
Blktrace im Storage-Umfeld
Weil Blktrace [5] sich um den Zugriff auf Blockgeräte kümmert, ist es am besten direkt auf einem Storage-Server einzusetzen. Wer zum Beispiel einen NFS-Server betreibt, kann sich mit dem Werkzeug ansehen, wie der Zugriff auf das darunterliegende Dateisystem funktioniert. Das Gleiche ist bei einem verteilten Dateisystem wie Lustre auf den einzelnen Storage-Knoten möglich. Im Gegensatz zu den bisher besprochenen Programmen gibt Blktrace auch die IOPS aus, wenn auch nur summarisch. Ein weiteres Programm namens Seekwatcher [6] können Sie dazu verwenden, die Blktrace-Ergebnisse grafisch darzustellen.
MPI Strace Analyzer-Ausgabe "Schreibstatistik"
Wie Sie sehen, gibt es keine Software, die alle Informationen über ein komplexes Storage-Setup sammeln kann. Es ist eher eine Kombination von Iotop, Iostat, Collectl und Blktrace, die es ermöglicht, ein komplettes Bild zu zeichnen. Die einzelnen Daten zu korrelieren, ist allerdings nicht ganz einfach und erfordert vermutlich den Einsatz eigener Skripte. Wer dies macht, muss gleichzeitig noch die laufenden Anwendungen aufzeichnen, um herauszufinden, welche davon in welcher Weise Bedarf an Storage haben. Aus einem solchen Überblick geht jedoch nicht hervor, was eine Anwendung im Einzelnen macht, etwa in welcher Reihenfolge sie Lese- und Schreib-Requests absetzt oder andere I/O-Operationen wie Seeks startet. Um hierzu genauere Informationen zu bekommen, bedarf es einer weiteren Toolbox.
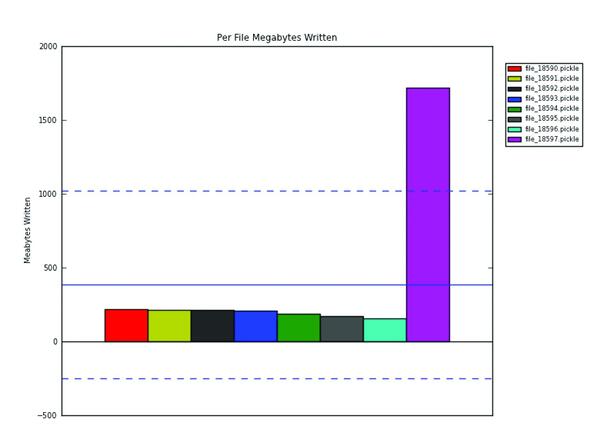 Bild 2: Durchschnittliche Schreibleistung der einzelnen Prozesse gemessen mit Strace. Die blaue Linie markiert den globalen Durchschnitt.
Bild 2: Durchschnittliche Schreibleistung der einzelnen Prozesse gemessen mit Strace. Die blaue Linie markiert den globalen Durchschnitt.
I/O-Auswertung mit Strace
Der Schlüssel zur Auswahl der richtigen Storage-Lösung liegt darin, die wesentlichen I/O-Muster für den Anwendungsfall zu identifizieren. Für diese nicht ganz einfache Aufgabe haben sich in der Vergangenheit einige Ansätze herausgebildet. Einer davon ist der Einsatz von Strace, das die System Calls eines Programms protokolliert. Ein möglicher Startpunkt für die Untersuchung ist ein Aufruf wie
strace -T -ttt strace.out Anwendung
Das Kommando startet eine Anwendung unter der Kontrolle von Strace und protokolliert die Aufrufe in der Datei strace.out. Die Option "-T" sorgt dafür, dass Strace die von einem Systemaufruf verbrauchte Zeit ausgibt. "-ttt" sorgt für einen Zeitstempel, der Mikrosekunden enthält. Die Ausgabe des obigen Befehls sieht etwa so aus:
1269925389.847294 write(17, " 37989 2136595 2136589 213" ..., 3850) = 3850
Diese Zeile enthält mehrere interessante Informationen. Die Menge der geschriebenen Daten erscheint nach dem Gleichheitszeichen, hier sind es 3.850 Bytes. Die dafür verbrauchte Zeit steht in spitzen Klammern dahinter, hier 0,000004 Sekunden. Die geschriebenen Daten stehen in den runden Klammern und sind abgekürzt, also nicht komplett zu sehen. Ein weiteres interessantes Detail ist das erste Argument der Write-Funktion, das den File-Deskriptor enthält. Wenn Sie sich in der Ausgabe von Strace die dazugehörigen Open-Anweisungen anschauen, finden Sie den Dateinamen heraus, der dem
File-Deskriptor entspricht.
