Workshop: Zentrale Serververwaltung mit Puppet

Modulare Administration

Haben Sie in einer verteilten Umgebung mehrere Rechner zu verwalten, bietet sich ein zentrales Management an. Eine Möglichkeit hierzu bietet Puppet als eine der bekanntesten Lösungen zur Server-Verwaltung. Dabei bringt es mit einer eigenen Konfigurationssprache viele Möglichkeiten mit, die Konfiguration zu strukturieren. Im April haben wir Ihnen gezeigt, wie Sie mit dem Werkzeug Dienste ausrollen und konfigurieren. In diesem Workshop gehen wir auf die Verwaltung einer Client- und Server-Umgebung ein. Dabei gibt es einen oder mehrere Steuerungsrechner, die sogenannten Master, und mehrere Clients oder im Puppet-Jargon “Agenten”, die der Master steuert.
Je nach eingesetztem Betriebssystem und dessen Version gibt es unterschiedliche Paketnamen für die Puppet-Softwarekomponenten. Generell empfiehlt es sich, eine möglichst neue Version von Puppet zu verwenden, da die Software rasant weiterentwickelt wird. Ein Nebeneffekt dessen ist, dass viele Tutorials im Netz veraltet sind. Ubuntu 13.10, das diesem Artikel zugrunde liegt, bringt Puppet in Version 3.2.4 mit und das Paket mit dem Puppet-Master heißt “puppetmaster”. Zusätzlich installiert der Paketmanager noch die benötigten Pakete “puppetmaster-common” und “puppet-common”. Auf den Agenten genügt die Installation des Pakets “puppet”, das wiederum “puppet-common” einschließt.
Verwenden Sie verschiedene Betriebssysteme oder Versionen einer Linux-Distribution, stellt sich die Frage, wie gut unterschiedliche Versionen der Puppet-Software zusammenarbeiten. Eine einfache Antwort darauf gibt es nicht, nur den Hinweis: Die Version auf dem Master muss in jedem Fall neuer sein als die auf den Agent-Rechnern, dann können sie prinzipiell zusammenarbeiten. Da sich allerdings Features und Konfigurationssprache über die Versionen hinweg geändert haben, muss das nicht in jedem Fall funktionieren. Im Zweifelsfall empfiehlt es sich, auf allen beteiligten Rechnern die neueste oder zumindest die gleiche Version von Puppet zu installieren. Hierzu bietet die Firma hinter Puppet für diverse Linux-Distributionen wie auch OS X und Windows Paketquellen an, die aktuelle Puppet-Versionen führen.
Puppet in Betrieb nehmen
Nach der Installation läuft auf dem Master der Prozess “puppet master”, den Sie manuell per service puppetmaster start/stop starten und stoppen. Auf dem Client heißt der Prozess “puppet agent” und der Service ebenfalls “puppet”. Zur Absicherung der Kommunikation zwischen Master und Agenten verwendet Puppet Zertifikate, die es selbst verwaltet. Unter anderem deshalb ist es empfehlenswert, für das eigene Netzwerk einen funktionierenden Nameservice zu betreiben, der sowohl die Namen nach IP-Adressen auflöst wie auch umgekehrt. Puppet funktioniert prinzipiell auch ohne DNS, zum Beispiel indem Sie die Hosts-Dateien auf den Rechnern verteilen, aber DNS ist in jedem Fall die bessere Lösung.
 Bild 1: Beim ersten
Aufruf erzeugt der Puppet-Agent ein SSL-Zertifikat und schickt es
an den Master
Bild 1: Beim ersten
Aufruf erzeugt der Puppet-Agent ein SSL-Zertifikat und schickt es
an den Master
Zwar läuft der Agent nach der Installation schon im Hintergrund, tut aber nichts, weil er noch kein passendes Zertifikat besitzt. Ein Aufruf auf der Kommandozeile erzeugt ein Zertifikat und reicht es beim Master zur Begutachtung ein:
sudo puppet agent --test
Per Default verwendet Puppet als Hostnamen für den Master “puppet”. Alternativ übergeben Sie ihn auf der Kommandozeile mit dem Parameter “--server” oder in der Konfigurationsdatei /etc/puppet/puppet.conf im Abschnitt “[main]” mit “server=Hostname”. Führen Sie den obigen Befehl aus, gibt der Puppet Agent eine Meldung ähnlich der in Bild 1 aus. Nachdem er das Zertifikat erzeugt hat, stellt er seine Arbeit ein. Alternativ wartet er mit dem Schalter “--waitforcert Zeitdauer ” eine Zeit lang und sucht dann wieder den Kontakt zum Master.
Auf dem Master sollte nun das Zertifikat angekommen sein, was Sie mit einem Aufruf von sudo puppet cert list in Erfahrung bringen. Mit sudo puppet cert sign Hostname signieren Sie es (Bild 2). Nun können Master und Agent über die gesicherte Verbindung kommunizieren. Falls der Agent beim Aufruf jetzt meldet, er sei noch ausgeschaltet (disabled), beheben Sie das mit puppet --enable . Wenn es doch Probleme mit dem DNS gibt, bietet Puppet den Schalter “--certname”, über den sich der Hostname für das Zertifikat einstellen lässt.
