
Unicode-Support
Herauszufinden, ob das erste Zeichen eine Zahl ist, gestaltet sich etwas schwieriger, weil Go zur Zeichen-Codierung UTF-8 verwendet – was an sich ja eine prima Sache ist. Weil UTF-8 aber ein Format ist, das zwischen einem und vier Bytes für ein Zeichen benutzt, ist nicht von vornherein klar, wieviele Bytes das erste Zeichen umfasst. Typischerweise wandern Go-Programmierer Stück für Stück durch ein Byte-Array und entschlüssen dabei, wann ein neuer UTF-8 Character anfängt. Mit einem Typecast macht Go das automatisch in einem Rutsch. Am Ende kommt ein Array mit "Runen" heraus – so werden in Go einzelne UTF-8-Zeichen bezeichnet –, von denen man mit einem Array-Index das erste Zeichen ausliest. Das wiederum lässt sich mit einem einfachen Aufruf der Funktion
»unicode.IsDigit()«
erledigen, der eine Rune als Argument erwartet:
if unicode.IsDigit([]rune(proc.Name())[0]) {...
Dass das in der Unicode-Welt übrigens nicht nur auf arabische Zahlen zutrifft, sondern auch mit anderen Zahlensystemen funktioniert, zeigt ein kleines Beispielprogramm, das in Abbildung 2 zu sehen ist.
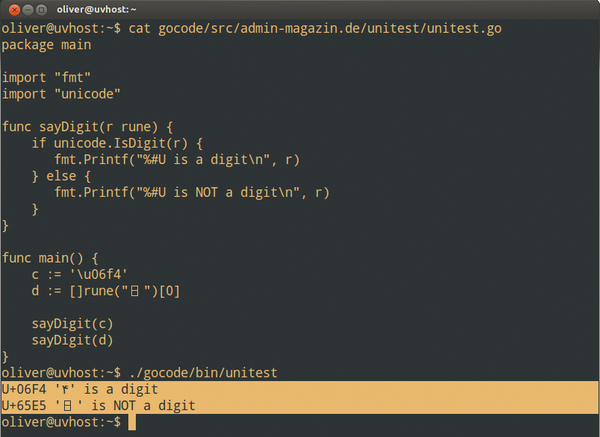 Abbildung 2: Die Unicode-Methode IsDigit ermittelt, ob ein Zeichen eine Zahl ist. Das funktioniert selbst mit fremden Zahlensystemen.
Abbildung 2: Die Unicode-Methode IsDigit ermittelt, ob ein Zeichen eine Zahl ist. Das funktioniert selbst mit fremden Zahlensystemen.
Als nächstes geht es darum, die virtuellen Dateien des Procfs zu öffnen und ihren Inhalt zu verarbeiten. Praktischerweise bietet wieder die Bibliothek
»ioutil«
mit
»ReadFile«
eine Funktion, die eine Datei komplett einliest und den Inhalt in einem Byte-Array ablegt:
stat, err := ioutil.ReadFile(filename)
Wie man sieht, gibt die Funktion zwei Werte zurück: den Inhalt der Datei und einen Fehlercode. Das ist typisch für Go-Funktionen und jedenfalls strukturierter als etwa im Fehlerfall für den Inhalt einen Nullpointer zurückzuliefern. Weist man den Fehlercode einer Variablen zu, muss man Sie auch verarbeiten, sonst gibt der Compiler seinerseits eine Fehlermeldung aus und weigert sich, die Datei zu übersetzen. Wer den Rückgabewert ignorieren möchte, kann den Fehlercode wieder dem Platzhalter
»_«
zuweisen. Um den Fehler zu verarbeiten, testet man üblicherweise, ob die
»err«
-Variable gleich
»nil«
ist. Dann ist kein Fehler aufgetreten.
Die Datei
»/proc/PID/stat«
enthält nur eine Zeile in einem fixen Format, bei dem die einzelnen Felder durch Leerzeichen getrennt sind. Leider ist das Format nirgends vernünftig dokumentiert, auch nicht in der Linux-Kernel-Dokumentation des Procfs
[2]
. Letztlich hilft, wenn man es genau wissen möchte, nur ein Blick in den Linux-Quellcode. Zuerst kommt jedenfalls die PID (die ja mit dem Verzeichnisnamen identisch ist), dann in Klammern der Prozessname, der Status des Prozesses und die Parent-PID.
Regular Expressions
Die Felder lassen sich zum Beispiel mit der Funktion
»fmt.Sscanf«
verarbeiten, die genauso funktioniert wie die entsprechende Funktion in C: Format-Strings legen das Format der gelesenen Zeile und den Datentyp fest. Alternativ – wenn auch vermutlich etwas langsamer – lässt sich das Gleiche auch mit Regular Expressions erledigen. Dazu bietet Go das Paket
»regexp«
an, das die RE2-Syntax von Regular Expressions implementiert
[3]
.
Die von dem Modul zur Verfügung gestellten Funktionen sind etwas unübersichtlich, folgen aber einem System. Zunächst einmal gibt es von jeder Funktion zwei Varianten: eine, die ein Byte-Array verarbeitet und eine, mit dem Wort "String" im Namen, die mit Strings umgeht. Dann gibt es Funktionen, die den gefundenen String nur einmal oder mehrfach ("All") liefern. Wer in einer Regular Expression mehrere Suchmuster verwenden und die gefundenen Strings Variablen zuweisen möchte, verwendet eine Funktion mit "Submatch" im Namen.
Hier tut es die Funktion
»FindStringSubmatch«
