Malware analysieren und bekämpfen

Code-Kontrolle

Die potenzielle Gefahr von Malware bleibt eine Sorge, die viele Computer-Benutzer umtreibt. Der Desktop-PC, das Smartphone bis hin zu den netzwerkfähigen Kleingeräten rund ums Haus und Büro sind potenziell anfällig für tausende Rootkits, Spyware und Trojaner. So schnell Antivirenhersteller neue Methoden entwickeln, um Malware zu entdecken und abzuwehren, so schnell entwickeln Virenhersteller neue Methoden, um diese Absicherungen zu umgehen.
Linux-Benutzer profitieren seit Langem von der minimalen Aufmerksamkeit, die Virenentwicklern ihrem Betriebssystem schenken. Zwar existiert Malware auch für ihre Plattform, aber die meisten Linux-Systeme bleiben ihr verschlossen, denn eine der großen Stärken quelloffener Software besteht in der Geschwindigkeit, mit der sicherheitsrelevante Fehler bemerkt, diagnostiziert und repariert werden. Diese gute Reaktionsfähigkeit begrenzt das Zeitfenster, in dem bösartige Software Anfälligkeiten ausnutzen kann. Nur wenn es einer Malware gelingt, einen Benutzer mit Superuser-Rechten zur freiwilligen Installation zu überreden oder ein System nicht korrekt konfiguriert oder aktualisiert ist, kann sie einen Linux-Rechner infizieren.
Windows-Benutzer haben weniger Glück. Auf über einer Milliarde PCs weltweit laufen verschiedene Windows-Varianten und seine sehr große Verbreitung macht das Betriebssystem zu einem verlockenden Ziel für Virenentwickler. Die Größe und Komplexität der Windows-Codebasis sowie Verzögerungen bei der Fehlerbehebung führen zu einladenden Einfallstoren für Malware-Programmierer.
Doch Windows stehen zwei ungewohnte Verbündete im Kampf gegen Malware zur Seite: Linux und Open-Source-Software. Zahlreiche Linux-Tools kommen zum Einsatz, um Analysen von Windows-Malware zu erstellen und Software-Qualität zu erhöhen. Entwickler verwenden diese Werkzeuge, um besseren und sichereren Code zu schreiben, während sie Forschern zu neuen Erkenntnissen über die Vorgehensweise von Malware verhelfen.
Diese Software-Analysewerkzeuge fallen in zwei Kategorien: statische und dynamische. Statische Tools untersuchen den Binär- oder den Sourcecode eines Programms, um herauszufinden, wie es strukturiert ist und wie es auf bestimmte Eingabewerte reagiert. Dynamische Analysewerkzeuge beobachten eine Software hingegen während der Ausführung, um ihr Laufzeitverhalten direkt unter die Lupe zu nehmen. Beide Methoden haben ihre Stärken und Schwächen, sind aber in jedem Fall sehr nützlich, um unbekannte Software zu untersuchen. Dieser Artikel führt die für die Analyse verwendeten Konzepte ein und zeigt einige Werkzeuge, mit denen Sicherheitsforscher Malware analysieren.
Statische Analyse
Statische Softwareanalyse gibt es schon sehr lange und viele ihrer Methoden gehören zum Standardrepertoire von Entwicklern: Denn bereits das Kompilieren von Quellcode stellt eine Form der statischen Analyse dar. Jeder Compiler setzt während des Übersetzens auch Analysetechniken ein, um doppelt verwendete Variablen-, Klassen- und Funktionsnamen, falsch typisierte Zuordnungen, uninitialisierte Variablen und unerreichbare Anweisungen zu entdecken.
Das CLang-Frontend [1] für die LLVM-Compiler-Infrastruktur verfügt über einen leistungsfähigen statischen Analyser, der sehr detaillierte Compiler-Fehler und -Warnungen ausgibt. Analyse-Plugins [2] erweitern inzwischen die ohnehin hilfreiche Standardanalysekomponente von GCC. Unterstützung für sie liefert GCC ab Version 4.5.