Was jetzt noch fehlt, ist die Konfiguration des Agenten auf dem Master – die Node-Definition, die in den sogenannten Manifesten stattfindet. Darüber legen Sie fest, welche Software auf einem Node installiert ist, welche Benutzer es gibt, welche Dienste laufen und so weiter. Ihren Ort haben die Node-Definitionen auf dem Master in der Datei /etc/puppet/manifests/site.pp . Allerdings gibt es diverse Möglichkeiten, eine umfangreiche Konfiguration zur besseren Übersichtlichkeit zu modularisieren. Dazu später mehr. Eine Node-Definition sieht grundsätzlich so aus:
node ‘node3.cloud.net’ {
}
Wie der konfigurierte Node beschaffen ist, steht zwischen den geschweiften Klammern. Wer eine große Zahl gleichartiger Hosts konfigurieren möchte, darf in der ersten Zeile auch mehrere Hostnamen aufführen, ohne den Konfigurationsblock immer wieder zu replizieren.
Noch einfacher geht es, wenn Sie die von Puppet hier unterstützten Regular Expressions einsetzen. Damit können Sie beispielsweise Muster von Hostnamen verwenden, die sich nur in einer Zahl unterscheiden, etwa node /^node\d+\.cloud\.net/ {...} . Diese Definition bezieht sich auf alle Agenten mit den Namen “node1.cloud.net”, “node2.cloud.net” und so weiter. Die beiden Back-slashes vor den Punkten dienen als Escape-Zeichen, weil der Punkt in der Regular-Expression-Syntax als Platzhalter für beliebige Zeichen dient. Darüber hinaus kann Puppet Hostnamen und andere Daten auch aus Datenbanken, LDAP-Verzeichnissen und anderen Quellen beziehen. Somit steht einer Integration in eine Lösung zum Inventory Management nichts im Weg.
Wie Manifeste aussehen, haben wir im Puppet-Workshop im April bereits erklärt, hier eine kurze Auffrischung: Das nachfolgende Listing zeigt ein Manifest mit einer Package-Definition und einigen Abhängigkeiten. Das definierte Paket stellt sicher ( ensure => present ), dass das Apache-Paket installiert ist. Als Voraussetzung dafür ( require... ) aktualisiert es über eine zweite Definition die Paketdatenbank des Ubuntu- oder Debian-Servers. Schließlich stellt eine dritte Definition, die die Installation des Apache-Pakets voraussetzt ( require => Package[“apache2”] ), sicher, dass der Apache-Dienst läuft ( ensure => running ).
package { “apache2”: ensure =>
present,
name => $apache,
require => Exec[‘apt-get update’]
}
exec { ‘apt-get update’:
command => ‘/usr/bin/apt-get update’
}
service { “apache2”:
ensure => “running”,
enable => “true”,
require => Package[“apache2”],
}
Ein zweites Beispiel-Manifest, das sich nicht um die Installation eines Software-Pakets dreht, ist im folgenden Listing zu sehen. Hiermit legt Puppet auf dem gemanagten Rechner den Benutzer oliver an. Das Attribut managehome => true sorgt dafür, dass Puppet bei Bedarf auch ein Home-Verzeichnis anlegt. Allerdings tut es das nur, wenn es auch den Benutzer anlegt. Löschen Sie beispielsweise nach dem Anlegen des Benutzers das Home-Verzeichnis, legt Puppet es beim nächsten Durchlauf nicht mehr neu an. Hierzu gibt es ein Bug-Ticket, das für eine neue Puppet-Version die Umbenennung des irreführenden Attributs in createhome vorschlägt.
user { ‘oliver’:
ensure =>
present,
managehome =>
true,
}
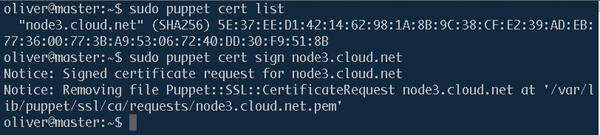 Bild 2: Auf dem Master
signiert der Administrator das vom Agenten erzeugte Zertifikat
Bild 2: Auf dem Master
signiert der Administrator das vom Agenten erzeugte Zertifikat
Modulare Konfiguration
Weil eine einzige Datei für eine Vielzahl an verwalteten Rechnern schnell unübersichtlich wird, bietet Puppet eine Reihe von Möglichkeiten, die Konfiguration auf dem Master zu modularisieren. Im einfachsten Fall geschieht dies über die Import-Anweisung, die nichts anderes macht, als blind den Inhalt der importierten Dateien in die Konfigurationsdatei zu übernehmen.
Die Import-Anweisung war früher einmal ein wichtiges Mittel zur Modularisierung, aber Puppet hat sich in der Zwischenzeit weiterentwickelt, und so raten die Entwickler heute vom Einsatz der Import-Anweisung ab, mit einer Ausnahme: dem Auslagern von Node-Definitionen in eigene Dateien. Statt also in einer Node-Definition die Anweisungen zwischen die geschweiften Klammern zu schreiben, können Sie sie in eine neue Datei schreiben und dann mit der folgenden Anweisung einbinden:
