Troubleshooting & Maintenance in Ceph

Erste Hilfe

Die Zahl der von Ceph begeisterten Admins wächst stetig. Wer bereits einen Ceph-Cluster sein Eigen nennt, sieht sich nicht selten in die rauhe Welt der Systemadministration zurückversetzt: Zwar sind in Ceph verschiedene Funktionen integriert, welche die Arbeit mit dem Objectstore so angenehm wie möglich machen sollen. Doch so viel steht fest: Auch bei Ceph-Clustern gehen Dinge schief, sterben Festplatten und laufen andere Festplatten voll. Der vorliegende Artikel setzt an, Admins zumindest bei den wichtigsten Alltagsthemen Tipps an die Hand zu geben, damit sie im Falle eines Falles wissen, was zu tun ist.
Wie es dem Cluster geht
Aus administrativer Sicht ist natürlich zunächst interessant, wie es dem Cluster im Augenblick eigentlich geht. Ceph bietet gleich mehrere Wege, an Status-Informationen zum Cluster zu kommen. Der eingängigste Befehl lautet zweifellos
»ceph health«
. Dieser erzeugt im Idealfall nur eine einzige Zeile als Ausgabe, nämlich
»HEALTH_OK«
(
Abbildung 1
). Der Administrator kann dieser einzelnen Zeile gleich mehrere Informationen entnehmen: Sämtliche Platten (OSDs) des Clusters verhalten sich laut Ceph augenblicklich normal, es gibt ebenso keine Ausfälle bei den Monitoring- oder Metadata-Servern (falls die lokale Installation letztere überhaupt nutzt). Und nicht zuletzt sagt die bezeichnete Zeile natürlich aus, dass sämtliche Placement-Groups in Ceph im Sinne der Replikationsregeln korrekt funktionieren.
 Abbildung 1: Wie der mittels ceph -w zu erreichende Watch-Mode verrät, ist bei diesem Cluster HEALTH_OK angesagt – alles in Ordnung!
Abbildung 1: Wie der mittels ceph -w zu erreichende Watch-Mode verrät, ist bei diesem Cluster HEALTH_OK angesagt – alles in Ordnung!
Ist die Ausgabe nicht
»HEALTH_OK«
sondern
»HEALTH_WARN«
oder gar
»HEALTH_ERR«
, sieht die Welt nicht ganz so rosig aus. Es ist dann im Sinne des Administrators, genauere Informationen zum Zustand des Clusters zu bekommen. Dafür bietet sich der Befehl
»ceph health detail«
an, der im Falle von
»HEALTH_OK«
keine weitere Ausgabe produziert, das aber bei
»HEALTH_WARN«
und
»HEALTH_ERR«
durchaus tut (
Abbildung 2
). Wie unterscheiden die einzelnen Zustände sich voneinander?
 Abbildung 2: ceph health detail verrät nicht nur, dass es ein Problem gibt, sondern sagt auch dazu, was genau das Problem gerade ist.
Abbildung 2: ceph health detail verrät nicht nur, dass es ein Problem gibt, sondern sagt auch dazu, was genau das Problem gerade ist.
»HEALTH_WARN«
verrät dem Administrator zunächst, dass es ein Problem mit den Placement Groups gibt. Placement Groups können verschiedene Zustände haben, einige davon lösen den Warn-Status aus: Generell ist das immer so, wenn die vom Administrator festgelegten Replikationseinstellungen nicht mehr erfüllt sind. Ein
»HEALTH_WARN«
ist allerdings nicht unbedingt ein Grund zur Sorge. Fällt beispielsweise ein OSD innerhalb des Clusters aus, würde in der Standardkonfiguration nach 5 Minuten der Zustand des Clusters ganz automatisch in
»HEALTH_WARN«
übergehen, weil es innerhalb des Speichers dann fehlende Replikas gibt – eben jene, die auf der ausgefallenen OSD zu finden waren. Sobald die Self-Healing-Prozedur abgeschlossen ist, würde der Zustand allerdings automatisch wieder in
»HEALTH_OK«
wechseln. Einen detaillierten Überblick über die wichtigsten Zustände von Placement Groups in Ceph finden Sie im Kasten Placement-Group-Statusmeldugen.
Wirklichen Grund zur Sorge hat der Administrator in dem Augenblick, in dem der Zustand des Ceph-Clusters auf
»HEALTH_ERR«
schwenkt. Denn dann steht fest: Es gibt ein Problem innerhalb des Clusters, das Ceph alleine nicht mehr lösen kann und dass das Eingreifen eines Admins nötig macht. Was der Admin tun kann, erfährt er mittels des schon erwähnten
»ceph health detail«
. Anhand der Liste im Kasten Placement-Group-Statusmeldugen und der Ausgaben des Befehls kann der Admin schließen, welche Vorgehensweise sinnvoll ist.
Für die genauere Fehleranalyse ist insbesondere der Teil des Health-Status relevant, der den aktuellen Zustand von Monitoring-Servern und OSDs im Detail beschreibt. Wenn Placement Groups als
»Stale«
oder gar als
»Down«
