Ein Beispiel
Als kurzes Beispiel soll ein ARP-Filter aus »/etc/ netsniff‑ng/rules« dienen, der die Arbeitsweise der Berkeley Packet Filter Sprache anschaulich macht. Der Filter-Parser behandelt dabei alle Zeilen, die nicht mit dem Format »{ 0xYY, X, X, 0xYYYYYYYY }«, (X: decimal, Y: hex) übereinstimmen, als Kommentar.
1: { 0x28, 0, 0, 0x0000000c },
2: { 0x15, 0, 1, 0x00000806 },
3: { 0x06, 0, 0, 0xffffffff },
4: { 0x06, 0, 0, 0x00000000 },
Die erste Zeile des Filters für ARP-Pakete beinhaltet eine Load-Instruktion, da die Kombination aus »LD (0x00) | H (0x08) | ABS (0x20)« den Wert »0x28« ergibt. Damit werden nun die 16 Bit am Offset »0xc«, die dem Ethernet Type Field entsprechen, in den Akkumulator kopiert. Die Anweisung in Zeile 2 entspricht der Befehlsklasse von JMP (»JMP (0x5) | JEQ (0x10) = 0x15«). Entsprechend wird durch den Opcode »JMP | JEQ« die Konstante aus »k« (»0x806«, der Ethernet Type Identifier für ARP) mit dem Inhalt des Akkumulators verglichen und je nach Ergebnis bedingt zum nächsten Opcode gesprungen. Gleicht nun der Inhalt des Akkumulators dem Wert »0x806«, so wird der Befehlszähler um den Wert in »jt« (hier: »0«) sowie um eins inkrementiert. Damit würde dieser auf Zeile 3 zeigen, welche eine Return-Anweisung beinhaltet, genauer »RET | k«. Weil »k« den Wert »0xffffffff« besitzt, wird dem Kernel mitgeteilt, dass er das Paket mit einer eine Snaplen von »0xffffffff« Byte zum Socket weiterreichen soll. Da Pakete nie eine derartige Länge erreichen können, gibt der Kernel das gesamte Paket an den Socket-Deskriptor weiter.
Für den Fall, dass der Akkumulator einen anderen Wert besitzt, beispielsweise »0x800« für IPv4-Pakete, wird der Befehlszähler auf Zeile 4 gesetzt, sodass eine Return-Anweisung mit »k=0« folgen muss. Das hat zur Folge, dass das aktuelle Paket den Filter nicht passieren kann und verworfen wird. Netsniff‑NG gibt den geparsten und validierten Filter in entsprechender Syntaxschreibweise aus:
(000) ldh [12] (001) jeq #0x806 jt 2 jf 3 (002) ret #‑1 (003) ret #0
Performance
Wie anfangs bereits erwähnt, war »netsniff‑ng« das erste Programm, das die Zero-Copy Funktionalität des Kernels (hier im Speziellem den RX_RING) in Anspruch nahm. Der RX_RING bewirkt auf effiziente Weise, dass der Kernel Netzwerkpakete nicht in den Userspace kopieren muss. Was das für Auswirkungen hat, soll ein einfaches Beispiel zeigen, dass die Kernelaktivität mittels »strace« sichtbar macht.
Hier wird zuerst ein Aufruf von »tcpdump« verfolgt, das im Gegensatz zu »netsniff‑ng« keinen RX RING benutzt. Lauscht dieser Sniffer nun auf Pakete, so zeigt Strace Ausgaben wie Listing 3. Zu sehen ist, dass pro empfangenem Paket ein Systemruf (»recvfrom(2)«) ausgeführt werden muss. Er verursacht unter anderem einen Kontextwechsel des Betriebssystems, welcher vergleichsweise viel Zeit in Anspruch nimmt sowie das Kopieren der Daten in den durch den Nutzer zur Verfügung gestellten Speicher. Die Ausgabe mit »write(2)« auf der Konsole ist dabei in den Listings 3 und 4 zu vernachlässigen, da man sie mit Kommandozeilenoptionen einfach unterdrücken kann.
