
Rechenzeit
Die CPU-Auslastung ist einer der am einfachsten zu beobachtenden Leistungsparameter. Die gebräuchlichste Maßeinheit ist dabei der sogenannte Load Average, definiert als die mittlere Anzahl der ausführbaren Prozesse in der Run Queue der CPU. Uneinigkeit herrscht hier allerdings darüber, ob Prozesse, die auf I/O-Operationen warten, als ausführbar gezählt werden oder nicht. Solaris etwa klammert sie aus, Linux bezieht sie aber ein.
Als Faustregel kann man sich merken, dass der Load Average die Anzahl der CPUs nicht um das Zwei-, unter Linux vielleicht auch kurzzeitig das Dreifache übersteigen sollte – andernfalls bildet die CPU den Flaschenhals, und das System reagiert nur noch träge. Ein Load Average von eins bei einer CPU würde bedeuten, dass ein Prozess den Prozessor belegt und keiner wartet. Weil Linux nun auch Prozesse in den Load Average einrechnet, die warten müssen, bis Platten Daten liefern, darf man den kritischen Wert hier etwas höher als eins pro CPU ansetzen. Doch spätestens wenn die Länge der Run Queue mehr als das Dreifache der CPU-Anzahl beträgt, warten zu viele Prozesse auf die knappe Ressource CPU. Den Load Average für die letzten ein, fünf und fünfzehn Minuten geben Tools wie
»uptime«
oder
»top«
aus.
Der Load Average ist allerdings nicht die einzige CPU-bezogene Metrik. Eine weitere ist etwa die Anzahl der sogenannten Context Switches. Damit sind die Umbauarbeiten gemeint, die jedes Multitasking-System ausführen muss, bevor es eine neue Task der CPU übergibt – entweder durch den Prozess-Scheduler oder weil es eine Interrupt-Service-Routine ausführt. Damit der unterbrochene Prozess später an derselben Stelle wieder fortgesetzt werden kann, sind im Zuge des Context Switch der Program Counter und andere Register im RAM zu sichern. Das kostet Zeit, und zwar unverhältnismäßig mehr als die Ausführung einer normalen Instruktion. Sehr viele Context Switches bremsen also, (Ähnliches gilt für sehr viele Interrupts, die ihrerseits auch immer einen Context Switch erzwingen). Noch teurer ist der Spaß, wenn der Prozess in einem Mehrprozessorsystem bei Wiederaufnahme die CPU wechselt und dadurch seinen Cache verliert. Moderne Betriebssysteme wie Linux sind deshalb darauf bedacht, die Anzahl der Context Switches zu optimieren und Prozesse an eine bestimmte CPU zu binden (CPU-Affinität).
Will man sich auf Prozessebene ansehen, wo die Rechenzeit abgeblieben ist, hilft
»time«
mit einer groben Übersicht, wie viel Zeit im User- und im Kernel-Modus bei der Ausführung eines Programms verbraucht wurde. Feiner granular sind die Ausgaben von
»latencytop«
(
Abbildung 3
). Voraussetzung dafür ist ein Kernel der Version 2.6.25 oder höher, in den die Optionen
»CONFIG_HAVE_LATENCYTOP_SUPPORT=y«
und
»CONFIG_LATENCYTOP=y«
einkompiliert sind. Danach lässt sich mit dem Userspace-Tool
»latencytop«
nachvollziehen, wo genau eine Verzögerung entsteht. Dies kann sich der Admin dann sowohl global für alle Prozesse als auch aufgeschlüsselt pro Prozess ansehen (