, weil das Regex-Muster so konstruiert ist, dass es ohnehin nur einmal zutreffen kann und dabei die Fundstellen alle in einem Array speichert. Das Byte-Array, das von
»ReadFile«
stammt, wird per Typecast in einen String umgewandelt. Würde man die Byte-Array-Varianten der Regular-Expression-Funktionen verwenden, müsste man danach auch mit Byte-Array weiterarbeiten oder diese umwandeln.
Auch für die Übersetzung des Suchmusters gibt es mehrere Funktionen:
»Compile«
,
»CompilePOSIX«
,
»MustCompile«
und
»MustCompilePOSIX«
. Warum das so ist, erschließt sich nicht ganz, denn das Gleiche hätte sich ja auch mit nur einer Funktion umsetzen lassen, die entsprechende Parameter verarbeitet. Um zu verhindern, dass die Regular Expression immer wieder neu übersetzt wird, kann man sie als Toplevel-Variable definieren. Der zugehörige Code ist in
Listing 1
zu sehen.
Listing 1
Regular Expressions
Zeile 14 des Codes legt ein neues
»ProcData«
-Objekt an und weist die beiden ersten Submatches dessen Attributen
»pid«
und
»name«
zu. In Zeile 9 ist die Regular Expression in Backticks
»`«
eingeschlossen, weil bei Strings in einfachen oder doppelten Anführungszeichen ein Backslash
»\«
als Escape-Zeichen gilt. Man müsste also umständlich vor jeden Backslash noch einen zweiten schreiben. In der Backtick-Umgebung kann man sich das sparen.
Analog läuft das Ganze mit der Datei
»/proc/PID/status«
, die man ebenfalls einlesen muss, weil etwa die User-ID des Prozesses nicht in der
»stat«
-Datei zu finden ist. Allerdings ist die Status-Datei etwas schwieriger zu parsen, denn sie enthält viele einzelne Zeilen. Man könnte also die Datei zeilenweise verarbeiten oder eine Regular Expression im Multiline-Mode verwenden, den der Schalter
»m«
zu Beginn der Regex aktiviert. Dies allein genügte allerdings noch nicht, es war auch noch der Schalter
»s«
nötig, der dafür sorgt, dass die Metavariable
».«
in der Regular Expression auch das Newline-Zeichen
»\n«
einschließt. Die Regex, um aus der Status-Datei die User- und Group-ID zu entnehmen, sieht dann so aus:
(?sm)^Uid:\t(\d+).*^Gid:\t(\d+)
Auch die UID wird nun einem Feld im
»ProcData«
-Objekt zugewiesen. Bleibt noch, aus der UID den Usernamen zu ermitteln, etwa über die Passwd-Datei. Die Arbeit kann man sich allerdings sparen, denn Go bietet dafür schon die Funktion
»user.LookupId«
, die als Ergebnis ein
»User«
-Objekt zurückgibt, das unter anderem den Benutzernamen enthält. Summa summarum sieht das so aus:
user, _ := user.LookupId(procData.uid) procData.user = user.Username
Eine Option des
»lap«
-Tools soll bestimmten, ob es den Namen oder die UID ausgibt. Zur einfachen Implementierung von Kommandozeilenoptionen bringt Go das Paket
»flags«
mit. Wie alles in Go sind auch die Flags typisiert und stehen zum Beispiel als Integer, String und Boolean zur Verfügung. Einen Bool-Schalter definiert die folgende Zeile:
var realname = flag.Bool("r", false, "show real user name")
flag.Parse()
Der erste Parameter gibt den Namen des Schalters an, danach folgen die Default-Belegung und der erklärende Text. Im weiteren Verlauf des Programms kann man nun die Variable mit
»if (realname)«
abfragen. Mit
»-r«
aufgerufen, gibt
»lap«
dann die Benutzernamen aus, sonst nur die UID (
Abbildung 3
). Die wesentlichen Funktionen des Programms sind in
Listing 2
zu sehen, das komplette Listing auf dem Server des ADMIN-Magazins
[4]
.
Listing 2
lap.go
 Abbildung 3: Das Ergebnis der Mühen: Das Prozess-Tool lap zeigt die laufenden Prozesse mit Benutzernamen an.
Abbildung 3: Das Ergebnis der Mühen: Das Prozess-Tool lap zeigt die laufenden Prozesse mit Benutzernamen an.
Ähnliche Artikel
-
Skriptprogrammierung mit Python

-
Die Skriptsprache Lua

-
Programmieren mit Go

-
ADMIN-Tipp: Shell mit eingebautem Python
Die Xonsh erlaubt es, auf der Kommandozeile Python-Syntax zu verwenden.
-
Ruby 1.9.2 fertig
Die neueste stabile Version der 1.9-Serie bringt Anwendern viele neue Funktionen und einige inkompatible Änderungen.
Konfigurationsmanagement

Themen


