Slave Promotion und offene Fragen
Es ist möglich, einen Slave-Server mit Hilfe einer Trigger-Datei in einen Master zu verwandeln. Dies kann notwendig sein, wenn der vormalige Master einem Totalschaden zum Opfer fiel, oder man aus anderen Gründen kurzfristig schreibende Abfragen auf der vormaligen SlaveDatenbank ausführen möchte. Um das zu erreichen, muss man den Parameter »trigger_file« in der »recovery.conf« auf dem Slave-Server auf eine beliebige nicht existierende Datei setzen. Der Slave kontrolliert dann regelmäßig, ob diese Datei angelegt wurde. Sobald sie existiert, beendet der Server die Replikation, benennt die »recovery.conf« in »recovery.done« um und versetzt sich selbst vom Recovery- in den normalen Betriebs-Modus.
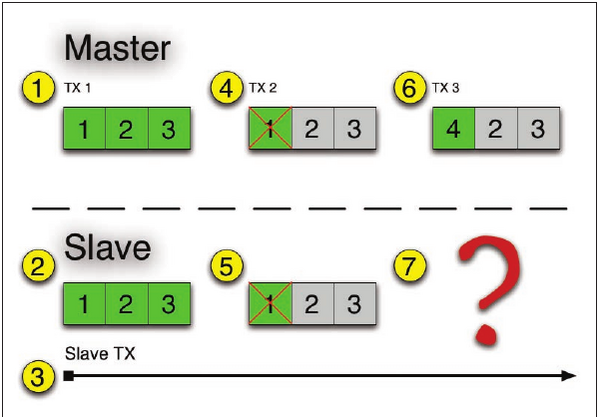 Abbildung 3: Der Master schreibt drei Datensätze (1), die der Slave übernimmt (2). Der startet danach eine lang laufende Transaktion (3), die diese Daten braucht. Inzwischen löscht der Master den ersten Datensatz (4) , was der Slave übernimmt (5). Der Master bereinigt den Speicher, die Daten sind damit verloren (6) und der Slave hat den Query Conflict (7).
Abbildung 3: Der Master schreibt drei Datensätze (1), die der Slave übernimmt (2). Der startet danach eine lang laufende Transaktion (3), die diese Daten braucht. Inzwischen löscht der Master den ersten Datensatz (4) , was der Slave übernimmt (5). Der Master bereinigt den Speicher, die Daten sind damit verloren (6) und der Slave hat den Query Conflict (7).
Genauso wie beim Log Shipping kann auch hier die Datenbank nicht wieder in den Slave-Modus zurückversetzt werden wenn sie mal als Master promoted worden ist. Möchte man den Slave-Betrieb wieder reaktivieren, muss man vom designierten Master eine komplette Datenbankkopie erstellen und diese wie schon beschrieben wieder in Betrieb nehmen.
Neben den Query Conflicts muss man auch berücksichtigen dass sich nur komplette Datenbankcluster, also Sammlungen an Datenbanken die sich das gleiche Datenbankverzeichnis teilen, replizieren lassen. Ausnahmen für einzelne Datenbanken oder Tables können derzeit nicht konfiguriert werden. Da die Datenbanken am Slave garantiert schreibgeschützt sind, ist es auch nicht möglich für den Slave spezifische Schemaänderungen wie etwa spezielle Indizes einzuführen. Alle Indizes die für den Betrieb benötigt werden, müssen auf allen Datenbanken identisch sein.
Fazit
PostgreSQL 9 bietet mit Streaming Replication & Hot Stand-by eine vom Projekt direkt gewartete Replikationsmöglichkeit, die es Anwendern erlaubt, eine asynchrone Master-Slave-Replikation aufzubauen, bei der die Slave-Server auch für lesende Abfragen verwendbar sind. Alle geschilderten Mechanismen garantieren die Datenintegrität, die man vom Betrieb nicht replizierter PostgreSQL-Datenbanken schon gewohnt ist. Sollten WAL-Einträge korrumpiert sein oder verloren gehen, weigert sich der Slave die Replikation fortzusetzen. Damit lässt sich gewährleisteten, dass der Slave-Server immer auf einen konsistenten Zustand der Datenbank zurückgreift.
Für andere Szenarien, die mehr Flexibilität fordern, gibt es im PostgreSQL-Wiki eine Übersicht [6] der derzeitigen Third-Party-Projekten, die sich mit dem Thema Replikation beschäftigen. Seit PostgreSQL 9.1 lässt sich die eingebaute Replikation auch im synchronen Modus betreiben. Damit kann gewährleistet werden, dass Master und Slave zu jedem Zeitpunkt die selben Daten gespeichert haben. In der demnächst erscheinenden PostgreSQL-Version 9.4 wird es unter dem Namen "Bi-Directional Replication "schließlich auch Support für Multi-Master-Replikation geben.
Für Fragen gibt es neben der umfangreichen Dokumentation das Wiki des Projekts, Mailinglisten sowie IRC-Kanäle. [7] Kommerzieller Support wird von vielen unabhängigen Unternehmen angeboten [8] (jcb/ofr)
Infos
[1] Slony: http://www.slony.info
[2] PGPool-II: http://pgpool.projects.postgresql.org
[3] ACID: http://en.wikipedia.org/wiki/ACID
[4] PITR: http://www.postgresql.org/docs/9.0/static/continuous‑archiving.html
[5] Replikationsvergleich: http://wiki.postgresql.org/wiki/Replication,_Clustering,_and_Connection_Pooling
[6] PostgreSQL Support: http://www.postgresql.org/support
[7] Professional Services für PostgreSQL: http://www.postgresql.org/support/professional_support
[8] Check_postgres: http://bucardo.org/wiki/Check_postgres
Der Autor
Michael Renner ist Mitglied der deutschen wie auch der europäischen PostgreSQL User Group und hält regelmäßig Vorträge zu aktuellen Themen rund um PostgreSQL. Seinen Lebens- und Schaffensmittelpunkt hat Michael Renner in Wien. Dortberät und betreut er als selbstständiger Dienstleister Unternehmen im Web-Umfeld in den Bereichen Softwareentwicklung, Skalierung von Systemen und operativem Betrieb.
Ähnliche Artikel
-
Bucardo 5.0 repliziert Datenbanken flexibler
Die neue Version der Datenbank-Replikationssoftware Bucardo ist nicht länger auf zwei Datenbanken beschränkt und kann außer mit PostgreSQL auch mit anderen SQL-Datenbanken umgehen.
-
Systeme: PostgreSQL 9.4

-
PostgreSQL 10 ist fertig
Die neue Version der freien SQL-Datenbank beschert Usern signifikante Verbesserungen.
-
PostgreSQL 9.1 veröffentlicht
Die PostgreSQL Global Development Group gibt die Verfügbarkeit einer neuen Version ihrer Datenbank, PostgreSQL 9.1, bekannt.
-
Hochverfügbarkeit und Replikation für PostgreSQL

Bucardo 5.0 repliziert Datenbanken flexibler
Die neue Version der Datenbank-Replikationssoftware Bucardo ist nicht länger auf zwei Datenbanken beschränkt und kann außer mit PostgreSQL auch mit anderen SQL-Datenbanken umgehen.
Konfigurationsmanagement

Themen