Von hier ausgehend können Sie alle möglichen Statistiken für eine Anwendung anfertigen. Zum Beispiel können Sie die Anzahl der Read- und Write-Anwendungen zählen und sich ansehen, wie viele Daten dabei jeweils gelesen und geschrieben werden. Sie können auch die Anzahl der I/O-Aufrufe in einem bestimmten Zeitraum ermitteln, um zu einer Abschätzung der IOPS zu gelangen. Eventuell ist auch eine Aufschlüsselung nach Dateien interessant, wenn es für manche Files deutlich mehr Zugriffe gibt als für andere. Der nächste Schritt ist eine statistische Analyse der Zwischenergebnisse.
|
Anzahl der Aufrufe von I/O-Funktionen |
||||||||
|
Funktion |
file_18590.pickle |
file_18591.pickle |
file_18592.pickle |
file_18593.pickle |
file_18594.pickle |
file_18595.pickle |
file_18596.pickle |
file_18597.pickle |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Wenn Sie Strace verwenden, werden Sie allerdings mit Daten überhäuft, weil die Log-Dateien schnell viele Tausend Zeilen umfassen. Ein kleines Programm namens Strace-Analyzer [7] hilft dabei, sich nicht in diesem Wust zu verlieren. Es geht das Strace-Log durch und erstellt eine statistische Analyse, die es im HTML-Format ausgibt. Mit Hilfe der Matplotlib zeichnet es sogar Diagramme des Ergebnisses.
Wie bereits erwähnt bringt diese Methode nur das Ausführungsprofil einer einzelnen Applikation auf den Bildschirm. Etwas schwieriger wird es, wenn es sich um eine verteilte Anwendung handelt. Als Beispiel dafür kann ein Projekt dienen, das auf MPI basiert, dem Message Passing Interface, von dem es eine Open Source-Implementierung gibt und das gerne im HPC-Bereich zum Einsatz kommt. Mit Strace können Sie wie gezeigt von jedem einzelnen MPI-Prozess ein Profil anfertigen. Um die weitere Verarbeitung der einzelnen Dateien zu vereinfachen, erzeugt der Strace-Analyzer eine Pickle-Datei (ein Python-Serialisierungs-Format). Um alle Einzelergebnisse zusammenzuführen, nehmen Sie alle Pickle-Dateien und analysieren diese mit einem weiteren Tool, dem MPI Strace Analyzer [8], der einen prozessübergreifenden HTML-Report erzeugt.
|
Größe der Schreib-Requests |
||||||||
|
Funktion |
file_18590.pickle |
file_18591.pickle |
file_18592.pickle |
file_18593.pickle |
file_18594.pickle |
file_18595.pickle |
file_18596.pickle |
file_18597.pickle |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ähnliche Artikel
-
Strace hilft Fehler finden

- Tuning-Basics für Linux
-
ADMIN-Tipp: Welcher Prozess benutzt den Port?
"# Opening port: bind: Address already in use." Wie man mit diesem Malheur am besten umgeht und welche Tools es dafür gibt, verrät dieser ADMIN-Tipp.
-
ADMIN-Tipp: Dtruss - Strace-Ersatz für OS X
Unter Linux ist das Strace-Kommando bei der Fehlersuche oft das Tool der Wahl. Leider fehlt es beim BSD-basierten Mac OS X. Ein Dtrace-basiertes Skript bietet einen Ausweg.
-
Mailman 3.0 modernisiert
Die bewährte Mailinglisten-Management-Software wurde von Grund auf überarbeitet.
Konfigurationsmanagement

Themen


