
Monitoring
Per Default prüft OpenNMS in einem fünfminütigen Polling-Intervall die Verfügbarkeit von Nodes und Services. Warum es gerade fünf Minuten sind, ist relativ leicht einzusehen: Bei einer garantierten Verfügbarkeit von 99,99 Prozent pro Monat liegt die maximal erlaubte Ausfallzeit bei 4,32 Minuten und passt damit ziemlich genau in ein Intervall. Sobald OpenNMS einen Ausfall erkennt, prüft es den betroffenen Service für die nächsten fünf Minuten aller 30 Sekunden. Besteht der Ausfall danach fort, stuft ihn die Software als signifikant ein und kehrt für die nächsten 12 Stunden zu dem Fünf-Minuten-Intervall zurück. Ist das Problem auch nach 12 Stunden nicht beseitigt, erhöht OpenNMS das Intervall auf 10 Minuten für die folgenden fünf Tage. Danach würde der Service als
»forced unmanaged«
markiert und das Polling eingestellt. Wer in verschiedenen SLAs verschiedene Verfügbarkeiten garantiert, kann diese Werte leicht im File
»poller-configuration.xml«
hinterlegen.
OpenNMS benutzt verschiedene Monitoringmethoden wie SNMP, ICMP-Ping, die Ansprache gebräuchlicher Services wie SSH, DNS oder HTTP oder den Web-seitenabruf mit Inhaltscheck. Zusätzlich können eigene Checks geschrieben und Nagios-Plugins verwendet werden, auch auf die Windows Management Instrumentation (WMI) kann der Admin zurückgreifen oder er ermittelt Antwortzeiten ( Abbildungen 2 und 3 ).
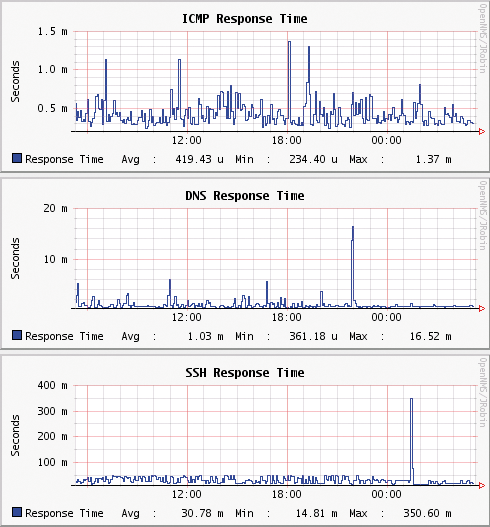 Abbildung 2: Hier stellt OpenNMS Antwortzeiten in einem Chart dar.
Abbildung 2: Hier stellt OpenNMS Antwortzeiten in einem Chart dar.
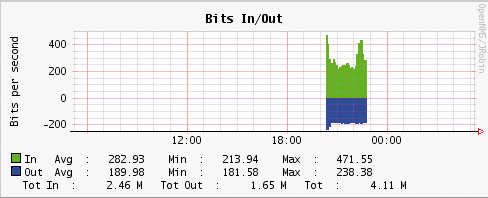 Abbildung 3: So sieht OpenNMS den Netzwerkverkehr von und zu einem Drucker – bei geringem Druckaufkommen.
Abbildung 3: So sieht OpenNMS den Netzwerkverkehr von und zu einem Drucker – bei geringem Druckaufkommen.
Wo zentralisiertes Monitoring nicht funktioniert (zum Beispiel, weil Zweigstellen hinter einer Firewall sitzen), bietet OpenNMS sogenannte Remote Monitors. Diese Software-Agenten können auf entfernten Systemen laufen und über deren Gesundheitszustand an einen zentralen OpenNMS-Server berichten.
Benachrichtigungen
Das Erkennen von Ausfällen ist schön und gut, aber noch wichtiger ist die korrekte Benachrichtigung. OpenNMS bedient sich hier des Konzepts der sogenannten Destination Paths, hinter denen sich eine Liste von Alarmierungsverfahren verbirgt, die so lange durchlaufen wird, bis ein Alarm bestätigt wurde (womit klar ist, das sich jemand damit befasst). Auf diese Weise lassen sich verschiedene Personen in einer vorgegebenen Reihenfolge auf verschiedenen Wegen kontaktieren (darunter via E-Mail, IRC, XMPP, Telefon, Pager) oder bestimmte HTTP-Requests absetzen oder Skripte ausführen. Beispielsweise könnte zuerst eine E-Mail an den Admin verschickt werden, während in der nächsten Eskalationsstufe ein Anruf zu Hause initiiert würde.
Was passiert, wenn ein Router ausfällt und dadurch ein ganzes Netzwerk dahinter für den OpenNMS-Server nicht mehr erreichbar ist? Das könnte zu Tausenden Alarmen führen, die das Benachrichtigungssystem überfluten würden und unter denen der wirklich wichtige Alarm eventuell untergeht.
Ähnliche Artikel
-
OpenNMS wird IPv6-fähig
In zwei neuen Releases beschert das Open Network Management System seinen Anwendern neue Features und Bugfixes.
-
Netzwerkmonitoring mit OpenNMS

-
OpenNMS User Conference Europe
Zum nunmehr dritten Mal lädt die NETTHINKS GmbH zur OpenNMS User Conference Europe (OUCE) für den 26. und 27. Mai nach Fulda ein.
-
Die Schweizer Messer im Fault-Management

-
OCS-Informationen in die Überwachung mit OpenNMS integrieren

Konfigurationsmanagement

Themen