Abbildung 4
).
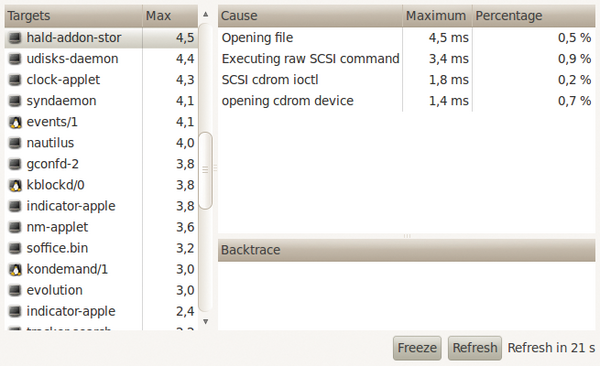 Abbildung 4: Latencytop zeigt, auf das Freiwerden welcher Ressourcen ein Prozess warten musste und womit er selbst die meiste Zeit verbrachte.
Abbildung 4: Latencytop zeigt, auf das Freiwerden welcher Ressourcen ein Prozess warten musste und womit er selbst die meiste Zeit verbrachte.
Will man noch tiefer einsteigen und wissen, welche Events nicht nur innerhalb eines Prozesses, sondern auch im Kernel wie viel Zeit verbrauchen, hilft der Profiler
»oprofile«
weiter, für den es auch eine GUI gibt (
Abbildung 5
). Oprofile benutzt dafür Performancecounter moderner CPUs und kann sich auch auf Softwaresymbole beziehen, sodass für Entwickler ein Quelltext mit Anmerkungen des Profilers entsteht. Für eine Offline-Analyse legt das Werkzeug Archive an.
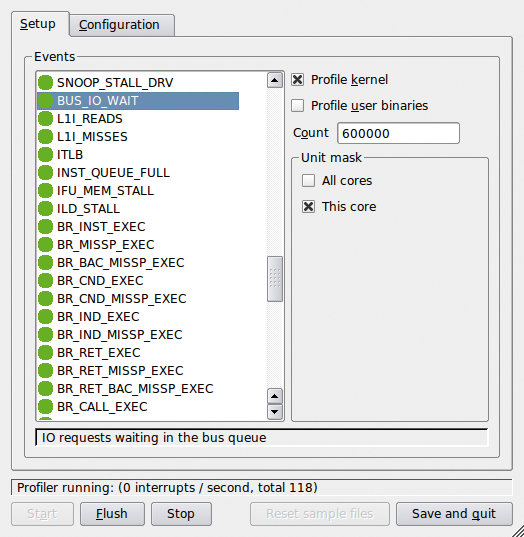 Abbildung 5: Oprofile sammelt im Hintergrund die Werte spezieller Performance Counter. Neben Entwicklern können auch Admins von den detaillierten Statistiken profitieren.
Abbildung 5: Oprofile sammelt im Hintergrund die Werte spezieller Performance Counter. Neben Entwicklern können auch Admins von den detaillierten Statistiken profitieren.
Analysieren
Hat man Werte erhoben, gilt es, sie zu bewerten. Wie schon erwähnt, helfen hier Vergleichsmöglichkeiten weiter. Auch eine Software wie das ebenfalls schon erwähnte Sarcheck mit eingebauter Einstufung der Messwerte kann hilfreich sein. Am Ende der Bewertung sollte eine Rangfolge der Probleme stehen, denen man sich zuwenden will. Selbst wenn man alle gleichzeitig angehen könnte – was in der Regel ausgeschlossen ist – wären dann die Effekte der einzelnen Maßnahmen nicht mehr zu trennen. Deshalb sollte der Tuner seine Aufgaben zunächst priorisieren und dann von der dringlichsten absteigend immer nur eine nach der anderen abarbeiten.
Auf das Messen und Bewerten folgt das Ändern der Konfiguration. Dabei sollte man sich angewöhnen, von Anfang an jeden Schritt peinlich genau zu dokumentieren. Nur so lässt sich am Ende sicher nachvollziehen, welche Maßnahme welche Wirkung gehabt hat.
Das Messen, Analysieren, Ändern und wieder Messen funktioniert allerdings nur, wenn der Tuner eine gute Vorstellung von der Funktionsweise des Subsystems hat, das er beschleunigen will. Hier gilt es, sich nötigenfalls einzulesen. Nur wer ein klares Bild davon hat, wie die Rädchen ineinandergreifen, auf die er einwirken will, kann einen vernünftigen Plan entwickeln. Und nur ein vernünftiger Plan führt zum Erfolg. Für nicht zielgerichtete Anstrengungen sind heutige Rechner zu komplex.
Ähnliche Artikel
-
NMon

-
Performance-Werte über längere Zeit sammeln und auswerten

- Tuning-Basics für Linux
-
ADMIN-Tipp: Das bessere top
Geht es um einen raschen Überblick über die Systemauslastung ist top sicher am schnellsten zur Hand. Load Average, CPU- und Speicherauslastung präsentiert es auf einen Blick. Aber es geht noch besser.
-
Die Tuning-Toolbox

Konfigurationsmanagement

Themen


