
Schmutzeffekte in der Datenbank
Dieser Punkt ist am schwersten zu beherrschen, denn eigentlich hat die Datenbank alles richtig gemacht, und trotzdem sind die Daten falsch. Das kommt dann vor, wenn zwei Systeme Daten ohne Konvertierung übertragen. Wurde beispielsweise die Datenbank mit dem Zeichensatz
»WE8MSWIN1252«
erstellt und auf einem beliebigen Client (zum Beispiel auf der Kommandozeile unter DOS) die Variable
»NLS_LANG=GERMAN_GERMANY.WE8MSWIN1252«
eingestellt, dann geht die Datenbank davon aus, dass keine Zeichenkonvertierung notwendig ist, da ja beide Zeichensätze identisch sind. Für den DOS-Client sieht es jetzt bei der Abfrage so aus, als ob die Zeichen richtig dargestellt würden, denn auf dem Rückweg werden sie ja ebenfalls nicht konvertiert. Bei der Abfrage mit einem Windows-Client (etwa mit dem Tool DELL Toad for Oracle) stellen wir allerdings plötzlich fest, dass irgendwelche Hieroglyphen gespeichert wurden (
Abbildung 1
).
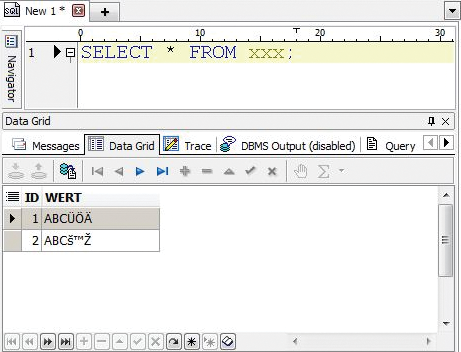 Abbildung 1: Fehlerhafte Zeichendarstellung nach einer Datenübertragung ohne Konvertierung.
Abbildung 1: Fehlerhafte Zeichendarstellung nach einer Datenübertragung ohne Konvertierung.
Dieser Fehler kann nur durch Entladen der Daten über eine entsprechende Schnittstelle und anschließendes erneutes Laden mit dem "richtigen" Zeichensatz behoben werden. Die Migration wird dadurch erheblich erschwert. Glücklicherweise sind diese Fehler heute eher selten anzutreffen, weil sie dank der grafischen Werkzeuge schnell erkennbar sind.
Die Migration
Die eigentliche Migration erfolgt in vier Schritten ( Abbildung 2 ):
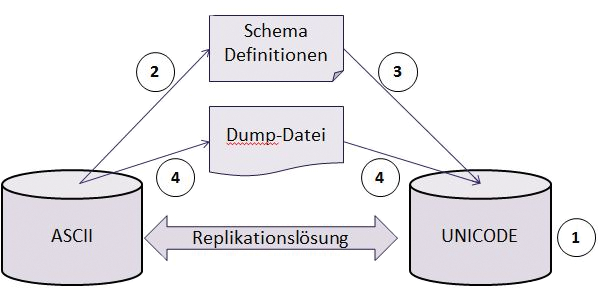 Abbildung 2: Schematische Darstellung einer Migration.
Abbildung 2: Schematische Darstellung einer Migration.
- Aufbau einer neuen Datenbank. Die neue Datenbank wird entsprechend den Vorgaben des Unternehmens und von Oracle mit dem neuen Zeichensatz (in der Regel
»
AL32UTF8« ) aufgebaut. Als angenehmer Nebeneffekt ergibt sich dabei, dass sich die Datenbank komplett reorganisieren lässt, das heißt überflüssige Daten, die etwa durch die Installation von Beispielschemata in die Datenbank gelangten, kann man jetzt eliminieren. - Exportieren der Schemadefinitionen als ASCII-Datei. Danach exportiert man die Schemadefinitionen (
Abbildung 3
) ohne Längensemantik als ASCII-Datei. Dadurch ergibt sich die Möglichkeit, anschließend eine Bereinigung vorzunehmen. Oracle bietet hierfür ein Package mit dem Namen
»
dbms_metadata« an. Der Autor hat sehr gute Erfahrungen mit Toad for Oracle gemacht, da das Tool über eine grafische Schnittstelle ganz einfach die komplette Definition auch mehrerer Schemata als ASCII-Datei erstellt und in den Editor kopiert. Über »find« und »replace« lassen sich dann gegebenenfalls Änderungen (zum Beispiel Umstellung von »NVARCHAR2« auf »VARCHAR2« ) durchführen.
