Performance-Analyse mit Collectd
Performance-Analyse mit Collectd
Collectd [1] ist modular aufgebaut: Sämtliche Funktionen sind durch Plugins implementiert. So gelingt es, architekturspezifische Details aus dem Code herauszuhalten. Stattdessen stellt der in C geschriebene Daemon, der auf jedem POSIX-konformen System wie Linux, Solaris oder BSD läuft, lediglich eine grundlegende Infrastruktur bereit.
Weil der Overhead einer Skriptsprache entfällt und der Daemon dauerhaft im Speicher bleibt, lässt er sich mit einer Standardauflösung von zehn Sekunden betreiben ohne einen nennenswerten Einfluss auf die Performance zu haben. Das ermöglicht auch den Betrieb auf leistungsschwacher Hardware, wie etwa WLAN-Routern oder anderen eingebetteten Systemen. Gleichzeitig kann die Software auch Tausende Datensätze in großen Umgebungen verwalten.
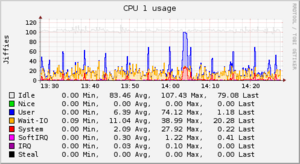
 Abbildung 1: Die von Collectd gesammelten Lastwerte der letzten Stunde. Gut zu erkennen ist die hohe Auflösung der gespeicherten Daten. Farblich hinterlegt ist ein 5-Minuten-Intervall – die Standardauflösung von vielen anderen Statistik-Sammlern.
Abbildung 1: Die von Collectd gesammelten Lastwerte der letzten Stunde. Gut zu erkennen ist die hohe Auflösung der gespeicherten Daten. Farblich hinterlegt ist ein 5-Minuten-Intervall – die Standardauflösung von vielen anderen Statistik-Sammlern.
In der jetzt aktuellen Version bringt Collectd über 100 verschiedene Erweiterungen mit. Die Palette reicht von einfachen Plugins, die Werte von Standardkomponenten wie beispielsweise CPU oder Speicher liefern, bis zu sehr spezialisierte Plugins, die äußerst detaillierte Informationen bereitstellen. Eine Übersicht über alle vorhandenen Plugins findet sich im Wiki des Projekts unter [2]. Eines der Grundprinzipien bei der Entwicklung von Collectd war Einfachheit. So reicht bereits das Laden entsprechender Plugins, um zu bestimmen, welche Werte abzufragen sind. Listing 1 zeigt eine minimale Konfiguration, die Statistiken zu CPU- und Speicher-Ausnutzung sowie zur Systemlast und zum Netzwerkverkehr sammelt und in RRD-Dateien [5] schreibt. Zudem erhält der Syslog-Daemon wichtige Informationen und Fehlermeldungen. Die Abbildungen 2 bis 4 zeigen Beispielgraphen, die aus den Daten einer solchen Konfiguration entstehen.
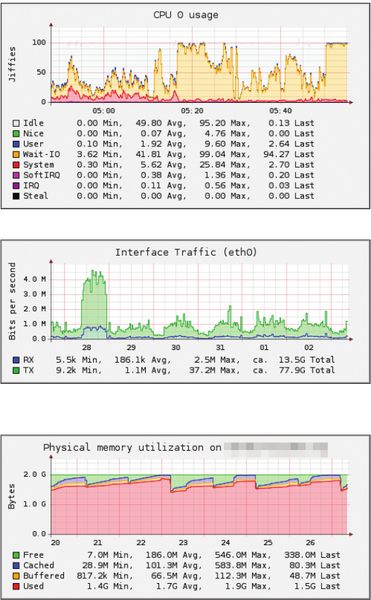 Abbildung 2 bis 4: Die CPU-Auslastung der letzten Stunde (oben). Das System verbringt einen großen Teil der Zeit damit, auf I/O-Operationen zu warten (oben). Mitte: Der Netzwerk-Traffic der vergangenen Woche. Vor sechs Tagen gab es einen auffälligen Ausreißer, dem nachgegangen der Admin nachgehen sollte. Unten: Auslastung des Arbeitsspeichers. Es bleibt wenig für die Caches des Betriebssystems übrig. Um etwa Festplatten-Zugriffe zu beschleunigen, empfiehlt sich eine Erweiterung des Speichers.
Abbildung 2 bis 4: Die CPU-Auslastung der letzten Stunde (oben). Das System verbringt einen großen Teil der Zeit damit, auf I/O-Operationen zu warten (oben). Mitte: Der Netzwerk-Traffic der vergangenen Woche. Vor sechs Tagen gab es einen auffälligen Ausreißer, dem nachgegangen der Admin nachgehen sollte. Unten: Auslastung des Arbeitsspeichers. Es bleibt wenig für die Caches des Betriebssystems übrig. Um etwa Festplatten-Zugriffe zu beschleunigen, empfiehlt sich eine Erweiterung des Speichers.