Listing 3: Strace verfolgt einen »tcpdump«
recvfrom(3, "\377\377\377\377\377\377\0\32ME|\211\10\6\0\1\10\0\6\4"..., 96, MSG_TRUNC,
{sa_family=AF_PACKET, proto=0x806, if50, pkttype=PACKET_BROADCAST, addr(6)={1, 001a4d457c89}, [18]) = 60
ioctl(3, SIOCGSTAMP, 0xbfb43e70) = 0
write(1, "16:14:50.538813 arp who‑has 10.0"..., 5516:14:50.538813 arp who‑has 10.0.53.26
tell 10.0.63.10) = 55
recvfrom(3, "\377\377\377\377\377\377\0\4v\243\330\242\10\6\0\1\10\0"..., 96, MSG_TRUNC,
{sa_family=AF_PACKET, proto=0x806, if50, pkttype=PACKET_BROADCAST, addr(6)={1, 000476a3d8a2}, [18]) = 60
ioctl(3, SIOCGSTAMP, 0xbfb43e70) = 0
write(1, "16:14:50.624868 arp who‑has 10.0"..., 5616:14:50.624868 arp who‑has 10.0.63.53
tell 10.0.54.184) = 56
recvfrom(3, "\377\377\377\377\377\377\0\4v\243\330\242\10\6\0\1\10\0"..., 96, MSG_TRUNC,
{sa_family=AF_PACKET, proto=0x806, if50, pkttype=PACKET_BROADCAST, addr(6)={1, 000476a3d8a2}, [18]) = 60
ioctl(3, SIOCGSTAMP, 0xbfb43e70) = 0
write(1, "16:14:50.624989 arp who‑has 10.0"..., 5616:14:50.624989 arp who‑has 10.0.63.55
tell 10.0.54.184) = 56
Lauscht nun im anderen Fall »netsniff‑ng« auf Pakete (und verwendet dabei den RX_RING), dann ergibt Strace einen Auszug wie in Listing 4. Damit entfallen Systemcalls wie »recvfrom« und der Kernel muss kein »copy_to_user()« mehr aufrufen. Das hat eine bessere Performance zur Folge. Lediglich »poll(2)« wird gerufen, falls keine Daten mehr im Ringpuffer liegen. Damit kann lässt sich die CPU-Last verringern, weil der Prozess schlafen gelegt wird und erst bei neu anliegenden Daten wieder zurückkehrt, sofern dafür kein Timeout konfiguriert wurde.
Listing 4: Strace verfolgt »netsniff-ng«
poll([{fd=3, events=POLLIN|POLLERR, revents=POLLIN}], 1, ‑1) = 1
poll([{fd=3, events=POLLIN|POLLERR, revents=POLLIN}], 1, ‑1) = 1
write(2, "60 bytes from 00:10:5a:d8:9a:a4 "..., 5360 bytes from 00:10:5a:d8:9a:a4 to ff:ff:ff:ff:ff:ff) = 53
poll([{fd=3, events=POLLIN|POLLERR, revents=POLLIN}], 1, ‑1) = 1
write(2, "60 bytes from 00:30:48:c6:15:d0 "..., 5360 bytes from 00:30:48:c6:15:d0 to ff:ff:ff:ff:ff:ff) = 53
Warum ist eine gute Performance überhaupt wichtig? Bei hoher Netzwerklast ist es von Vorteil, so wenig Zeit wie nur möglich mit der Verarbeitung eines einzelnen Paketes zu verbrauchen und davon nur einen möglichst kleinen Anteil für Systemfunktionen, die mit der eigentlichen Verarbeitung vom Anwenderprogramm nur wenig zu tun haben, aufzuwenden. Je schneller die Verarbeitung eines einzelnen Paketes bewerkstelligt werden kann, umso mehr Pakete können auch pro Zeiteinheit bearbeitet werden. Schafft es die Maschine nicht mehr alle eintreffenden Pakete zu verarbeiten, so muss sie welche verwerfen, was man natürlich vermeiden will.
Der RX_RING bietet daher eine geeignete Möglichkeit, Zeit für Kopieroperationen und Kontextwechsel einzusparen. Dabei wird ein Ringspeicher per »setsockopt(2)« im Kerneladressraum allokiert und der virtuelle Speicher per »mmap« in den Userland-Adressraum gemappt. Somit teilen sich Kernel und Userland den RX_RING Speicher und mittels geeigneter Synchronisationsprimitiven wird entsprechend die Bereitschaft der einzelnen Frames des Rings ausgehandelt. In die Frames selbst werden vom Kernel die Netzwerkpakete hineingeschrieben. Dabei gibt es insgesamt zwei Kopieroperationen im Kernel. Das Netzwerk-Paket wird vom Treiber in die »sk_buff«-Struktur geschrieben und diese wiederum in einen freien Frame des Ringspeichers.
Der Ringspeicher selbst ist untergliedert in Blöcke und Frames. Dabei umfasst ein Block mindestens ein Frame und besteht aus nichtfragmentiertem Speicher des RAMs. Nichtfragmentierter Speicher wird im Allgemeinen in Vielfachen von Pages allokiert (beispielsweise im Kernel mittels »\__get_free_pages()«, sodass die Blockgröße ebenfalls ein Vielfaches der Page-Größe sein muss. Aus dem Userspace lässt sie sich beispielsweise mit »getpagesize« aus »unistd.h« einfach ermitteln. Die Anzahl der Frames pro Block sowie die Framegröße selbst müssen exakt in einen Block passen. Die Kerneldokumentation gibt dabei nähere Hinweise zur Berechnung unter »networking/packet_mmap. txt«.
