
GFS2 auf RHEL 6
Auf Red Hat Enterprise Linux 6 oder damit kompatiblen Distributionen gestaltet sich das GFS-Setup anders ( Abbildung 4 ). Die Control-Daemons, die Pacemaker mit dem DLM und dem GFS verbinden, fehlen. Stattdessen hat Pacemaker eine direkte Schnittstelle zu Cman. Auf solchen Systemen wird nicht Corosync gestartet, der das Pacemaker als Modul nachlädt – so, wie es im Rahmen der HA-Serie bisher stets war. Stattdessen läuft Pacemaker als Kindprozess von Cman und erhält von diesem alle wichtigen Infos.
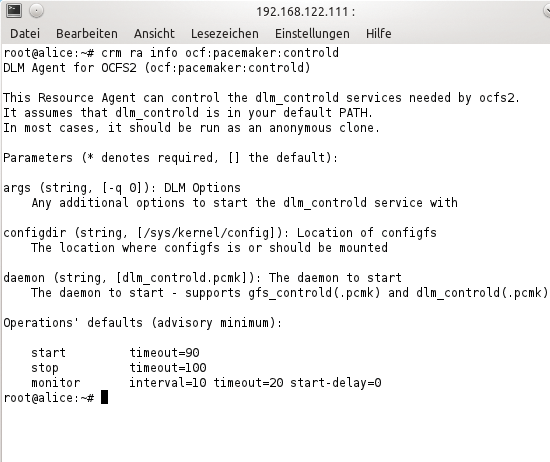 Abbildung 4: Der Resource-Agent
Abbildung 4: Der Resource-Agent
Die Konfiguration der DRBD-Ressource unterscheidet sich auf RHEL nicht von der zuvor beschriebenen Konfiguration für Debian, Ubuntu oder SLES. Auch auf RHEL sollte die DRBD-Ressource so eingerichtet sein, dass Dual-Primary geht. Wenn eine entsprechende DRBD-Konfiguration vorhanden ist, geht es mit der Konfiguration von Cman weiter, das im Normalfall erst zu installieren ist.
Cman für Pacemaker
Cman findet seine Konfiguration in
»/etc/cluster/cluster.conf«
. Die Datei verwendet – wie Pacemaker intern auch – eine XML-basierte Syntax, allerdings ist sie nur einmal zu editieren und funktioniert dann klaglos. Für das Pacemaker-Beispiel könnte
»cluster.conf«
so aussehen wie in
Listing 3
.
Listing 3
cluster.conf
Die Gefahren von DRBD im Dual-Primary-Modus
Der Betrieb einer DRBD-Ressource im Dual-Primary-Modus ist die zwingende Voraussetzung, um GFS2 auf dieser Ressource zu nutzen. Nicht zu unterschätzen sind dabei die Gefahren, die von dieser Art der DRBD-Benutzung ausgehen.
Standard-Dateisysteme
Dateisysteme existieren aus einem Grund: Sie machen Speicherplatz verwaltbar. Ohne ein Dateisystem wäre es schwierig, einmal auf das Speichermedium geschriebene Daten später wiederzufinden. Die Struktur des Dateisystems erlaubt es, Inhalte auf dem Datenträger erneut zu öffnen und zu verändern. Solange dem Dateisystem nichts in die Quere kommt, funktioniert dieses Prinzip ganz wunderbar. Und solange ein Datenträger konsistent ist, ist die Welt für den Admin in Ordnung.
Bei ihrer Arbeit gehen Dateisysteme grundsätzlich davon aus, dass nur sie überhaupt auf den Datenträger zugreifen dürfen, und zwar nur genau die Dateisystem-Instanz, die zu einem bestimmten Mount gehört. Der gleichzeitige Zugriff zweier Dateisystem-Instanzen auf denselben Datenträger ist in den Konzepten der Standard-Dateisysteme unter Linux nicht vorgesehen. Die in Linux enthaltenen Dateisysteme geben sich entsprechend große Mühe, gleichzeitige Datenträgerzugriffe durch zwei oder mehr Instanzen eines Dateisystems auszuschließen. Ein bereits gemountetes Dateisystem lässt sich nicht woanders nochmal mounten.
Solange der Datenträger nur einem einzigen System zur Verfügung steht, ist es für den Linux-Kernel kein Problem, dieses Prinzip aufrechtzuerhalten. Denn dort hat er die Deutungshoheit über die verfügbare Hardware. Im Falle von DRBD ist das aber nicht mehr der Fall: Die DRBD-Ressource ist grundsätzlich auf beiden Clusterknoten vorhanden, und der Ext3-Treiber von Knoten A hätte keine Möglichkeit, sich über den Zustand der gleichen DRBD-Ressource auf Knoten B zu informieren, wenn er schreibend darauf zugreift. Im schlimmsten Falle könnte es also passieren, dass auf beiden Seiten des Clusters auf die DRBD-Ressource geschrieben wird, wobei der jeweils andere Knoten von diesem Umstand vorerst gar nichts merken würde. Einen solchen Vorgang bezeichnet man als Concurrent Write. Wenn auf ein Medium von zwei Seiten gleichzeitig unkoordiniert geschrieben wird, ist sicher davon auszugehen, dass das Dateisystem Schaden nimmt. Admins holen dann die Backups raus, und Downtimes von Diensten gehören zu den unangenehmen Folgen.
Was tun?
