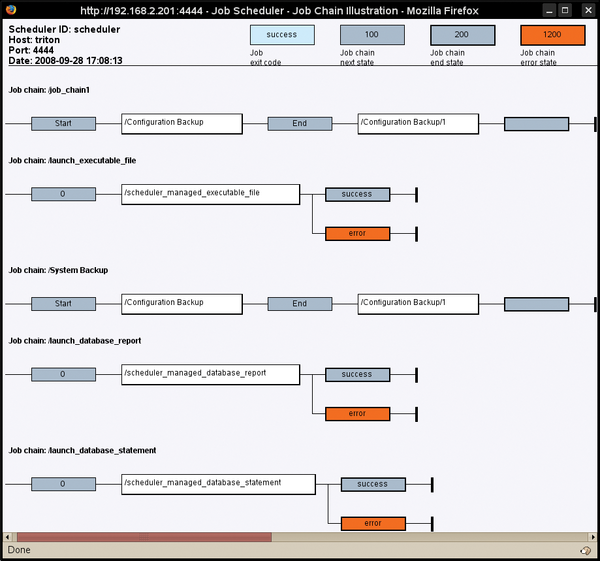 Abbildung 3: Die Job Chain Illustration zeigt die Job Chains und ihre Abhängigkeiten.
Abbildung 3: Die Job Chain Illustration zeigt die Job Chains und ihre Abhängigkeiten.
Logisch
Es gibt einige Möglichkeiten, die Zeitpunkte, Job Chains und Orders zu kombinieren. So können Sie einen konkreten Zeitpunkt mit der Fertigstellung anderer Jobs verknüpfen. Angenommen die tägliche Abrechnung soll erst starten, wenn alle Datenbank-Importe abgeschlossen sind. Aber weil die Abrechnung so viel Last auf dem Server erzeugt, soll sie erst nach 23 Uhr beginnen.
Oft soll ein Job erst starten, wenn eine bestimmte Datei erzeugt wurde. Ein gangbarer Weg ist, das Job-Skript so zu schreiben, dass es sich beendet, wenn diese Datei nicht vorhanden ist. Besser ist es aber, so genannte Watch Directories anzulegen, die der Scheduler im Blick behält. Damit startet das Skript erst dann, wenn die benötigte Datei auch da ist, und muss nicht sinnloserweise starten und sich wieder beenden.
Ähnliche Artikel





Konfigurationsmanagement

Themen


