
Ausgangsparameter
Um die Systemperformance messen zu können, wurden im Test drei Messgrößen bestimmt:
Nagios Latency: Das Planen der Ausführzeitpunkte der einzelnen Checks ist eine komplexe Angelegenheit, weil nicht sämtliche Überprüfungen gleichzeitig auszuführen sind. Dies hätte eine sehr ungleichmäßige Auslastung des Systems zur Folge. Aus diesem Grund verfügt der Nagios Core über einige Intelligenz, die dieses Verhalten steuert. Wie gut der Core diese Ausführzeitpunkte anpassen kann, wird durch die Nagios Latency gemessen. Sie bezeichnet die Differenz zwischen einem geplantem Ausführzeitpunkt eines Checks und dem tatsächlichen. Ist dieser Wert zu hoch, kommt das System bei steigender Menge an Checks nicht mehr nach. Die Liste der noch abzuarbeitenden Checks wird zu hoch, es können nicht mehr alle konfigurierten Überprüfungen auch wirklich durchgeführt werden.
CPU-Load: Als klassisches Mittel zur Bestimmung der CPU-Auslastung hat sich die Anzahl der auf CPU-Zeit wartenden Prozesse etabliert. Gemeinsam mit der Anzahl der Prozesse, die gerade laufen, und jener, die auf I/O Zeit warten, bildet sie den sogenannten Load Average des Linux-Systems. Als grober Richtwert gilt: Liegt diese Zahl unter der Anzahl der im System verbauten CPU-Cores, ist alles im grünen Bereich.
Da bei einigen Technologievergleichen auch die Verteilung der CPU-Zeit auf Prozesse im Kern beziehungsweise User Space interessant ist, wird an manchen Stellen diese Metrik verwendet.
Memory: Neben der CPU-Belastung ist natürlich auch die Auslastung des Arbeitsspeichers ein interessanter Messwert in Linux-Systemen. Das Augenmerk gilt hier der Menge des durch eine Applikation maximal belegbaren Speichers, den man näherungsweise ermitteln kann, indem man vom
»Used«
-Wert die Werte für
»Buffer«
und
»Cached«
abzieht.
Die Simulation
Die Simulation soll das zu messende System selbst möglichst wenig beeinträchtigen. Im vorliegenden Fall sollen sich alle Input-Parameter verändern lassen und der CPU- und Speicherverbrauch dennoch möglichst gering sein. Gefragt ist also ein Plugin, das flexibel und CPU-günstig zugleich arbeitet. Der Autor hat sich für eine Eigenentwicklung in Perl entschieden. Dieses Plugin wird in der Nagioskonfiguration an virtuelle Servicechecks gebunden, die Servicechecks wiederum laufen auf virtuellen Hosts.
define command{
command_name check_ok
command_line /usr/lib/nagios/plugins/sampler_do_nothing.pl $HOSTNAME$ $SERVICEDESC$
}
So wird das Perlskript im System eingebunden. Wichtig sind die Parameter
»$HOSTNAME$«
und
»$SERVICEDESC$«
, die dem Plugin mitteilen, für welchen Host/Service es gerade die Simulation übernehmen soll. Dies ist insofern relevant, als eine gewisse Streuung der Ereignisse in der Simulation erwünscht ist. Es wäre realitätsfern, wenn alle Checks zur exakt selben Zeit von
»OK«
auf
»Warning«
beziehungsweise
»Critical«
wechseln würden oder wenn die Durchlaufzeit eines Checks immer gleich wäre.
Abbildung 2 erläutert den Ablauf im Detail. Wird das Plugin das erste Mal in der entsprechenden Host/Service-Kombination aufgerufen, berechnet es eine Verschiebung des Zeitpunktes des Statuswechsels. Dadurch wird, in bestimmten Grenzen, festgelegt, in welchem Rhythmus die einzelnen Statuscodes zu durchlaufen sind.
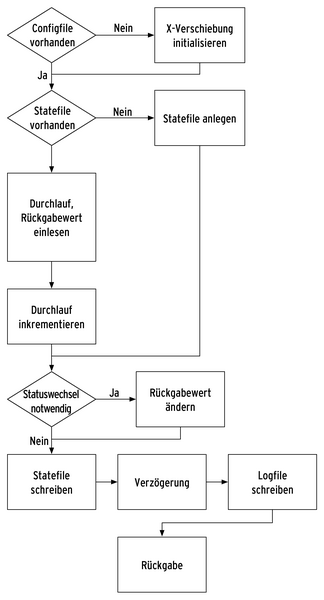 Abbildung 2: Der für die Messungen verwendete Simulator als Flussdiagramm.
Abbildung 2: Der für die Messungen verwendete Simulator als Flussdiagramm.
Für die Messung systemnaher Werte wie der CPU-Load wurde das Tool Sar aus dem Sysstat-Paket verwendet. Es speichert im Abstand von fünf Sekunden kontinuierlich Messwerte, die dann später mit
»sadf«
in ein CSV-Format umgewandelt und an Gnuplot zur grafischen Darstellung weitergegeben wurden.
Ähnliche Artikel
- Notizen von der vierten Open Source Monitoring Conference (OSMC)
- Notizen von der siebenten Open Source Monitoring Konferenz
-
Monitoring-Gipfel
Eine Zwischenbilanz des Icinga-Projekts gehört mittlerweile zur Tradition der Nürnberger Open Source Monitoring Conference (OSMC). Daneben boten aber auch wieder viele andere Vorträge interessante Einsichten.
- Ein neuer Nagios-Fork bietet bereits vielversprechende Features
-
Von Nagios abgeleitete Monitoring-Lösungen im Vergleich

Konfigurationsmanagement

Themen