Jedes Programm enthält Gruppen von Anweisungen, die es sequenziell ausführt, wenn keine Exceptions oder Sprünge auftreten. Bei der Ausführung arbeitet das Programm diese Anweisungen als logische Blöcke ab, in der Compiler-Terminologie heißen sie
»Basic Blocks«
. Ist die Ausführung eines Basic Blocks abgeschlossen, geht die Kontrolle an einen anderen über und der Programmablauf geht dort weiter. Das Ende eines Basic Blocks liegt typischerweise an einer Sprunganweisung oder an einer bedingten Verzweigung.
Die statische Analyse versucht all diese Basic Blocks zu entdecken und zu bestimmen, an welchen Stellen die Kontrolle von einem zum nächsten übergeht. Diese Information wird gesammelt und als Control Flow Graph (CFG) repräsentiert, der den Gesamtablauf eines Programms beschreibt. Listing 1 zeigt eine einfache C-Funktion und Abbildung 1 den CFG, der ihre Basic Blocks und ihren Kontrollfluss beschreibt.
Listing 1
Eine einfache C-Funktion
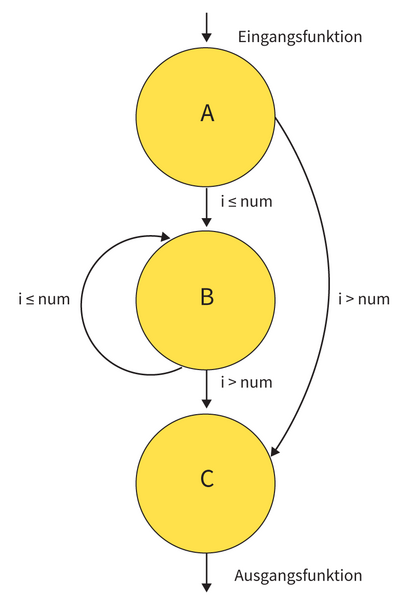 Abbildung 1: Der Control Flow Graph (CFG) für die C-Funktion simple in Listing 1.
Abbildung 1: Der Control Flow Graph (CFG) für die C-Funktion simple in Listing 1.
Die statische Analyse dieser Funktion teilt den Code in die drei Basic Blocks A, B und C auf. Der Graph zeigt, dass der Kontrollfluss A und C garantiert durchläuft, weil diese beiden Basic Blocks Ein- und Ausgang der Funktion bilden. B muss gar nicht, kann aber auch mehrere Male ausgeführt werden. Die Visualisierung des Kontrollflusses in dieser Beispielfunktion ist einfach, doch bei komplexeren Funktionen ergeben die CFGs schnell ein weniger überschaubares Bild.
Alle Daten, die in eine Funktion hineinfließen, entstammen irgendeiner bestimmten Quelle, beispielsweise einer Datei, Netzwerkkommunikation oder Eingabegeräten wie der Tastatur oder Maus. Daten, die aus einer nicht vertrauenswürdigen Quelle stammen, beispielsweise einer Netzwerkverbindung, gelten ebenfalls als nicht vertrauenswürdig.
Manche Basic Blocks enthalten heikle Anweisungen, etwa Speicherzuweisungen, Dateizugriffe oder Socket-Kommunikation. Wenn Daten aus einer unsicheren Quelle mit solchen Aufrufen interagieren, besteht die Möglichkeit eines kompromittierbaren Basic Block. Die CFG-Visualierung hilft dabei, Blöcke aufzuspüren, die nicht vertrauenswürdige Daten generieren, Systemaufrufe tätigen und herauszufinden, wie diese miteinander verbunden sind. Darin besteht das Hauptziel statischer Analyse: Wo und wie können nicht vertrauenswürdige Daten möglicherweise störanfällige Ereignisse auslösen?