Die Abbildungen 3 und 4 zeigen den typischen Pfad eines Netzwerkpakets vom der Netzwerkkarte zur Applikation unter Verwendung von »recvfrom« beziehungsweise des RX_RING. Der Ablauf bis zu »deliver_skb()« ist dabei für beide Varianten identisch. Wenn die NIC ein Paket erhält, so wird es in den RAM kopiert und ein Interrupt ausgelöst. Nachfolgend werden alle anderen Interrupts blockiert. Der Netzwerktreiber stellt den Interrupt-Handler (top half), der das Paket per DMA in den Arbeitsspeicher schreibt und dazu eine »sk_buff«-Struktur allokiert. Daraufhin wird die Funktion »netif_rx()« der »sk_buff«-Struktur aufgerufen, die das Paket mit einem Timestamp versieht und es in die jeweilige CPU-affine RX-Queue einfügt. Falls diese Queue voll ist, wird das Paket verworfen.
Im Anschluss wird der RX-SoftInterrupt-Handler (bottom half) beim Scheduler zur Ausführung eingereicht und der Interrupt-Handler kehrt zurück. Daraufhin werden auch alle anderen Interrupts wieder aktiviert. Ziel der TopHalf-Handler ist dabei so schnell wie möglich wieder zurückzukehren, da zum Zeitpunkt der Abarbeitung alle anderen Interrupts deaktiviert sind. Arbeitsintensive Aufgaben werden an den Bottom-Half-Handler abgegeben, der unterbrochen werden kann. Die Funktion »deliver_ skb()« übergibt darin die »sk_buff«-Struktur an den Protokoll-Handler, hier PF_PACKET. Je nach Konfiguration wird dann das Paket in einen freien Frame des RX_RINGs oder in die Receive-Queue von »recvfrom« kopiert.
Netsniff-NG, das den RX_RING verwendet, berechnet standardmäßig die Ringgröße automatisch und abhängig von der Netzanbindung, sodass bei modernen Links mit einem Gigabit oder mehr auch ein größerer Ring allokiert wird. Zum Feintuning wird mittels Netsniff-NG-Option »‑‑ring‑size« die nutzerdefinierte Größe eingestellt. Ferner kann »netsniff‑ng« auch per Option an eine bestimmte CPU gebunden werden, indem es dem Scheduler verbietet, seinen Prozess auf eine andere CPU zu migrieren. Wird diese Option verwendet, so versucht »netsniff‑ng« ebenfalls automatisch die Interrupt-Affinität der NIC auf die CPU zu binden, auf der es selber läuft, um weitere Performance zu gewinnen.
Dabei ist es sinnvoll »netsniff‑ng« mit der Option »‑‑silent« zu starten, sodass bei hoher Last das Terminal nicht die CPU-Load in die Höhe treibt. Die so empfangenen Daten können in diesem Fall durch »netsniff‑ng« in eine PCAP-Datei geschrieben werden, die sich dann zur genaueren Analyse bequem offline lesen lässt.
Am Rande sei noch erwähnt, dass die Verwendung von NAPI-Netzwerktreibern (New API) ebenfalls zur Performance des Systems beiträgt. Sie bewirken eine so genannte Interrupt Mitigation, so dass die NIC unter hoher Paketlast die CPU nicht mit tausenden von Interrupts unterbricht. Stattdessen erreichen nur wenige Interrupts die CPU und spezielle Kernel-Threads pollen periodisch auf die RX-Queues der Karte, sodass die CPU weniger belastet wird. Diese Treiber sind vor allem dann sinnvoll, wenn man Netzwerkmonitoring auf zentralen Endpunkten wie Routern betrieben will.
Auf einem IBM HS21 Blade mit 2 x Intel Xeon E5430 (2.66GHz), 8 GByte RAM und Broadcom GigabitEthernet-Karten wurden die Leistungen gemessen, die Abbildung 5 zeigt. Die Untersuchung selbst beinhaltet den Empfang der Pakete in einem RX_RING sowie das Zählen der eintreffenden Pakete und das Aufsummieren der Paketgrößen. Der RX_RING kann dank Zero-Copy maximal doppelt so viele Pakete verarbeiten wie »recvfrom« und eignet sich daher besonders ab Gigabit-Ethernet.
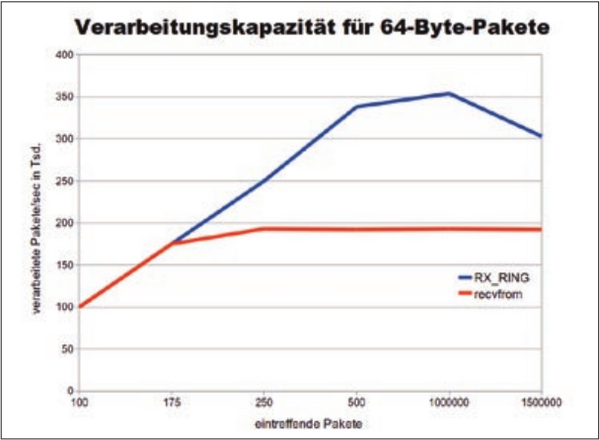 Abbildung 5: Benchmarks zeigt die Anzahl bei verschiedenen Paketraten verarbeiteter Pakete.
Abbildung 5: Benchmarks zeigt die Anzahl bei verschiedenen Paketraten verarbeiteter Pakete.
Ähnliche Artikel




Konfigurationsmanagement

Themen


