
Alles im Rahmen
Zweidimensionale Strukturen implementiert Pandas mittels der
»DataFrame«
-Klasse. Die Initialisierung eines DataFrame-Objekts erfolgt wiederum auf die gleiche Weise wie bei Series. Die Spalten definiert man ebenfalls über ein Dictionary, in dem jeder Schlüssel als Wert eine Liste aus Elementen enthält:
DataFrame({'a': [1, 2], 'b': [3, 4]})
Eine optionale
»index«
-Liste legt wie bei Series die Indizes fest. Zusätzlich nimmt der DataFrame-Konstruktor das optionale Argument
»columns«
entgegen, das wie
»index«
funktioniert, aber statt der Zeilen die Spaltenbezeichnungen definiert:
In: DataFrame({'a': [1, 2], 'b': [3, 4]}, columns=['a', 'c'], index=['top', 'bottom'])
Out:
a c
top 1 NaN
bottom 2 NaN
Auch hier fallen Spalten weg, die nicht in der
»columns«
-Liste stehen. Nicht definierte Spalten hingegen initialisiert Pandas wiederum mit
»NaN«
.
Der Zugriff auf eine Spalte erfolgt bei Dataframes ebenfalls wie auf ein Dictionary durch
»dataframe['a']«
. Zusätzlich lassen sich die Spalten als Attribute eines DataFrame-Objekts ansteuern:
»dataframe.a«
. Möchte man stattdessen eine Zeile adressieren, hilft das DataFrame-Attribut
»ix«
:
»dataframe.ix['top']«
.
Wie Series kennt auch Dataframe die
»reindex()«
-Methode. Sie bezieht sich standardmäßig auf die Zeilenbeschriftungen, aber das Argument
»columns«
ersetzt auf die gleiche Weise die Spaltennamen.
Sowohl bei Series- als auch bei DataFrame-Objekten dient die
»drop()«
-Methode dazu, einzelne oder mehrere Zeilen zu entfernen. Für den ersten Fall dient die Angabe des gewünschten Index als Argument. Um mehrere Zeilen zu löschen, kommt eine Liste zum Einsatz:
s.drop(['b', 'c'])
Dateien
In der Big-Data-Realität kommen zu analysierende Daten meist nicht direkt aus der Anwendung, die sie schließlich analysiert. Pandas liefert deshalb einige Hilfsfunktionen mit, die gängige Dateiformate einlesen und deren Inhalte direkt in Pandas-Datenstrukturen überführen. Sie heißen
»read_csv()«
,
»read_table()«
und
»read_fwf()«
.
Abbildung 1
zeigt eine Beispielsitzung mit der erweiterten Python-Shell IPython
[3]
und einem
»read_csv()«
-Aufruf,
Abbildung 2
die zusammengefasste Darstellung eines Datensatzes.
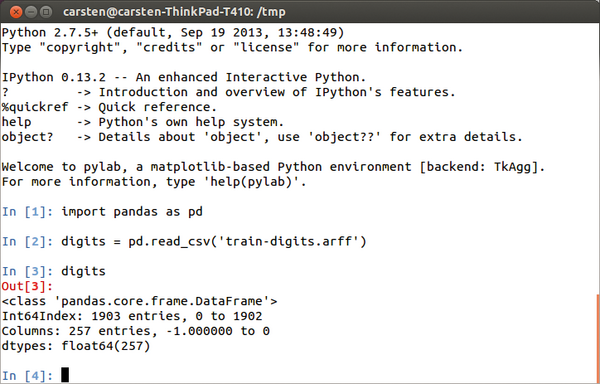 Abbildung 1: Mit IPython und Pandas zur interaktiven Datenanalyse.
Abbildung 1: Mit IPython und Pandas zur interaktiven Datenanalyse.
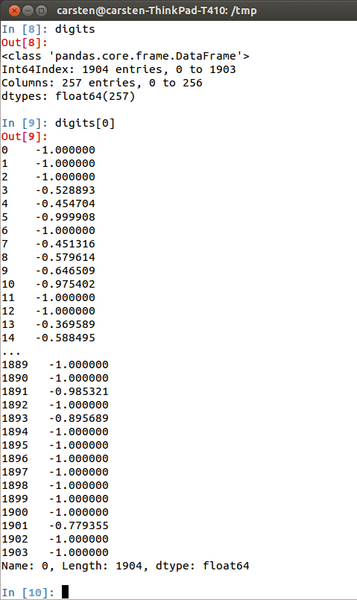 Abbildung 2: Pandas liest und schreibt Daten aus Dateien und stellt sie übersichtlich dar.
Abbildung 2: Pandas liest und schreibt Daten aus Dateien und stellt sie übersichtlich dar.
Diese Methoden erwarten Datenquellen in tabellarischer Form, also mit einem Datensatz pro Zeile und durch Kommas oder Tabulatoren separierte Zellen. Beliebige andere Feldtrenner lassen sich mit dem Argument
»sep«
in Form einfacher Strings oder regulärer Ausdrücke festlegen. Lediglich bei
»read_fwf()«
machen fest definierte Feldbreiten die Feldtrenner überflüssig, stattdessen übergibt man mit
»widths«
eine Liste der Feldbreiten in Zeichenanzahl oder mit
»colspecs«
die absoluten Start- und Endwerte jeder Spalte als Tupel. Als Datenquelle erwarten die Lesemethoden jeweils als erstes – oder als
»path«
-Argument – Dateinamen oder URLs.
Standardmäßig interpretieren die Pandas-Lesemethoden die erste Zeile einer Datei als Header, der die Spaltennamen enthält. Setzt man beim Methodenaufruf das Argument
»header=None«
, wird die erste Zeile zum ersten Datensatz. In diesem Fall bietet sich die Übergabe der Spaltennamen als Liste mithilfe des
»names«
-Arguments an.
Um beim Verarbeiten sehr großer Dateien Arbeitsspeicher und Zeit zu sparen, dient bei allen Lesefunktionen außerdem das Argument
»iterator=True«
dazu, das Einlesen stückweise zu erledigen. Statt des kompletten Dateiinhaltes liefern die Lesefunktionen dann ein TextParser-Objekt zurück. Die Größe der eingelesenen Teilstücke spezifiziert das Argument
»chunksize«
. Wird dieses Argument angegeben, setzt Pandas
»iterator«
übrigens automatisch auf
»True«
. Über einen TextParser lässt sich nun in einer
»for«
-Schleife die Datei zeilenweise lesen und verarbeiten. Die
»get_chunk()«
-Methode liefert direkt den nächsten Abschnitt der Datei.
Die Datenstrukturen Series und DataFrame machen es ebenso leicht, ihre Inhalte in Dateien zu schreiben. Beide verfügen über eine
»to_csv()«
-Methode, die als Argument die Ausgabedatei erwartet; gibt man stattdessen
»sys.stdout«
an, leitet sie die Daten direkt an die Standardausgabe um. Als Feldseparator kommt standardmäßig ein Komma zum Zuge, eine Alternative deklariert das
»sep«
-Argument.
Ähnliche Artikel



Konfigurationsmanagement

Themen


