
Nummerierung
Hadoop-Entwickler haben sich mit der Wahl der Versionsnummern selbst keinen großen Gefallen getan. Wer beachtliche Entwicklungsschritte mit der zweiten Dezimalstelle einer Versionsnummer kennzeichnet – wie von Version 0.20 zur Version 0.23 – darf sich anschließend nicht wundern, wenn die Anwender von den Fortschritten kaum Notiz nehmen.
Die Version 0.20 bezeichnet die erste Hadoop-Generation (v1.0, Abbildung 7 ). Wann immer vom 0.23-Zweig die Rede ist ( Abbildung 6 ), geht es um Hadoop 2.2.x. Die Versionsnummer 2.2.0 bezeichnet das erste Release der zweiten Generation mit der allgemeinen Verfügbarkeit.
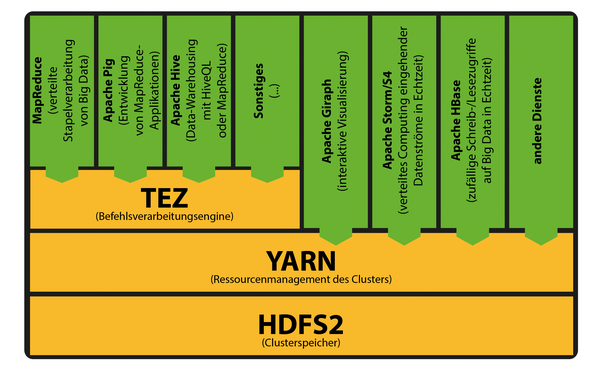 Abbildung 6: Der Hadoop-2.x-Stack mit Apache TEZ: Performance-Steigerung dank der Datenverarbeitung im Arbeitsspeicher des Clusters.
Abbildung 6: Der Hadoop-2.x-Stack mit Apache TEZ: Performance-Steigerung dank der Datenverarbeitung im Arbeitsspeicher des Clusters.
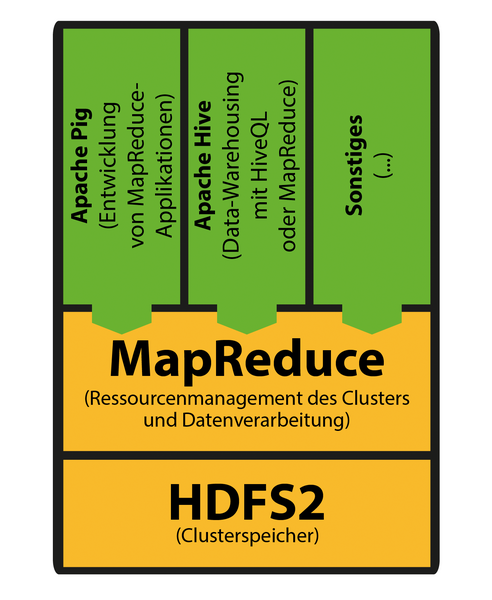 Abbildung 7: Zum Vergleich: In Hadoop 1.x waren alle Applikationen auf die Nutzung von MapReduce angewiesen.
Abbildung 7: Zum Vergleich: In Hadoop 1.x waren alle Applikationen auf die Nutzung von MapReduce angewiesen.
Ein Produkt der Enterprise-Klasse, das sich in der harten Praxis seit Jahren bewährt, hätte sich eigentlich eine höhere Versionsnummer verdient. Der scheinbar minimale Generationssprung auf die Version 2.2.0 trägt dem deutlich fortgeschrittenen Reifegrad von Hadoop kaum Rechnung. Der Qualität von Hadoop tut die zögerliche Nummerierung jedoch keinen Abbruch.
Die steigende Bedeutung von Hadoop erkennt man unter anderem auch daran, dass zahlreiche prominente Anbieter ihre kommerziellen Lösungen an Hadoop anpassen. SAP verkauft die Intel-Distribution und die HortonWorks Data Platform für Hadoop. SAP Hana, eine Datenanalyseplattform für Big Data, integriert sich nahtlos mit Hadoop.
DataStax liefert eine Distribution von Hadoop und Solr mit der eigenen NoSQL-Lösung DataStax Enterprise. Anwender von DataStax Enterprise nutzen Hadoop zur Datenverarbeitung, Apache Cassandra als eine Datenbank für transaktionale Daten und die Suchmaschine Solr für die verteilte Suche. Cassandra unterstützt im Übrigen das Ausführen von Hadoop-MapReduce-Jobs auf einem Cassandra-Cluster.
Fazit
Nach vier Jahren Entwicklungsarbeit überrascht Hadoop 2.2.0 seine Anwender mit bahnbrechenden Neuerungen. Dank der Modularisierung und einer HA-HDFS gelang es der Apache Foundation, den Abstand zu Alternativen zu halten oder sogar noch zu vergrößern.
Dank der deutlich verbesserten Verwaltung von Workloads hat Hadoop eine ganz neue Anziehungskraft für den Mittelstand bekommen. Großunternehmen konnten sich die benötigten Zusatzfunktionen schon immer maßgeschneidert programmieren lassen, der Mittelstand war dagegen bisher mit der mühsamen Entwicklung schlicht überfordert. Das hat sich mit Hadoop 2.2.0 nun glücklicherweise endgültig geändert.
Infos
- Hadoop-Distribution von Cloudera: http://www.cloudera.com/content/cloudera/en/products-and-services/cdh.html
- Hadoop-Distribution von Hortonworks: http://hortonworks.com/products/hadoop-support
- Hadoop-Distribution Stratosphere von der Technischen Universität Berlin: https://github.com/stratosphere/stratosphere
- Vergleich der Hadoop-Distributionen von MapR Technologies: http://www.mapr.com/products/mapr-editions
Ähnliche Artikel
-
Apache Hadoop 3.0 ist fertig
Eine neue Version der Big-Data-Umgebung wurde veröffentlicht.
-
Clouderas Hadoop-Distribution runderneuert

-
Hadoop 1.0.0 veröffentlicht
Nach sechs Jahren Entwicklungszeit erreicht die Cluster-Software Hadoop Version 1.0.0.
-
VMware startet Open-Source-Projekt für virtualisierte Hadoop-Cluster
Das neue Serengeti-Projekt soll Hadoop-Installationen in virtualisierten Umgebungen und "Clouds" erleichtern und ihre Performance verbessern.
-
Microsoft launcht SQL Server 2012, erweitert Beta für Hadoop
Ab sofort ist der SQL Server 2012 von Microsoft verfügbar. Für an "Big Data" Interessierte erweitert Microsoft das Beta-Programm von Hadoop auf der Azure-Cloud.
Apache Hadoop 3.0 ist fertig
Eine neue Version der Big-Data-Umgebung wurde veröffentlicht.
Konfigurationsmanagement

Themen