Die Plugins lassen sich in verschiedene Gruppen einteilen. Die wichtigsten Typen sind Lese-Plugins, deren Aufgabe die Abfrage von Leistungsdaten ist, Schreib-Plugins, welche die gelesenen Daten speichern oder weiter versenden sowie Log-Plugins, die Meldungen des Daemons oder von Plugins verarbeiten. Daneben gibt es Plugins mit spezielleren Aufgaben. Dazu gehört als wohl wichtigstes Beispiel der Filter-ChainMechanismus (siehe unten). Weiterhin gibt es Plugins, die beispielsweise beim Überschreiten von Schwellwerten Benachrichtigungen etwa in Form eines Popup-Fensters auslösen. Die Lese-Plugins bilden drei Kategorien:
- Betriebssystem-Plugins fragen Werte vom Betriebssystem ab. Da die dazu nötigen Schnittstellen in der Regel nicht standardisiert sind,sind diese Plugins meist an unterschiedlicheBetriebssysteme anzupassen. Beispiele dafür sind das Disk-Plugin, das Informationenzu Festplatten-Aktivitäten bereitstellt oderdas VMem-Plugin, das sehr detaillierte Statistiken über den virtuellen Speicher anbietet.
- Anwendungsplugins fragen Werte von bestimmten Anwendungen ab. Dazu sind häufigexterne Bibliotheken nötig, die Schnittstellenzu diesen Anwendungen zur Verfügung stellen. Die Plugins an sich sind jedoch unabhängig von einem Betriebssystem. Beispiele dafürsind das Apache-Plugin, das Webserver-Statistiken liefert oder das OpenVPN-Plugin.
- Generische Plugins stellen meist ein Framework bereit, das einen bestimmten Abfragemechanismus implementiert. Der Benutzerkann diesen über die Konfiguration steuernund so nahezu beliebige Werte ermitteln. EinBeispiel dafür ist das SNMP-Plugin, das Informationen über SNMP – beispielsweise vonNetzwerk-Hardware – abfragen kann.
Eine klare Abgrenzung zwischen diesen Kategorien ist nicht in jedem Fall möglich. So kann beispielsweise das PostgreSQL-Plugin über beliebig konfigurierbare SQL-Abfragen sowohl Informationen über das Datenbanksystem selbst, als auch dort gespeicherte Anwendungsdaten abfragen.
Installation von Collectd
Einige Linux-Distributionen sowie FreeBSD undNetBSD stellen vorkompilierte Pakete für Collectd zur Verfügung. So lässt sich der Daemonbeispielsweise unter Debian oder Ubuntu mitdem Befehl »apt‑get install collectd« installieren. Er steht dann mit einer Beispielkonfiguration sofort zur Verfügung.Sollte ein fertiges Paket nicht vorhanden sein,so kann der Admin ein Quellpaket von derProjekt-Webseite [1] herunterladen, kompilieren und installieren. Für den Daemon und einegroße Anzahl von Plugins sind dazu keine weiteren Bibliotheken erforderlich. Für die verbleibenden Plugins ist in der mitgelieferten Datei»README« dokumentiert, welche Abhängigkeiten erfüllt sein müssen. Wegen unerfüllterAbhängigkeiten deaktivierte Plugins werdenin einer Zusammenfassung am Ende eines »./configure«-Laufes aufgeführt. Weitere Detailszur Installation gibt es im Projekt-Wiki auf derSeite „First steps“ [3] oder auf der DownloadSeite [4]
Einige Plugins lassen sich konfigurieren. Zum Beispiel das Interface-Plugin: Standardmäßig sammelt es Informationen zu allen NetzwerkSchnittstellen, die im System vorhanden sind. Manchmal sind aber nicht alle Schnittstellen von Interesse, sondern nur eine Auswahl. Listing 2 zeigt, wie man das Plugin dazu bringt, das Loopback- (»lo«) und ein IPv6/IPv4-Tunnel-Interface (»sit0«) zu ignorieren. Wie in Listing 2 zu sehen ist, werden Pluginspezifische Konfigurationsparameter in einen »<Plugin Pluginname>«-Block eingeschlossen. Die Syntax ist dabei der des bekannten Webservers Apache angelehnt. Alle verfügbaren Konfigurationsoptionen der verschiedenen Plugins sind auf der Handbuchseite zur Konfiguration von Collectd (»collectd.conf(5)«) [6] dokumentiert – undokumentierte Features gibt es nicht.
Collectd vernetzen
Sehr häufig wird Collectd in größeren Installationen eingesetzt. Insbesondere dort möchte man die Daten zentral sammeln. Dafür bietet Collectd mit dem Network-Plugin die Möglichkeit, Daten an andere Instanzen zu versenden oder von diesen zu empfangen. Für den Transfer der Daten wird ein Collectd-eigenes, auf UDP basierendes Binärprotokoll verwendet. Das ermöglicht eine kompakte Darstellung der versendeten Informationen. Das Plugin kann in verschiedenen Modi betrieben werden, die beliebig kombinierbar sind. Abbildung 5 gibt eine schematische Übersicht seine Möglichkeiten.
