
Die Systemarchitektur des iSCSI-Clusters
Um die iSCSI-Funktion zu realisieren, braucht es auf dem iSCSI-Cluster ein passendes Storage-Setup. Der Storage-Controller stellt im Normalfall ein großes Device bereit, das den gesamten Platz der lokalen System-Platten enthält. Freilich ist es unsinnig, diesen gesamten Platz in ein DRBD-Laufwerk zu packen und das dann per iSCSI zu exportieren, denn so entfällt die Möglichkeit, den Platz in kleine Scheiben zu schneiden und bedarfsweise unterschiedlichen Aufgaben zu widmen. Sinnvoller ist es, LVM als zusätzliche Komponente mit aufzunehmen. Im Gegensatz zu den Setups, die im Rahmen der HA-Serie bisher dargestellt waren, liegt beim iSCSI-Cluster allerdings nicht das DRBD auf den LVM-Devices, sondern die Reihenfolge ist umgekehrt. Zwischen den beiden Knoten des iSCSI-Clusters gibt es ein paar DRBD-Ressourcen, die zusammen den gesamten Platz der Platten abdecken. Die DRBD-Konfiguration bleibt schlank, weil nicht für jede VM auf einem Virtualisierungsfrontend eine neue Ressource anzulegen ist.
Zudem entfällt mit dem vorgestellten Setup auch die Konfigurationsarbeit für neue DRBD-Ressourcen, wenn zu einem späteren Zeitpunkt eine neue VM auf den Frontends hinzukommt – das Anlegen einer neuen LV auf der vorhandenen LVM-Struktur geht auf der Kommandozeile viel schneller ( Abbildung 2 ). Streng genommen wäre es sogar möglich, bloß ein einziges, riesiges DRBD zu erzeugen und per LVM zu verwalten.
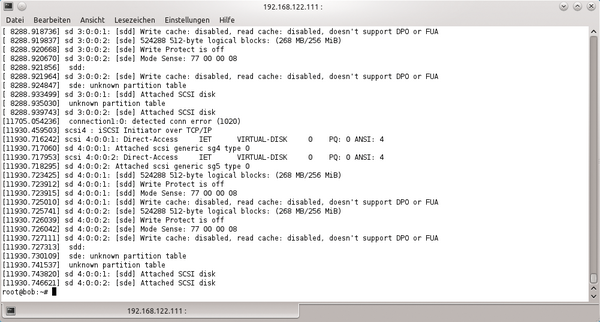 Abbildung 2: Ist ein Host an einem iSCSI-Target angemeldet, erscheint die Platte auf Linux-Systemen im
Abbildung 2: Ist ein Host an einem iSCSI-Target angemeldet, erscheint die Platte auf Linux-Systemen im
Mit dieser Herangehensweise zwingt man aber den Cluster in ein typisches Aktiv-Passiv-Setup, weil die DRBD-Ressource jeweils nur auf einem Cluster-Knoten aktiv sein kann. Fragmentiert man den HDD-Platz zumindest ein kleines Stück weit, ermöglicht man eine einfache Form des Load-Balancings für den Fall mit zwei verfügbaren beiden Cluster-Knoten.
Natürlich müsste man dann auch mit unterschiedlichen Service-IP-Adressen am Server und bei den Clients arbeiten. Außerdem gilt es, Over-Commitment zu verhindern: Ein einzelner Knoten muss stets die gesamte Last tragen können, damit der gesamte Cluster als HA-Cluster durchgeht.
Konkret sieht das Storage-Setup des iSCSI-Clusters also so aus: Ein großes Device wird vom Storage-Controller der beiden Knoten zur Verfügung gestellt, auf diesem liegen ein paar DRBD-Ressourcen, um die Redundanz der Daten zu erreichen. Die DRBD-Ressourcen sind die Physical Volumes von Volume Groups in LVM. Pacemaker aktiviert die VGs automatisch, nachdem auf einem Knoten ein DRBD-Laufwerk primär geworden ist. Die LVs der aktivierten VG exportiert ein iSCSI-Resource-Agent für Pacemaker schließlich in das lokale Netz.
Die Pacemaker-Konfiguration
Der Artikel geht im weiteren Verlauf davon aus, dass die beiden Knoten des iSCSI-Clusters bereits über ein Betriebssystem verfügen und dass sowohl DRBD wie auch der gesamte Cluster-Management-Stack – also Corosync oder Heartbeat plus Pacemaker – bereits installiert und grundlegend konfiguriert sind. Für iSCSI setzt der Artikel auf IET, das iSCSI Enterprise Target ( Abbildung 3 ). Die zwei Resource Agents (RAs), die in Pacemaker das iSCSI-Setup übernehmen, beherrschen aber jeweils auch LIO und STGT. Detaillierte Informationen hierzu finden sich im Hilfstext des RA.
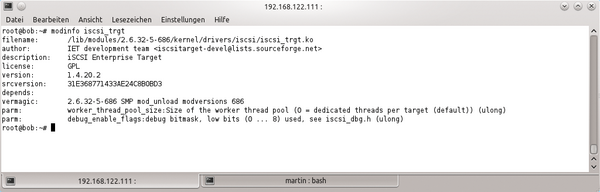 Abbildung 3: IET greift für seine Aufgaben auf den Kernel zurück, deshalb ist für den IET-Betrieb ein eigenes Kernel-Modul notwendig.
Abbildung 3: IET greift für seine Aufgaben auf den Kernel zurück, deshalb ist für den IET-Betrieb ein eigenes Kernel-Modul notwendig.
Ähnliche Artikel




Konfigurationsmanagement

Themen