DRBD schützt sich selbst gegen Concurrent Writes, indem es in der Standardkonfiguration stets im Primary-Secondary-Modus läuft. Auf dem Knoten, auf dem sich eine Ressource im Secondary-Modus befindet, sorgt der DRBD-Treiber dafür, dass kein Zugriff durch Userhand auf die Ressource stattfindet. Damit ist die Gefahr einer Korrumpierung des Dateisystems grundsätzlich gebannt. Der Nachteil: Cluster-Dateisysteme wie GFS oder OCFS2 beruhen auf dem Prinzip, dass sie auf sämtliche Datenträger innerhalb ihres Storage-Netzwerks uneingeschränkten Zugriff haben. Sie kümmern sich selbst darum, dass Concurrent Writes ausbleiben und sind somit auf die Schutzfunktion von DRBD nicht angewiesen. Damit GFS oder OCFS2 auf DRBD-Ressourcen funktionieren, muss DRBD also so konfiguriert sein, dass der schreibende Zugriff auf beiden Knoten für die Cluster-Dateisysteme möglich wird. Wie DRBD zu konfigurieren ist, ist in diesem Artikel ausführlich beschrieben.
Der Pferdefuß
Allerdings ist es nicht so, dass es völlig unproblematisch ist, DRBD-Ressourcen im Dual-Primary-Modus zu betreiben. Einerseits sind hinsichtlich der Clusterkonfiguration Details zu beachten: In einem Cluster, der DRBD-Ressourcen im Dual-Primary-Modus betreibt, ist ein funktionierendes STONITH-Setup Pflicht – denn sonst hat ein Knoten keine Möglichkeit, einen anderen Knoten aus dem Cluster zu werfen, wenn dieser Schwierigkeiten bereitet. Andererseits führt Fencing im Zusammenhang mit Clusterdateisystemen zu neuen Unannehmlichkeiten. Gelangt ein Knoten beispielsweise zur Überzeugung, dass ein anderer Knoten per STONITH abzuschießen sei, blockiert das Netzwerkdateisystem kurzerhand sämtlichen I/O-Traffic – und zwar auf allen Knoten, die zu einem Storage-Pool gehören – solange, bis der vermeintlich aus dem Tritt geratene Knoten sicher ausgeschlossen ist. Mit Blick auf die Performance kann das schnell zum Problem werden.
Angesichts der Nachteile, die der Dual-Primary-Modus hat, scheint es schwer nachvollziehbar, dass viele Setups von Anfang an auf eine solche Konfiguration setzen. Häufig finden sich im Netz zum Beispiel Clusteranleitungen, die verschiedene Konfigurationsdateien auf DRBDs mit Cluster-Dateisystemen legen, um diese auf beiden Clusterknoten parat zu halten. Eingedenk der enormen Komplexität, die dadurch zum Setup hinzukommt, ist Lösungen auf Basis von Csync2, Rsync oder auch Puppet/Chef allerdings der Vorzug einzuräumen. Ein Setup mit einem Cluster-Dateisystem sollte nur und ausschließlich dann überhaupt in Erwägung gezogen werden, wenn es dafür handfeste Gründe gibt. Denkbar wäre ein OCFS2-Setup für Oracle.
Übrigens: Mancher Einfaltspinsel glaubt, er könne Ext3 & Co. ein Schnippchen schlagen, indem er den Dual-Primary-Modus bei DRBD nutzt, um auf einer der beiden Seiten des Clusters dann im Read-Only-Modus auf das Dateisystem zuzugreifen. Davon ist strikt abzuraten: Dateisysteme unter Linux gehen davon aus, dass nur sie die vollständige Kontrolle haben. Daten, die auf einem Read-Only-FS im Cache landen, werden dort nicht mehr aktualisiert – schließlich glaubt der Dateisystemtreiber, dass sie sich zwischenzeitlich nicht ändern können. Selbst wenn in diesen Szenarien also das Dateisystem nicht korrumpiert wird, so bekommen Clients beim Lesezugriff dort nach einer kurzen Zeit vermutlich keine aktuellen Daten mehr geliefert.
Das genannte Beispiel enthält auch Fencing-Direktiven, die Cman dazu bringen, Fencing-Requests jedweder Art direkt an Pacemaker weiterzuleiten. Die
»clusternode«
-Einträge beziehen sich auf die Knoten des Clusters, statt
»pcmk-1«
und
»pcmk-2«
sollten die tatsächlichen Namen der Cluster hier erscheinen.
Wenn die Cman-Konfigurationsdatei eingerichtet ist, gilt es, den dazugehörenden Dienst zu starten:
»service cman start«
. Der Output auf der Kommandozeile sollte aussehen, wie in
Abbildung 5
. Deutlich ist zu erkennen, dass Cman selbst sowohl den Control-Daemon für DLM als auch den für GFS startet. Anders als bei der Variante für Debian & Co. sind auf RHEL-kompatiblen Systemen diese Dienste also kein Teil der CIB mehr, über die Pacemaker wacht.
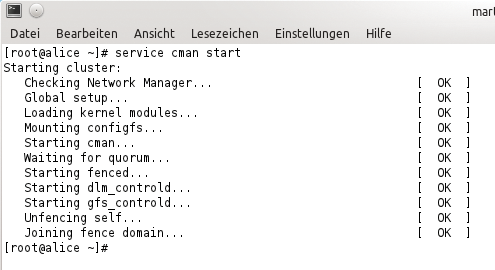 Abbildung 5: service cman start
Abbildung 5: service cman start
Ähnliche Artikel





Konfigurationsmanagement

Themen


