
Gefragte Qualifikationen
Wer die Entwicklungen im IT-Jobmarkt der USA als Messlatte für künftige Trends ansetzt, wird feststellen, dass der Bedarf nach Hadoop-Kompetenz nahezu explodiert ( Abbildung 1 ). Kein Wunder, denn das Framework findet viele Einsatzgebiete in der Praxis. Auch in Deutschland mehren sich inzwischen Jobangebote rund um Big Data mit Hadoop. So suchte der Personaldienstleister Hays AG deutschlandweit Java-Entwickler, Softwarearchitekten und Systemadministratoren mit Apache-Hadoop-Kompetenzen für verschiedene Standorte. Die JobLeads GmbH versuchte im gleichen Zeitraum im Auftrag nicht näher benannter Kunden nahezu eine Hundertschaft Hadoop-versierte IT-Fachkräfte zu rekrutieren.
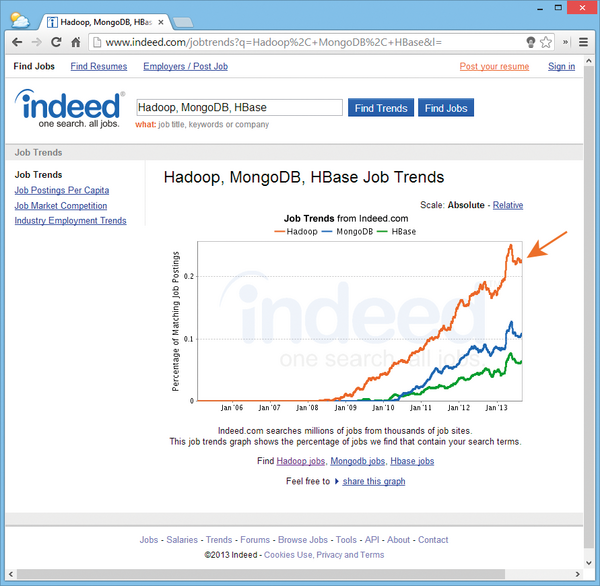 Abbildung 1: Trends auf dem Arbeitsmarkt in den USA versprechen Hadoop-versierten IT-Fachkräften eine leuchtende Zukunft.
Abbildung 1: Trends auf dem Arbeitsmarkt in den USA versprechen Hadoop-versierten IT-Fachkräften eine leuchtende Zukunft.
Laut einer Studie von IDC verzeichnet der weltweite Markt für Hadoop einen jährlichen Zuwachs von 60 Prozent. Allerdings stellte dieselbe Studie ebenfalls fest, dass sich dieses Wachstumstempo fast ausschließlich auf den Einsatz von Hadoop als elastischen und günstigen, verteilten Massenspeicher beschränkt.
Im Bereich der Datenanalyse gehört Hadoop zwar zur Weltspitze, doch eben diese Funktionalität scheint in der Praxis oft brach zu liegen. Hadoop-Anwender mit geringeren Entwicklungskapazitäten neigen verständlicherweise dazu, ihre wachsenden Datenbestände kostengünstig in HDFS vorzuhalten und die Datenanalyse mit externen, wenn auch schwächeren Lösungen zu bewältigen. Der Grund dafür ist einleuchtend: MapReduce in Hadoop 1.x wird von vielen als zu kompliziert und zu unflexibel empfunden. Hadoop 2.x soll Abhilfe schaffen und dem leistungsstarken Big-Data-Framework zu einer größeren Verbreitung verhelfen.
Einsatzgebiete und Anwendungsbeispiele
Praktische Einsatzgebiete von Hadoop sind sehr vielfältig. Sie beinhalten die Analyse von Web-Clickstream-Daten zur Optimierung der Konversionsrate, das Auswerten der Sensordaten eines Maschinenparks zur Optimierung von Produktionsprozessen oder von Server-Logdateien für eine verbesserte Sicherheit, das Erstellen von Vorhersagen auf der Basis von Geolocation-Daten, Data-Mining von Social-Media-Aktivitäten wie Twitter-Diskussionen oder Facebook-Likes für ein besseres Verständnis der eigenen Zielgruppe, statistische Aufbereitung von Such-Indizes und RFID-Daten – die Liste nimmt kein Ende.