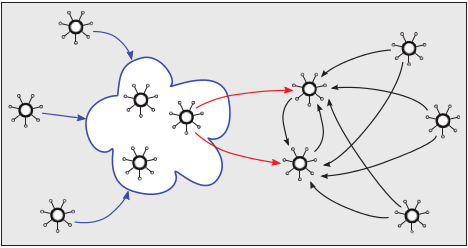 Abbildung 5: Auf der linken Seite sind einige Clients dargestellt, die ihre Daten an eine Multicast-Gruppe versenden (blau). Ein Server aus diesem Netzwerk leitet die Daten verschlüsselt an an zweites Netzwerk weiter (rot), das redundant ausgelegt ist und per Unicast Daten von weiteren Clients empfängt.
Abbildung 5: Auf der linken Seite sind einige Clients dargestellt, die ihre Daten an eine Multicast-Gruppe versenden (blau). Ein Server aus diesem Netzwerk leitet die Daten verschlüsselt an an zweites Netzwerk weiter (rot), das redundant ausgelegt ist und per Unicast Daten von weiteren Clients empfängt.
Listing 1: Minimale Konfiguration
LoadPlugin syslog LoadPlugin cpu LoadPlugin interfac LoadPlugin load LoadPlugin memory LoadPlugin rrdtool
Listing 2: Auswahl von Netzwerk-Interfaces
# ... LoadPlugin interface # ... <Plugin interface> Interface "lo" Interface "sit0" IgnoreSelected true </Plugin>
Im einfachsten und gleichzeitig häufigsten Fall gibt es einen Server der von mehreren Clients Daten per Unicast empfängt (Punkt-zu-Punkt-Verbindung). Dabei wird sowohl IPv4 als auch IPv6 unterstützt. Beide Versionen des Protokolls lassen sich dabei parallel und (durch Angabe von Hostnamen) für den Benutzer vollkommen transparent verwenden. Da die Client-Systeme die Daten selbst aktiv an den Server verschicken, spricht man hier von einem Push-Modell. Der Server kennt keine Liste von Clients, die er periodisch abfragt (Pull-Modell), sondern muss sich lediglich um die Verarbeitung einkommender Pakete kümmern. Das sorgt für eine höhere Flexibilität und Skalierbarkeit.
Neben dieser grundlegenden Funktionalität kennt das Network-Plugin auch die MulticastTechnologie (Punkt-zu-Gruppe-Verbindung). Dabei sendet ein Client Daten an eine Gruppe von Teilnehmern. Ein Server kann sich dieser Gruppe anschließen und erhält dann sofort und automatisch sämtliche an die Gruppe adressierte Inhalte. Durch die Möglichkeit, Versand und Empfang getrennt und unabhängig voneinander in einer Instanz zu konfigurieren, lassen sich die verschiedenen Betriebsmodi frei miteinander kombinieren und mehrere Ziele (auf dem Client) beziehungsweise Quellen (auf dem Server) parallel verwenden. Dies erlaubt weiterhin den Betrieb als Proxy, der beliebige Kombinationen der Übertragungstechniken mit den Netzwerkprotokollen auf beliebige andere Kombinationen umsetzen kann.
Seit der Version 4.7 unterstützt das NetworkPlugin Authentifizierung (Signieren) und Autorisierung (Verschlüsselung) von versendeten Daten. Damit ist es möglich, den Sender der Daten zu verifizieren beziehungsweise die Daten vor ungebetenen Mitlesern zu schützen. Weitere Informationen und viele Beispielkonfigurationen sind im Wiki auf der Seite „Networking introduction“ [7] zu finden.
Datenhaltung in Collectd
Ein fünfteiliger Bezeichner identifiziert alle Werte, die Collectd abfragt. Er setzt sich zusammen aus dem Rechnername, dem Plugin-Namen, einer optionalen Angabe einer Instanz des Plugins, sowie dem Typ des abgefragten Wertes und ebenfalls einer optionalen Instanz davon. Beispielsweise wird jede CPU in einem System als Instanz des CPU-Plugins angesehen und die verschiedenen Zustände, in denen sich die CPU
befindet, sind Instanzen des zugehörigen Datentyps. Der komplette Bezeichner lautet »Rechner‑ name/Plugin‑Plugin Instanz/Typ‑Typ Instance«. Entfallen die Plugin- oder Typ-Instanz, so wird auch der zugehörige Bindestrich weggelassen. Der Bezeichner findet sich beispielsweise auch im Dateiname der gespeicherten Daten wieder. Bis auf den Typ spielen die Inhalte des Bezeichners für Collectd keine weitere Rolle, sondern dienen nur der eindeutigen Identifizierung eines Datensatzes. Der Typ jedoch beschreibt die Daten in dem Datensatz und muss dem Daemon daher bekannt sein. Jeder Typ besteht aus einer oder mehreren Datenquellen, die jeweils einen Wert speichern. Der Typ »if_octets« wird beispielsweise für Netzwerk-Traffic verwendet. Ein Datensatz von diesem Typ besteht aus zwei Datenquellen, »rx« und »tx«, die den aktuellen Wert für eingehenden und ausgehenden Traffic beinhalten. Vordefinierte Typen sind in der Datei »types.db« beschrieben, die Collectd beim Programmstart einliest. Die Handbuchseite zu dieser Datei [8] enthält Informationen zur Syntax und zur Definition eigener Typen.
Ähnliche Artikel





Konfigurationsmanagement

Themen


