HA-Workshop, Teil 5: Troubleshooting, Tipps & Tricks

Aus der Werkstatt

Der Alltag eines
IT-Admins bietet gelegentlich genügend Gründe für pure Verzweifelung. Wer mit dem Linux-Clusterstack zu tun hat, kann davon meist eine mehrstündige Arie singen: Nach etlichen Stunden des Tüftelns ist die CIB-Konfiguration für Pacemaker endlich fertig, doch beim ersten Test führt das Abschalten eines Knotens nicht zum gewünschten Failover. Stattdessen schwadroniert der Kernel im
»dmesg«
von einem
»Split-Brain«
, und im Anschluss helfen nicht einmal mehr die bekannten Befehle, damit DRBD wieder tut, was es tun soll. Und dann ist da noch die ungute Erinnerung an das letzte Kernel-Update: Nach dem Reboot war einiges an Konfigurationsarbeit notwendig, um Pacemaker zur neuerlichen Kooperation zu überreden. Außerdem gab es Probleme mit der Datenbank, weil Pacemaker sie immer wieder neu gestartet hat. Eine Nacht ohne Schlaf war der Lohn für das Bestreben, die Software aktuell zu halten. Schrauben und Räder hat ein Cluster einige, und entsprechend viel kann in einem HA-Setup daneben gehen. Dieser Artikel versucht, die Ursachen für die häufigsten Fehler zu erklären, und beschäftigt sich ausführlich mit der kurz- und langfristigen Lösung der Cluster-Probleme.
Rund um DRBD
Die Replikationslösung DRBD hat üblicherweise direkt mit Hardware zu tun, denn der DRBD-Treiber kommuniziert mit den Storage-Laufwerken und sorgt dafür, dass auf den Platten landet, was auf die Platten gehört. Entsprechend ist es auch der DRBD-Treiber, der als Erster von Hardware-Problemen erfährt und idealerweise die richtigen Gegenmaßnahmen einleitet. Soforthilfe bringt die
»Diskless-Primary«
-Funktion, die viele Admins gar nicht kennen.
Schon der erste Artikel dieser Serie
[1]
erwähnte, dass der Befehl
»drbdadm up
Ressource
«
eigentlich ein Alias ist. Ruft ein Admin
»drbdadm up«
auf, dann tut
»drbdadm«
drei verschiedene Dinge: Zunächst sorgt es dafür, dass eine DRBD-Ressource sich für ihr konfiguriertes Backing-Device die exklusiven Zugriffsrechte sichert (der Einzelbefehl hierfür lautet
»drbdadm attach«
). Dann startet es im Kernel einen Receiver-Thread und einen Sender-Thread für die TCP/IP-Verbindung zum jeweils anderen Clusterknoten (
»drbdadm connect«
). Schließlich konfiguriert es auch die
»rate«
, also den maximal zulässigen Datendurchsatz dieser Ressource, wenn dieser in DRBDs Konfigurationsdatei festgelegt ist (
» drbdsetup /dev/
Minor-Nummer
-r
Rate
«
).
Alternativ zu
»drbdadm up«
wäre es folglich auch möglich, diese drei Befehle händisch abzusetzen. Mit
»drbdadm down«
verhält es sich übrigens ganz ähnlich: Es ist ein Alias für
»drbdadm disconnect«
und
»drbdadm detach«
– das Entfernen der Syncer-Rate entfällt, weil die beim nächsten Start der Ressource ohnehin wieder den Wert annimmt, den sie in der Config hat, oder den Default-Wert. Die beiden getrennten
»drbdadm up«
-Kommandos machen deutlich, dass der Netzwerkzustand einer DRBD-Ressource und ihr Plattenzustand miteinander nur indirekt zu tun haben. Faktisch kann eine DRBD-Ressource attached sein, aber keine Netzwerkverbindung haben.
Und umgekehrt geht's genauso: Eine Ressource kann eine Netzwerkverbindung haben, aber kein funktionierendes Backing Device. Dieses Feature trägt den schon erwähnten Namen
»Diskless Primary Mode«
und ist ein echter Retter in der Not, denn es sorgt im Zweifelsfalle dafür, dass ein Dienst trotz kaputter Festplatte unterbrechungsfrei weiterlaufen kann.
Diskless-Primary aktivieren
Ob der Diskless-Primary-Modus (
Abbildung 1
) zur Anwendung kommt, entscheidet sich in der DRBD-Konfiguration. Der Parameter heißt
»on-io-error«
, gehört zur Sektion
»disk«
und kennt als wichtigste Parameter
»pass_on«
und
»detach«
. Bis einschließlich DRBD 8.3 war es in der Default-Config so, dass DRBD I/O-Fehler von Backing Devices an das Dateisystem weitergab und diesem die Entscheidung überließ, was zu tun sei (
»pass_on«
). Ab DRBD 8.4 ist die
»detach«
-Option der Defaultwert.
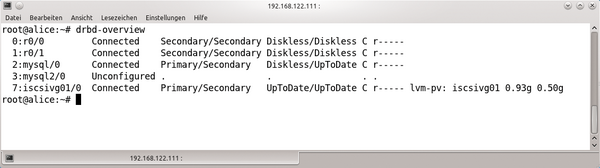 Abbildung 1: Dank des
Abbildung 1: Dank des
Sobald DRBD mit dieser Konfiguration Fehlermeldungen vom lokalen Storage erhält, gibt es automatisch sein Backing Device frei und lässt es fortan in Ruhe. Das geschieht unabhängig davon, ob die DRBD-Ressource gerade im
» Primary«
- oder
»Secondary«
-Modus ist. Admins können das feststellen, indem sie einerseits die entsprechenden Meldungen in
»dmesg«
verfolgen, andererseits ist im Feld
»ds«
in
»cat /proc/drbd«
der Wert für den Rechner mit der defekten Platte ab diesem Zeitpunkt
»Diskless«
.
Sollte die Ressource
»Primary«
sein, wickelt DRBD für sie sämtliche Lese- sowie Schreibvorgänge ab sofort über den verbliebenen sekundären Knoten ab.
Wann immer also ein Zugriff auf die Ressource ohne Backing Device stattfindet, holt DRBD sich vom sekundären Knoten die Daten oder schaufelt sie dorthin weiter – je nachdem, ob es sich um einen Lese- oder Schreibzugriff handelt. Der Vorteil für Admins liegt auf der Hand: Es geht mit dem Server zwar für die nächsten Stunden langsamer weiter – denn jeder Zugriff muss ja zwischen dem primären und dem sekundären Knoten hin- und herwandern – dafür lässt sich aber die Reparatur sinnvoll planen.
Der Switchover lässt sich beispielsweise in eine Zeit legen, in der weniger auf den Systemen los ist als zu einer Stoßzeit. Diskless-Primary gibt dem Admin also vor allem Zeit zum Planen.
Ähnliche Artikel





Konfigurationsmanagement

Themen