Banken und Versicherungen nutzen Applikationen auf Basis von Hadoop für die Bewertung von Kunden anhand ihrer Finanzhistorie mithilfe von Mustererkennungsalgorithmen. So können Finanzinstitute unter anderem dem Kreditkartenmissbrauch einen Riegel vorschieben und die Kreditwürdigkeit ihrer Kunden im Rahmen des Risikomanagements besser einschätzen.
Im E-Commerce und in der Online- und mobilen Werbung kommt Hadoop beim Berechnen von Produktempfehlungen zum Einsatz. Das Verhalten eines Besuchers im eigenen Webshop und auf Social Media dient hier als Grundlage zum Erforschen seiner Präferenzen. Rechenzentren, Telcos und Webhoster nutzen Hadoop-basierte Lösungen, um Flaschenhälse oder Fehler in Netzwerken frühzeitig zu erkennen, indem sie den Netzwerkverkehr statistisch auswerten. Ein anderes Beispiel stellen Algorithmen zur Analyse der Bedeutung von Texten dar, die von Menschen verfasst wurden. So etwas setzen manche E-Commerce-Anbieter und Telekommunikationsdienstleister beim Auswerten von Kundenanfragen ein.
Mit Lösungen auf Basis von Hadoop lassen sich auch mehrere verschiedene Datenquellen kombinieren und so multidimensionale Analysen erstellen.
Zu den Vorreitern beim Einsatz von Hadoop für multidimensionale Datenanalyse zählt die Glücksspielindustrie. Denn Casinos sind besonders verwundbar: Im Betrugsfall können sie in wenigen Minuten sehr viel Geld verlieren. Analytics-Lösungen für Big Data haben sich bei der Betrugsermittlung und beim Erforschen der eigenen Zielgruppe mehr als bewährt. Dank Big Data können Casino-Betreiber fein granulierte Kundenprofile anfertigen. Alleine das Flamingo-Hotel von Caesars Entertainment in Las Vegas beschäftigt 200 Big-Data-Analysten. Spezialisierte Analytics-Lösungen für die Glücksspielindustrie wie Kognitio (kognitio.com) setzen auf Hadoop auf.
Spielchips, Kunden-Loyalitätskarten und sogar Spirituosenflaschen in Bars wie die bei Aria Hotel und Casino sind mit RFID-Tags ausgestattet. Diese Technologie erlaubt es, das Geschehen in Echtzeit zu verfolgen. Casinos nehmen all diese Messwerte als fein granulierte Daten konsequent unter die Lupe. "Casinos stellen die talentiertesten Kryptographen, Computer-Sicherheitsexperten und Spieltheoretiker ein" sagt John Pironti, leitender Informationsrisikostratege des Datenschutzspezialisten Archer Technologies. Sicherheitstechnologien wie die Videoüberwachung oder RFID-Tracking produzieren riesige Datenmengen. Relevante Daten werden dabei niemals verworfen, denn sie sind einfach zu wertvoll. Auch hier kommt Hadoop zum Einsatz – und zwar als ein verteiltes Dateisystem. Während Casinos mit diesen Innovationen experimentieren, versuchen auch Unternehmen in anderen Branchen, diese Erfahrungen für ihr eigenes Geschäft zu nutzen.