Ist der Quellcode verfügbar, ist die statische Analyse relativ unkompliziert, denn er liefert eine vollständige und eindeutige Definition der Datentypen, Funktionsaufrufe und Kontrollflussstrukturen. Allerdings bleibt der Quellcode von Malware oft verborgen. Um ihr Verhalten zu analysieren, muss also der Binär-Code genügen. Zwar ist die schrittweise Analyse der binären Anweisungen möglich, wie zahlreiche Malware-Studien bewiesen haben, doch die Analyse auf der Ebene einer Quellcode-Repräsentation des dekompilierten Binär-Codes bringt häufig mehr Erkenntnisse.
Dazwischen steht jedoch die schwierige Aufgabe, die Quellcode-Repräsentation aus einer Binärdatei zu generieren. Ein Decompiler muss erkennen, in welchen Abschnitten Code steht, wo die Daten lagern sowie komplexe Datentypen rekonstruieren. Kein Decompiler generiert Quellcode in der Qualität des originären Codes, aus dem die Binärdatei kompiliert wurde. Manuelles Eingreifen ist häufig unverzichtbar, um die Rückübersetzung vollständig und eindeutig abzuschließen. Für Linux existieren mehrere Open-Source-Decompiler, unter denen Boomerang [3] die wohl besten Ergebnisse liefert. Das Programm befindet sich unter aktiver Entwicklung und generiert vergleichsweise guten C-Code aus ausführbaren Binärdateien.
Bytecode-basierte Java-Klassen sind deutlich einfacher zu dekompilieren als native Binaries, weil ihre Bytecode-Anweisungen umfangreiche Kontextinformationen enthalten, zum Beispiel zu Vererbung und Datentypen. Zum Dekompilieren von Java-Klassen verwenden viele Sicherheitsforscher das Open-Source-Werkzeugset Soot [4] ; es gibt daneben aber zahlreiche weitere Linux-Tools.
Dare (Dalvik Retargetting,
[5]
) verwandelt die
»dex«
-Dateien einer Android-Dalvik-VM in Java-
».class«
-Dateien. Für Java-Bytecode ausgelegte Tools verarbeiten und dekompilieren diese weiter.
Dynamische Analyse
Auch wenn statische Analyse viele Strukturen offenlegt, löst sie selten Probleme, die mit der Parallelisierung mehrerer Threads zusammenhängen. Könnte statische Analyse in diesem Bereich helfen, dann gäbe es bereits Compiler, die Race Conditions und andere typische Probleme in der parallelen Programmierung erkennen würden. Des Weiteren liegt Malware gewöhnlich in Form komprimierter oder verschlüsselter Binaries vor, was eine weitere Hürde für die Dekompilierung und statische Analyse einschiebt.
Derlei Beschränkungen machen die Beobachtung des Laufzeitverhaltens, die dynamische Analyse, in manchen Fällen zur einzigen Möglichkeit, Malware zu analysieren. Die dynamische Analyse findet auf vielen verschiedenen Ebenen statt, von der Beobachtung gelegentlich ausgelöster Events eines einzelnen Prozesses bis hin zur schrittweisen Ausführung einzelner Anweisungen unter Protokollierung sämtlicher auf dem System laufender Prozesse.
Das gibt der dynamischen Analyse ein großes Potenzial, aber auch Nachteile. So kann sie ausschließlich die Teile eines Programms beobachten, die tatsächlich ausgeführt werden, während das bösartige Verhalten während der Analyse möglicherweise verborgen bleibt und das Ergebnis nutzlos macht. Die mit der Analyse einhergehenden Monitoring-Instrumente verbrauchen darüber hinaus erhebliche Rechnerressourcen und verschlechtern damit die Performance von Anwendungen und dem System drastisch. 2005 führte eine Gruppe von Forschern eine neue Methode der dynamischen Analyse ein, die sogenannte
»Dynamic Taint Analysis«
, die die Spur verfolgt, die Daten aus nicht vertrauenswürdigen Quellen hinterlassen. Das Verfahren zeigt einen Ausweg aus dem aussichtslosen Unterfangen auf, jede neue Malware beim ersten Erscheinen in freier Wildbahn zu analysieren, um speziell darauf ausgerichtete Gegen-Software zu entwickeln; immerhin kann sich deren Anzahl auf mehrere Tausend an einem Tag belaufen.