node ‘node4.cloud.net’ {import
‘nodes/node4.pp’
}
Node-Definitionen unterstützen zudem Vererbung. Das bedeutet, dass Sie beispielsweise einen Basis-Typ von Server definieren können, der bestimmte User-Accounts enthält, Basis-Dienste wie Secure Shell, Firewall-Regeln und so weiter. Leiten Sie dann spezialisierte Server wie einen Datenbank-Rechner oder einen Webserver mit dem Schlüsselwort inherits davon ab, besitzen diese schon alle im Basistyp definierten Ressourcen.
Wer nun die obige Apache-Konfiguration in mehrere Node-Definitionen einträgt, wird eine unliebsame Überraschung erleben. Puppet meldet dann nämlich duplicate Definitions, die nicht erlaubt sind: Eine Ressource darf in der Konfiguration nur einmal definiert werden. Aus dieser Misere gibt es wiederum mehrere Auswege.
Eine davon sind virtuelle Ressourcen, die Sie definieren, indem Sie vor einen Ressourcentyp ein @-Zeichen stellen, also beispielsweise @package . Dann sind sie zwar definiert, aber der Puppet Master schickt sie nicht an die Clients. Damit er das tut, müssen Sie virtuelle Ressourcen in der jeweiligen Umgebung, also einem Node, “realisieren”. Auch hierfür gibt es wieder zwei Möglichkeiten, nämlich den sogenannten Spaceship-Operator oder die Funktion realize .
Der bessere und heute empfohlene Weg, eine Puppet-Konfiguration zu strukturieren, führt aber über Module, die schon im ersten Teil des Puppet-Workshops thematisiert wurden. Dabei definieren Sie sogenannte Klassen, die Ressourcen bereitstellen, die Sie in den Node-Definitionen nutzen können. Um die oben erstellte Apache-Konfiguration für alle Nodes nutzen zu können, wandeln Sie sie in ein Modul um, das Sie in /etc/puppet/modules speichern:
modules/apache/ modules/apache/templates modules/apache/manifests modules/apache/manifests/init.pp modules/apache/files
Fürs Erste können die Verzeichnisse templates und files leer bleiben, da es nur darum geht, die Installation und den Start des Servers mithilfe eines Moduls umzusetzen. Dabei können Sie die obige Konfiguration im Prinzip unverändert in die Datei init.pp übernehmen, schließen Sie aber noch in die Definition einer Klasse ein, wie das Listing zeigt:
class apache {
package { “apache2”:
ensure
=> present,
name
=> $apache,
require => Exec[‘apt-get
update’]
}
exec {
‘apt-get update’:
command => ‘/usr/bin/apt-get update’
}
service { “apache2”:
ensure
=> “running”,
enable
=> “true”,
require => Package [“apache2”],
}
}
In der Node-Definition genügt es nun, die Klasse mit include apache einzubinden. Um zu sehen, ob die Node-Definition und die Klasse funktionieren, loggen Sie sich auf einem Client ein und rufen den Agenten von Hand mit dem Schalter “--test” auf, der die Option “--verbose” für eine ausführliche Ausgabe impliziert (Bild 3):
sudo puppet agent --test
Der Agent bietet übrigens auch noch den Schalter “--noop”, der verhindert, dass Änderungen angewandt werden. Stattdessen absolviert der Agent nur einen Testlauf. Um noch ausführlichere Meldungen über den Verlauf zu bekommen, rufen Sie den Agenten mit “--debug” auf.
Wie Sie die Konfigurationsdateien in das Apache-Modul integrieren, hat der April-Workshop beschrieben. Darüber hinaus ist es möglich, dafür Templates zu verwenden, in denen Variablen als Platzhalter stehen, die Puppet bei der Ausführung durch konkrete Werte ersetzt, etwa um den Hostnamen in die Apache-Konfiguration einzutragen. In gewissem Umfang sind auch logische Abfragen und Ähnliches möglich, etwa um festzustellen, ob es sich bei einer Variablen um einen einfachen Wert oder eine Liste handelt, und die Konfiguration dann entsprechend anzupassen.
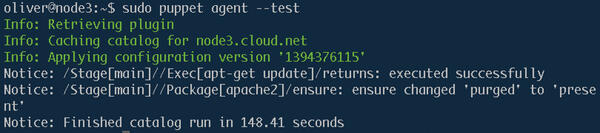 Bild 3: Mit der
korrekten Konfiguration wendet Puppet die Änderungen auf dem
Client-Rechner an.
Bild 3: Mit der
korrekten Konfiguration wendet Puppet die Änderungen auf dem
Client-Rechner an.
Ähnliche Artikel
- Konfigurationsverwaltung mit Puppet
-
Life Cycle Management mit Foreman und Puppet

-
Automatiserung mit Puppet

-
OpenStack einfach deployen mit Puppet und Kickstack

-
Puppet-Konfigurationsmanagement als Enterprise-Variante erhältlich
In der Enterprise-Version vereinfacht sich vor allem die Installation des Pakets.
Konfigurationsmanagement

Themen