Auf Basis von Hadoop lassen sich maßgeschneiderte Lösungen programmieren, um Datenbestände effizienter zu verwalten. Ein Beispiel liefert das Media Asset Management der Red Bull Media House GmbH ( Abbildung 2 ). Die deutsche ADACOR Hosting GmbH aus Essen stellte im Auftrag des österreichischen Unternehmens Red Bull Media House GmbH mehrere Lösungen für das Media Asset Management auf den Prüfstand. Die Aufgabe bestand darin, ein zentrales Repository von Inhalten wie Videoclips, Fotos und Audiodateien in verschiedenen Formaten und Qualitätsstufen zu schaffen, damit die Kunden jederzeit von überall her schnell und einfach auf diese Daten zugreifen konnten.
 Abbildung 2: Die Media-Asset-Management-Plattform der österreichischen Red Bull Media House GmbH setzt auf HDFS auf.
Abbildung 2: Die Media-Asset-Management-Plattform der österreichischen Red Bull Media House GmbH setzt auf HDFS auf.
Zu den Anforderungen zählte der Wunsch nach elastischer Skalierbarkeit ohne Wartungsfenster, minimalen Ausfallzeiten bei Hardware-Pannen, Datenreplikation, schneller Auslieferung der Daten, einer einfachen Verwaltung und einem besseren Kosten-Nutzen-Verhältnis als es Standardlösungen wie EMC-Storage bieten. In die engere Wahl kamen unter anderem NFS, GlusterFS, Lustre, Openfiler, CloudStore und schließlich das Hadoop Distributed File System (HDFS).
Als erster Ansatz wurde NFS untersucht, ein in der Unix-Welt sehr verbreitetes, stabiles und bewährtes Dateisystem. NFS enttäuschte ADACOR durch unzureichende Performance und fehlende Features wie die nicht vorhandene Datenreplikation. Auch die Verwaltung des verteilten Speichers hätte die resultierende Applikation übernehmen müssen. Der Aufwand wäre einfach zu groß gewesen.
Als zweiter Kandidat kam GlusterFS unter die Lupe. Mit diesem Dateisystem hatte die ADACOR Hosting GmbH bereits in einem anderen Kontext gute Erfahrungen gemacht, vor allem im Hinblick auf die Performance. Mit steigender Anzahl der Knoten eines GlusterFS-Clusters nimmt der maximale Datendurchsatz zu. GlusterFS disqualifizierte sich jedoch in den Augen der Tester durch einen sehr hohen Verwaltungsaufwand und eine praxisfremde Skalierbarkeit mit obligatorischer Downtime.
Lustre konnte sowohl im Hinblick auf die Performance, Skalierbarkeit als auch die komfortable Administration punkten. Doch auch diese Lösung hatte zum Zeitpunkt der Implementierung keine robuste Replikation vorzuweisen.
Openfiler fiel aus der engeren Auswahl heraus, als das System mehrere Tage brauchte, um ein Rebuild von lediglich 3 Terabyte Daten abzuschließen. CloudStore wurde von ADACOR aufgrund mangelnder Stabilität verworfen.
Lediglich HDFS, das verteilte Dateisystem von Hadoop, konnte in allen Punkten überzeugen und die Kundenanforderungen am ehesten erfüllen.
Ähnliche Artikel
-
Apache Hadoop 3.0 ist fertig
Eine neue Version der Big-Data-Umgebung wurde veröffentlicht.
-
Clouderas Hadoop-Distribution runderneuert

-
Hadoop 1.0.0 veröffentlicht
Nach sechs Jahren Entwicklungszeit erreicht die Cluster-Software Hadoop Version 1.0.0.
-
VMware startet Open-Source-Projekt für virtualisierte Hadoop-Cluster
Das neue Serengeti-Projekt soll Hadoop-Installationen in virtualisierten Umgebungen und "Clouds" erleichtern und ihre Performance verbessern.
-
Microsoft launcht SQL Server 2012, erweitert Beta für Hadoop
Ab sofort ist der SQL Server 2012 von Microsoft verfügbar. Für an "Big Data" Interessierte erweitert Microsoft das Beta-Programm von Hadoop auf der Azure-Cloud.
Konfigurationsmanagement

Themen


