
Ein Split Brain erkennen
DRBD ist darauf ausgerichtet, sich bei einem Split Brain lautstark über diesen Zustand zu beschweren. Meistens fallen Probleme zuerst in Pacemaker auf: Weil sich eine DRBD-Ressource mit Split Brain partout nicht mehr von beiden Seiten aus verbinden lässt, ist die Ressource in Pacemaker als
» failed«
markiert. Ein Blick ins
»dmesg«
verschafft Klarheit: Findet sich darin eine Zeile wie
»Split-Brain detected but unresolved, dropping connection!«
, ist manuelle Intervention angesagt (
Abbildung 2
).
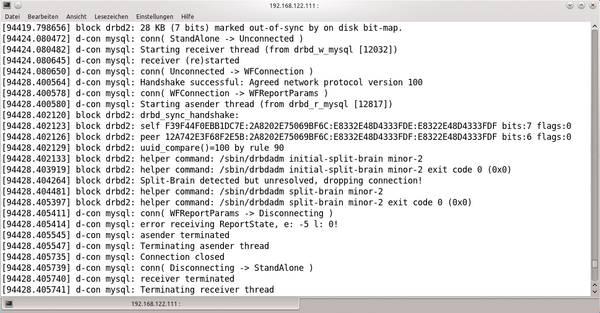 Abbildung 2: Das DRBD-Kernel-Modul beschwert sich im
Abbildung 2: Das DRBD-Kernel-Modul beschwert sich im
Der wichtigste Schritt für den Admin ist, das Victim und den Survivor festzulegen. Es steht die Frage im Mittelpunkt, mit welchem Datensatz der Cluster weiterarbeitet. Wegen der konkreten Eigenheiten von Setups sieht der Artikel an dieser Stelle von einer generellen Empfehlung ab. Stehen Victim und Survivor fest, ist der weitere Verlauf aber klar: Auf beiden Knoten ist zunächst
»drbdadm disconnect
Ressource
«
sinnvoll – das stellt sicher, dass von beiden Seiten keine Connect-Versuche mehr ausgehen.
Jetzt erfährt das Victim, dass es das Victim ist:
»drbdadm secondary
Ressource
«
sichert ab, dass sich die Ressource im
»Secondary«
-Modus befindet. Dann kommt der entscheidende Befehl auf dem Victim:
»drbdadm -- --discard-my-data connect
Ressource
«
weist die Ressource an, wieder einen Verbindungsversuch zu unternehmen und seine eigenen Daten zu verwerfen.
»drbdadm connect
Ressource
«
auf dem Survivor sorgt dafür, dass er wieder Connections akzeptiert. Im
»dmesg«
findet sich für die Ressource anschließend eine Meldung wie diese:
»Split-Brain detected, manually solved. Sync from this node«
(
Abbildung 3
). Der Split Brain ist repariert und der Normalzustand wiederhergestellt.
 Abbildung 3: … und nimmt die Arbeit erst wieder auf, nachdem der Admin das Problem händisch gelöst hat.
Abbildung 3: … und nimmt die Arbeit erst wieder auf, nachdem der Admin das Problem händisch gelöst hat.
Geisterhand bei der Clusterkonfiguration
Die alltäglichen DRBD-Probleme sind damit abgedeckt. Hinzu gesellen sich ein paar Schwierigkeiten im Zusammenspiel von Pacemaker und DRBD oder von Pacemaker mit anderen Cluster-Ressourcen. Ein häufig beobachteter Effekt ist beispielsweise, dass beim Anlegen neuer DRBD-Ressourcen die bereits in Pacemaker vorhandenen Ressourcen plötzlich Fehler anzeigen und der gesamte Cluster aus dem Tritt gerät.
Das Problem ist allerdings handgemacht. Es ist eine Mischung aus der Faulheit vieler Admins und einer etwas unglücklichen Verhaltensweise von
»drbdadm«
.
Häufig nehmen Admins für neue Ressourcen die Konfigurationsdateien von schon existierenden DRBD-Ressourcen und ändern diese entsprechend ab. Im Grunde spricht nichts gegen diese Technik, denn oft verwenden sämtliche Ressourcen auf einem System exakt die gleichen Parameter.
Unglücklich wird die Situation, wenn beim Anlegen der neuen Datei im Ordner
»/etc/drbd.d«
einfach eine existierende Datei kopiert wird und ihr Name auf
».res«
endet – das Standard-Suffix für Ressourcen.
Zumindest kurzzeitig liegen dann nämlich in diesem Ordner zwei Dateien mit der Endung, die eine identische Ressourcenkonfiguration haben. An dieser Stelle steigt
»drbdadm«
aus und gibt außer einer Fehlermeldung gar nichts mehr aus, bis das Problem behoben ist – und zwar ganz gleich, zu welcher Ressource es Informationen ausgeben soll (
Abbildung 4
).
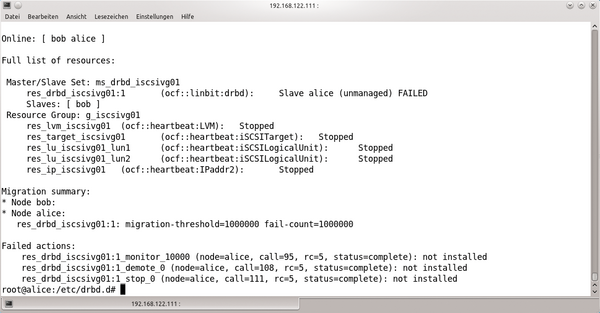 Abbildung 4: Wenn die Ressourcen im Cluster wie von Geisterhand außer Rand und Band geraten, ist oft eine kopierte DRBD-Konfigurationsdatei schuld.
Abbildung 4: Wenn die Ressourcen im Cluster wie von Geisterhand außer Rand und Band geraten, ist oft eine kopierte DRBD-Konfigurationsdatei schuld.
Das letzte Puzzleteil fügt Pacemaker selbst hinzu: Der Ressource-Agent von Linbit, mit dem sich DRBD-Ressourcen steuern und überwachen lassen, ruft
»drbdadm«
auf, wenn der
»monitor«
-Parameter angegeben wird. Solange die DRBD-Fehlkonfiguration vorliegt, wird aber auch Pacemaker mit einer Fehlermeldung abgespeist – und denkt, sämtliche Ressourcen seien plötzlich kaputt. Der Versuch, Ressourcen hektisch hin und her zu verschieben, ist selten von Erfolg gekrönt, und so bleibt der Cluster am Ende einer solchen Aktion häufig kaputt zurück.
Kurzfristig hilft der Cleanup-Befehl, sinnvoller ist aber Prävention: Wer neue Ressourcen auf Basis alter Konfigurationsdateien anlegt, gibt diesen idealerweise die Endung
».res.new«
und benennt sie erst um, wenn die Konfiguration tatsächlich ordentlich eingerichtet ist. Auf diese Weise bleiben unangenehme Effekte jedenfalls aus.
Ähnliche Artikel





Konfigurationsmanagement

Themen