Stattdessen schützt die Dynamic-Taint-Analysis-Methode einen Rechner, indem sie unsichere Daten auf ihrem Weg durch das System verfolgt. Wird die Ausführung unterbunden, bevor suspekte Daten zu einer gefährlichen Aktion führen, wird Malware neutralisiert, ohne dass deren Implementation und Design im Detail bekannt sind.
Dynamic Taint Analysis stuft eine nicht vertrauenswürdige Datenquelle als verunreinigt (
»tainted«
) ein. Sie markiert alle Daten, die eine solche Quelle produziert ebenfalls als verunreinigt. Diese Markierungen (
»Taint Tags«
) halten fest, aus welcher Quelle die Daten stammen. Stellen, an denen davon Gefahr ausgehen könnte, heißen analog dazu
»Taint Sinks«
. Jede Bewegung der verdächtigen Daten wird verfolgt, also auch ihre Kopien und Transformationen. Das System protokolliert auch, wenn ein solches Datenobjekt und damit auch die entsprechende Markierung zerstört wird. Erreicht ein markierter Datensatz ein Taint Sink, stoppt das System die Ausführung und die Analyse beginnt.
Allerdings besteht eine gewisse Gefahr darin, die Verunreinigungsmarkierungen im selben Speicherbereich abzulegen wie die gewöhnlichen Anwendungsdaten, weil andere Anwendungen sie dort überschreiben könnten. Ebenso problematisch ist es, die Markierungen gemeinsam mit den markierten Daten selbst zu speichern: Falls die Daten in ein Prozessorregister verschoben werden, fehlt dort ein Platz für die Zusatzinformation.
Um diese Probleme zu umgehen, werden die Verschmutzungsmarkierungen in ein sogenanntes Shadow Memory ausgelagert. Mit dieser Technik hält die Analyse-Software an jedem Ort, der potenziell nicht vertrauenswürdige Daten verwaltet, einen Schattenspeicher bereit, in denen die zugehörigen Markierungen lagern. Das betrifft in der Regel Arbeitsspeicher, CPU-Register sowie Ein- und Ausgabegerätpuffer, aber kann auch beispielsweise für die Festplatte gelten.
Eine einzelne Markierung steht für die Art der Verunreinigung, deren ein einzelner Datensatz verdächtig ist. Die Beschaffenheit der kleinsten Dateneinheit hängt vom Bedarf der Analyse ab. In vielen Fällen genügt es, eine Markierung pro Byte Daten bereitzuhalten. Eine sehr genaue Analyse kann es hingegen erfordern, jedes Bit zu markieren.
Auch die Anzahl der Markierungstypen variiert: Für einige Analysen genügt die Information, dass es sich um nicht vertrauenswürdige Daten handelt. In anderen Fällen ist eine Markierung von Nöten, die darüber hinaus die Datenquelle speichert. Im extremsten Fall käme also eine eigene Markierung für jedes einzelne Daten-Bit zum Einsatz, das ins System gelangt; das bläht allerdings das Shadow Memory auf.
Abbildung 2 zeigt ein Beispiel dafür, wie Daten sich durch den Speicher bewegen. Ein Byte steht für einen Datensatz, wie auch das damit verbundene Taint Tag. Nun kommt eine Operation zur Ausführung, die den Inhalt der Speicheradressen 0x1000 und 0x1002 addiert. Das Ergebnis landet abschließend wieder an der Adresse 0x1000. Die Daten an 0x1002 sind jedoch als nicht vertrauenswürdig markiert. Das hat zur Folge, dass nach vollzogener Addition auch 0x1000 markiert wird, weil die verdächtigen Daten aus 0x1002 darauf Einfluss genommen haben. Im weiteren Verlauf pflanzt sich diese Markierung nun bei allen Operationen fort, die die Daten aus 0x1000 verwenden.