markiert sind, liegt das oft daran, dass dem Cluster gleich mehrere OSDs abhanden gekommen sind: Zwei Festplatten haben in zwei voneinander unabhängigen Servern den Geist aufgegeben. Viel häufiger entstehen solche Szenarien, wenn im Cluster mit der Netzwerk- oder Stromverbindung etwas nicht stimmt. Manchmal fallen auch mehrere Rechner gleichzeitig durch dieselbe Ursache aus; solch ein Vorgang würde in der Ceph-Status-Ansicht ganz ähnlich aussehen. Wichtig für den Admin ist, dass er schnellstmöglich die OSDs mit den fehlenden PGs wieder online bringt. Welche OSDs fehlen, ergibt sich aus der OSD-Zeile von
»ceph health detail«
.
Analog zu
»ceph health«
stellt Ceph übrigens auch einen Watch-Mode zur Verfügung. Der funktioniert im Grunde ganz ähnlich, zeigt aber einen stetig fortlaufenden Status-Bericht an, der sich Ereignis-basiert aktualisiert. Per
»ceph -w«
erscheint er im Terminal.
Auf OSD-Probleme richtig reagieren
Wenn sich als Ursache für ein Problem in Ceph Schwierigkeiten mit einem oder mehreren einzelnen OSDs herausstellen, fängt für den Administrator die Arbeit erst an. Der einfachste Fall ist noch der, bei dem der Cluster oder einzelne OSDs desselben einfach volllaufen: Im spezifischen Fall würde es nämlich genügen, neue Festplatten in den Cluster zu übernehmen. Wichtig ist für den Administrator insbesondere das Verständnis, dass nicht alle OSDs im Cluster voll sein müssen, damit der Cluster seine Aufgaben nicht länger wie erhofft wahrnehmen kann. Ceph schlägt bereits Alarm, wenn es davon ausgeht, in Kürze seine Replikations-Policy nicht mehr erfüllen zu können.
Das Hinzufügen neuer OSDs geht – am Beispiel einer einzelnen Platte in einem fiktiven Host Charlie – wie folgt:
Zunächst gilt es herauszufinden, welche ID das neue OSD haben wird. Es genügt hierfür, die ID des aktuell höchsten OSDs herauszufinden. Dazu hilft der Befehl
»ceph osd tree«
(
Abbildung 3
). Im konkreten Beispiel sei die derzeit letzte OSD im Cluster
»osd.2«
, also das OSD mit der ID 2 (die Zählung beginnt bei 0).
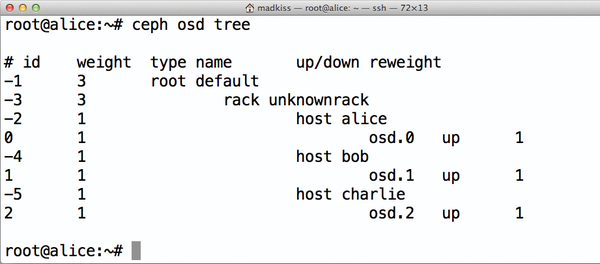 Abbildung 3: ceph osd tree zeigt die aktuelle OSD-Struktur des Clusters an und erlaubt auch, die nächste freie OSD-ID herauszufinden.
Abbildung 3: ceph osd tree zeigt die aktuelle OSD-Struktur des Clusters an und erlaubt auch, die nächste freie OSD-ID herauszufinden.
Das nächste OSD ist folglich das OSD mit der ID 3. Auf Charlie ist dann im ersten Schritt das OSD-Verzeichnis anzulegen:
»mkdir -p /var/lib/ceph/osd/ceph-3«
.
Das Beispiel geht davon aus, dass das neue OSD auf dem Host Charlie die HDD
»/dev/sdc«
ist. Auf die gehört zunächst ein Dateisystem:
»mkfs.xfs -L osd.3 -i size=2048 /dev/sdc«
. Dann landet das neue Dateisystem in
»fstab«
, damit es beim Systemstart automatisch aktiv wird. Ein beispielhafter Eintrag, der sich auf das gesetzte Label bezieht, wäre
LABEL=osd.3 /var/lib/ceph/osd/ceph-3 xfs defaults 0 0
»mount -a«
aktiviert das neue Dateisystem sofort. Dann kann das neue OSD auch in
»/etc/ceph/ceph.conf«
auf einem der Rechner landen, die schon Teil des Clusters sind – im Beispiel der Host
»Daisy«
. Weil das Beispiel sich an die Standardpfade hält, genügt der Eintrag
[osd.3]
host = charlie
Die neue
»ceph.conf«
sollte im Anschluss auf alle Hosts kopiert werden, auf denen bereits aktive OSDs vorhanden sind; ebenfalls sollte sie auf Charlie landen. Falls noch nicht geschehen, empfiehlt es sich auch, den Zugangs-Key für
»client.admin«
von einem alten OSD-Host auf Charlie zu kopieren:
»scp root@daisy:/etc/ceph/keyring.admin /etc/ceph«
auf Charlie erledigt das. Durch das Kopieren lassen sich alle weiteren Schritte der Anleitung auf Charlie durchführen – ginge das nicht, wäre ein ständiges Wechseln zwischen einem der vorhandenen OSD-Hosts und Charlie notwendig.
»ceph osd create«
legt Ceph-intern das neue OSD an.
»ceph-osd -i 3 --mkfs --mkkey«
erstellt anschließend die OSD-Struktur auf der neuen Platte und generiert für das neue OSD einen CephX-Schlüssel, der sogleich in den existierenden Keyring zu laden ist:
ceph auth add osd.3 osd 'allow *'mon 'allow rwx' -i/var/lib/ceph/osd/ceph-3/keyring
Schließlich erhält das neue OSD noch einen Wert in der Crushmap, welcher es für die Benutzung freigibt:
ceph osd crush set osd.3 1.0 rack=unknownrack host=charlie
Es folgt der Start des OSDs auf Charlie mittels
»service ceph start«
– ab sofort wird der Ceph-Cluster die neue Platte in die Crush-Kalkulation mit einbeziehen und Daten dort ablegen.
Ähnliche Artikel





Konfigurationsmanagement

Themen


