
Konfiguration
Will man die Deduplizierung mit einem SEP-sesam-Server benutzen, überzeugt man sich zuerst davon, dass Hard- und Software die Voraussetzungen erfüllen. Si3 braucht mindestens 16 GByte RAM und wenigstens 4 Rechenkerne sowie 1 TByte freien Plattenplatz. Für Testumgebungen reichen notfalls auch 8 GByte RAM und 2 Kerne. Software-seitig werden die Linux-Paketformate Deb und RPM für Suse-, Debian- und Red-Hat-Distributionen untertützt, dazu Windows 2003/2008/Win 7, Mac OSX, Solaris (Sparc und x86), Netware und einige weitere Unix-Derivate (darunter AIX, FreeBSD und HP-UX).
Die Deduplikation ist plattformübergreifend als Java-Applikation gestaltet. Sie integriert sich sehr gut in die bestehende SEP-Infrastruktur. Die komplette Logik der Aufträge und Zeitpläne bleibt bestehen, das Migrieren und Restaurieren von Sicherungen und das Monitoring funktionieren genauso wie bei herkömmlichen Backups.
Beim Einrichten ist tatsächlich nur an einer einzigen Stelle die Deduplikation einzustellen: Beim Einrichten eines sogenannten Data Stores muss als
»Store Type«
der Wert
»SEP Si3 Deduplication Store«
gewählt werden (
Abbildung 1
). Hernach werden in diesem Data Store mehrfach vorkommende Blöcke mit gleichem Inhalt durch Zeiger auf das erste Vorkommen ersetzt.
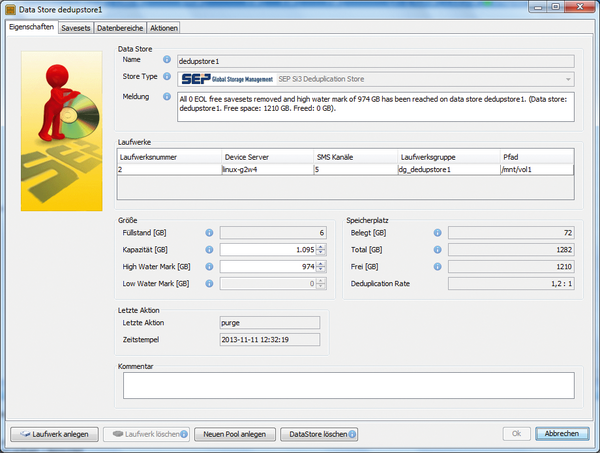 Abbildung 1: Die Konfiguration eines passenden Store Types beim Einrichten eines Data Store ist schon fast alles, was für die Deduplikation konfiguriert werden muss.
Abbildung 1: Die Konfiguration eines passenden Store Types beim Einrichten eines Data Store ist schon fast alles, was für die Deduplikation konfiguriert werden muss.
Vom Erfolg der Konfiguration kann man sich mit einem kleinen Test überzeugen. Dazu haben wir zehn 10-MByte-Files mit Zufallsdaten erzeugt, die anschließend auf den Dedup-Store gesichert wurden. Aus den über die GUI zugänglichen Protokollen (
»Monitoring | letzter Backup-Status«
) kann man die entsprechende Saveset-ID ersehen (
Abbildung 2
). Diese ID findet sich in der Ausgabe des Befehls
»sm_dedup_interface«
auf der Kommandozeile im Filenamen wieder (
Listing 1
).
Listing 1
Erstes Backup
 Abbildung 2: Die Statusübersicht verrät unter anderem auch die Saveset-ID dieser Sicherung.
Abbildung 2: Die Statusübersicht verrät unter anderem auch die Saveset-ID dieser Sicherung.
Im ersten Schritt konnte erwartungsgemäß nichts dedupliziert werden, da schließlich nichts da war, mit dem die anfallenden Daten hätten verglichen werden können. Die vollen 100 MByte gelangten auf die Platte und die Dedup-Rate betrug null Prozent.
Wer nun ohne die Daten zu ändern unmitelbar einen zweiten Lauf folgen lässt, erhält die ebenfalls zu erwartende hundertprozentige Deduplikation ( Listing 2 ): Jeder einzelne Block war bereits vorhanden. Dieselbe hundertprozentige Deduplikation wäre auch erreicht worden, wenn ein anderer Client dieselben Daten gesichert hätte.
Listing 2
Alles dedupliziert
Vor einem dritten Durchgang haben wir nur ein einziges Byte geändert. Bei einer dateibasierten inkrementellen Sicherung hätte das zur Folge, dass die betroffene Datei – und damit 10 MByte an Daten – neu geschrieben werden müssten. Mit Deduplizierung ist der Aufwand viel geringer ( Listing 3 ): Nur rund 15 KByte werden neu geschrieben.
Listing 3
Hohe Dedup-Rate
Wird auch fortan nur wenig geändert, dann bleibt die Deduplizierungssrate über die gesamte Haltezeit des Backups auf diesem Niveau.
Fazit
Deduplikation ist kein Allheilmittel, sie hat Vor- und Nachteile. Wo es etwa auf absolute Authentizität der Daten ankommt, wird man sie nicht zerpflücken und wieder zusammensetzen können. Wo die Performance das oberste Kriterium ist, sollte man bedenken, dass Deduplikation Zeit kostet. Und auch mit Blick auf die Datensicherheit kann man überlegen, dass ein Datenverlust durch Hardware-Ausfall – das ist unter ungünstigen Bedingungen trotz RAID möglich – wesentlich mehr Daten betrifft, wenn das deduplizierte Volume die zwanzigfache Menge fasst. Hat die Sicherheit höchste Priorität, muss man daran denken, dass verschlüsselte Daten schlecht deduplizierbar sind.
Will man aber in erster Linie Platz und damit auch Kosten sparen, dann hat man mit der Deduplikation ein sehr effektives Werkzeug an der Hand. Wenn es noch dazu wie bei SEP sesam gut in die Backup-Applikation integriert ist, dann fällt auch die Bedienung leicht und verursacht kein zusätzliches Kopfzerbrechen. Stimmt das Verhältnis von Rechenleistung zu parallel zu verarbeitenden Sicherungsaufträgen, fallen die Performance-Einbußen nicht groß ins Gewicht. Unter dem Strich bleibt dann vor allem eine geldwerte Platzersparnis, die man in diesem Umfang anders nicht erreichen könnte.
Infos
- Opendedup: http://opendedup.org
Ähnliche Artikel
-
SEP sesam jetzt mit Deduplizierung
Die SEP AG bringt mit der Deduplizierung Si3 eine mehrfach patentierte Inline-Deduplizierungslösung auf den Markt.
-
Deduplizierung mit VDO

-
SEP sesam Jaglion

-
SEP sesam verbessert Support für VM-Backups
Die neue Version 4.4.3 wurde für virtuelle Umgebungen wie VMware und Red Hat Enterprise Virtualization optimiert.
-
Marktübersicht Enterprise-Backup-Software

SEP sesam jetzt mit Deduplizierung
Die SEP AG bringt mit der Deduplizierung Si3 eine mehrfach patentierte Inline-Deduplizierungslösung auf den Markt.
Konfigurationsmanagement

Themen