 Abbildung 2: Die Zustände des Datenspeichers und des damit verknüpften Shadow Memory vor und nach einer Additionsoperation.
Abbildung 2: Die Zustände des Datenspeichers und des damit verknüpften Shadow Memory vor und nach einer Additionsoperation.
Der Weg der verunreinigten Daten von der Quelle bis zum Taint Sink gibt viele Erkenntnisse darüber preis, wie Malware ein System kompromittiert. So lässt sich sowohl die Quelle bösartiger Daten bestimmen, als auch jede Kopie der Daten verfolgen. In der Praxis hat sich diese Art der Analyse zu einem nützlichen Sicherheitswerkzeug entwickelt, das inzwischen zum Repertoire von Perl, PHP, Lua, Python und Ruby gehört. Sicherheitsbewusste Entwickler dieser Sprachen setzen die Technik ein, um ihre Software mit einem zusätzlichen Sicherheitscheck zu versehen, der auch bisher ungeahnten, zukünftigen Attacken standhält.
Ein gutes Beispiel eines dynamischen Analyse-Tools auf Prozessebene ist Intels Pin [6] . Dabei handelt es sich um ein Framework für die binäre Vermessung von Prozessen auf x86-Plattformen. Es heftet sich an laufende Prozesse an, etwa wie der GDB-Debugger, und führt dann Prozessoranweisungen schrittweise aus.
Pin ist erweiterbar und enthält zu diesem Zweck eine Reihe von Bibliotheken und Build-Skripts, die die Entwicklung von Pin-Plugins, sogenannter Pintools, in C/C++ unterstützen. Pintools stellen Callback-Funktionen bereit, die Pin dann zur Laufzeit eines Prozesses vor der Ausführung einzelner Anweisungen aufruft. Dieser Ansatz erlaubt die Entwicklung von Analysewerkzeugen für Einsatzzwecke wie das Protokollieren von Anweisungen, Profiling, die beschriebene Taint Analysis und zur Validierung von Argumenten.
Bei der Entwicklung dynamischer Analysewerkzeuge auf Systemebene empfiehlt es sich, auf Hypervisoren wie Xen und VMware oder Emulatoren wie Qemu und Bochs zu setzen. Denn wenn Analysesoftware in derselben Umgebung wie eine Malware läuft, könnte diese das Analyseprogramm entdecken und es außer Funktion setzen oder sich verbergen. Nutzt man Virtualisierung, um die Analyse von der Malware zu isolieren, besteht diese Gefahr der Manipulation nicht. Des Weiteren bringt der Einsatz virtueller Maschinen den Vorteil mit sich, dass man den Zustand von CPU-Registern, Stapel- und Heap-Speichern sowie Peripheriegeräten jederzeit beobachten kann.
Ähnliche Artikel
-
Malware-Analyse in der Sandbox

-
Malware-Untersuchung mit Cuckoo

-
Paranoide Perl-Programmierung jetzt auch für IPv6
Das für möglichst sichere Perl-Skripts gedachte Paket "Paranoid" enthält ein neues Modul zur Socket-Programmierung, das auch den Umgang mit IPv6 vereinfachen soll.
-
Malware mit pestudio identifizieren
-
Microsoft veröffentlicht Open-Source-Tool zur Quellcode-Analyse
Microsoft stellt sein hauseigenes Tool zur Quellcode-Analyse zur freien Verfügung: Der "Application Inspector" soll auch Besonderheiten innerhalb der Funktionen und Metadaten des Codes identifizieren.
Konfigurationsmanagement

Themen


