DRBD HA leicht gemacht
DRBD HA leicht gemacht
DRBD [1] besteht aus einem Linux-Kernel-Modul und User-Space-Managementtools und bewerkstelligt die synchrone Replikation von Daten auf Blockebene zwischen zwei Rechnern. Im Zusammenspiel mit einem Cluster-Manager ermöglicht das ein automatisches Failover ohne Datenverlust, für das dennoch keine besonders teure Shared-Storage-Lösung nötig ist.
Replikation auf Ebene der Datenblöcke
Die Konfiguration von DRBD erzeugt immer ein zwei Cluster-Knoten umspannendes, repliziertes Blockdevice, dem wiederum auf jedem der beiden Nodes jeweils ein lokales Device (das so genannte Backing Device) zugeordnet ist. Als Backing Devices kommen grundsätzlich alle unter Linux verfügbaren Blockdevice-Typen in Frage – in der Praxis sind aber vor allem physische Partitionen, Software-RAID-Devices und LVM- oder EVMS-Volumes anzutreffen. DRBD legt auf diesen Backing Devices sowohl die zu replizierenden Nutzdaten als auch DRBD-spezifische Metadaten ab. Nach einer ersten Synchronisation steht dieses Device auf beiden Knoten zur Verfügung und kann danach auf einer Seite als Primary und auf der anderen Seite als Secondary fungieren.
Auf Devices im Primary-Status können Applikation aktiv schreibend zugreifen. Jede Schreiboperation hält dabei den folgenden Ablauf ein (Abbildung 1): Der zu schreibende Block landet zuerst auf dem lokalen Backing Device. DRBD markiert ihn in seinen Metadaten als inkonsistent und schickt gleichzeitig ein Replikationspaket per TCP zum zweiten Knoten. Der zweite Knoten (in der Rolle des Secondary) übernimmt das Replikationspaket und vollzieht die Schreiboperation auf seinem lokalen Backing Device nach. Anschließend sendet er ein Bestätigungspaket über das Netzwerk zurück. Nach Empfang dieses Pakets ändert der Primary den Status des betroffen Blocks wieder in „konsistent“. Erst zu diesem Zeitpunkt erhält die Applikation eine Nachricht über den erfolgreichen Abschluss der Schreiboperation. Dieser Ablauf gewährleistet, dass eine Schreiboperation aus Sicht der Applikation erst nach erfolgreichem Abschluss auf beiden Knoten als durchgeführt gilt.
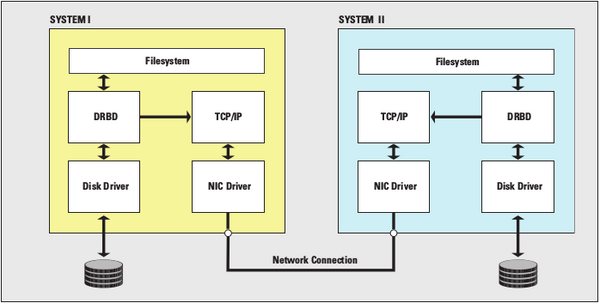 Abbildung 1: Kostengünstige Spiegelung mit DRBD: Lokale Speicherung und Versand via Netzwerk laufen gleichzeitig ab; die Schreiboperation gilt aber nur dann als abgeschlossen, wenn auch der zweite Knoten bestätigt, dass er die Daten empfangen und gesichert hat.
Abbildung 1: Kostengünstige Spiegelung mit DRBD: Lokale Speicherung und Versand via Netzwerk laufen gleichzeitig ab; die Schreiboperation gilt aber nur dann als abgeschlossen, wenn auch der zweite Knoten bestätigt, dass er die Daten empfangen und gesichert hat.
Effiziente Resynchronisation
Die Resynchronisation der Blockdevice-Daten nach einem Ausfall handhabt DRBD in besonders effizienter Weise: Statt einfach alle Daten eines Device vollständig neu zu synchronisieren, zieht DRBD zeitsparend tatsächlich nur jene Änderungen nach, die den Knoten betrafen, der während des Ausfalls aktiv war. Dafür setzt es zwei unterschiedliche Strategien ein, je nachdem, ob es sich beim ausgefallenen Knoten um den primären oder sekundären Knoten gehandelt hat.
Fällt der sekundäre Knoten aus, läuft die Applikation auf dem nach wie vor verfügbaren, primären Knoten unterbrechungsfrei weiter. An den Schreiboperationen ändert sich nichts, und die DRBD-Synchronitätsbitmap (siehe Kasten „Synchronitäts-Bitmap“) protokolliert sie.
Kehrt der sekundäre Knoten in den Cluster zurück, holt er das Schreiben derjenigen Blöcke nach, die zwischenzeitlich in der SynchronitätsBitmap markiert wurden. Das geschieht aber nicht in der chronologischen Reihenfolge der ursprünglichen Schreiboperationen, sondern stattdessen aufsteigend nach Sektoren, um so Kopfbewegungen und damit Synchronisationszeit zu sparen. Zusätzlicher Bonus: Bereits während der Nachsynchronisation lässt sich der wieder in den Cluster aufgenommene Knoten ohne weiteres auch in den Primärzustand versetzen; noch nicht lokal nachsynchronisierte Blöcke liest DRBD dann einfach über das Netzwerk von der Gegenseite.
Bei Ausfall des primären Knotens hat DRBD eine zusätzliche Herausforderung zu lösen. Da Schreiboperationen auf sein Backing Device immer simultan mit der Übermittlung des Datenpakets auf den sekundären Knoten ablaufen, kann in diesem Fall ein inkonsistenter Zustand entstehen – dann nämlich, wenn die Schreiboperation auf dem lokalen Backing Device bereits vollzogen ist, der sekundäre Knoten sie aber noch nicht abschließen konnte.
Synchronitäts-Bitmap
Mit Hilfe der Synchronitäts-Bitmap hält DRBD fest, welche Daten einesDevice auf einem Knoten im Augenblick mit denen des anderen Knotens synchron sind. Ein Bit in der Synchronitäts-Bitmap entspricht dabeieinem Datenblock auf dem Device. Fällt ein Knoten aus, laufen Schreiboperationen auf dem überlebenden Knoten normal weiter und bewirken das Setzen eines Bit in der Bitmap pro beschriebenem Block. Kehrtder ausgefallene Knoten wieder in den Cluster zurück, synchronisiert erlediglich jene Blöcke nach, die während des Ausfalls von Schreiboperationen betroffen waren. Danach setzt er die entsprechenden Bits zurückund stellt somit den konsistenten Cluster-Zustand wieder her.
Ähnliche Artikel





Konfigurationsmanagement

Themen