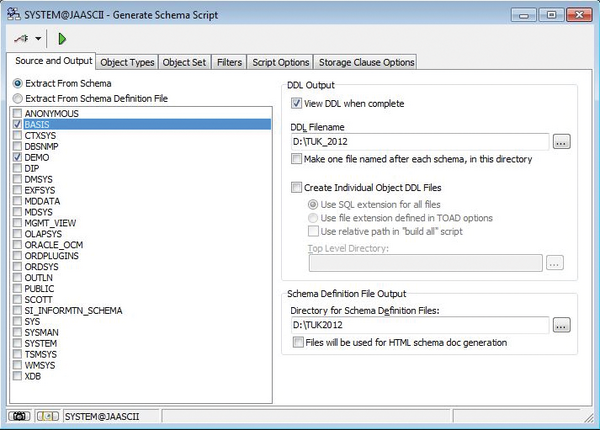 Abbildung 3: Export eines Datenbankschemas als ASCII-Datei.
Abbildung 3: Export eines Datenbankschemas als ASCII-Datei.
- Importieren der Schemadefinitionen. Das eben erstellte Skript mit der Schemadefinition wird dann in der neuen Datenbank ausgeführt. Vorher setzt man allerdings für die gesamte Session den Parameter
»
NLS_LENGTH_SEMANTICS« :
SQL> ALTER SESSION SET NLS_LENGTH_SEMANTICS=CHAR;
Damit wird dafür gesorgt, dass allen Zeichen-Spalten (also
»CHAR«
,
»VARCHAR2«
, etc.), die keine explizite Längensemantik verwenden,
»CHAR«
als Längensemantik zugewiesen wird. Damit passen die Umlaute auch wieder in die Felder.
- Datensätze importieren. Als Letztes werden die Datensätze, also die Inhalte der Tabellen einfach per Export / Import oder Data Pump übertragen. Beim Importieren der Daten ist darauf zu achten, dass die Befehle ignoriert werden, die die Tabellen erstellen würden, denn die gibt es ja schon. Außerdem müssen die Foreign-Key-Contraints ausgeschaltet werden, da die Reihenfolge des Einfügens der Daten nicht festgelegt werden kann. Ansonsten könnte es dazu kommen, dass ein Detail-Datensatz (zum Beispiel die Adresse einer Person) nicht eingefügt werden kann, weil die Daten der Person selbst (also Vorname, Nachname, etc.) noch nicht vorhanden sind. Beim Importieren interessieren wir uns aber nur dafür, dass ganz am Ende alle Daten eingefügt sind, dann sollten die Personen zu den Adressen passen.
Ähnliche Artikel
-
Oracle Database 12c: Cloud Computing mit Multitenant-Architektur

- Binärdaten in der Bash-Shell verarbeiten
-
ADMIN-Tipp: Byte Order Mark in UTF-8
Eine weitere Folge aus der Reihe "Unsichtbare Zeichen machen großen Ärger" beschäftigt sich mit dem berüchtigten BOM in Unicode-Dateien.
-
Neues Perl Major Release ist da
Nach einem Jahr Entwicklungszeit ist jetzt das nächste Major Release von Perl 5 erscheinen. Perl 5.16 enthält im Verleich zum Vorgänger 5.14 rund 590 000 Änderungen in 2500 Files, die 139 Autoren beisteuerten.
-
ADMIN-Tipp: Unsichtbare Zeichen in Textdateien
Unicode-Zeichen in Textdateien bescheren Anwendern auch im Jahr 2012 noch oft Probleme. Zu dumm, wenn der Editor sie nicht einmal anzeigt und man deshalb bei der Fehlersuche im Dunkeln tappt. Eine wahre Geschichte aus der ADMIN-Redaktion ...
Konfigurationsmanagement

Themen


