Generische Plugins
Generell setzt Collectd, soweit das sinnvoll ist, möglichst generische Mechanismen ein, weswegen man auf die Anpassung der Plugins gut verzichten kann, solange es nur um die Unterstützung für neue Varianten einer Datenquelle geht. So kann der Benutzer selbst die nötigen Erweiterungen an der Konfiguration vornehmen, ohne auf neue Versionen von Collectd angewiesen zu sein. Da ein einziges Plugin auf diese Weise viele ähnliche Datenquellen abfragen kann, bleibt das Verhalten konsistent. Aktuell steht bereits eine große Zahl solcher mächtiger Plugins zur Verfügung: »curl«, »curl_json«, »dbi«, »exec«, »filecount«, »GenericJMX«, »iptables«, »netapp«, »memcachec«, »oracle«, »ping«, »postgresql«, »snmp«, »table« und »tail«. Im Folgenden werden exemplarisch zwei davon vorgestellt.
Das SNMP-Plugin taugt dazu, verschiedene Informationen von Rechenzentrumshardware via SNMP abzufragen. Dabei muss der Anwender, angeben, wie diese Daten in die interne Darstellung von Collectd zu überführen sind. Diesem Zweck dient ein Data Block in der Konfigurationsdatei. Er gibt an, wie die Werte abzufragen sind und wie Collectd die Rohdaten auswerten und speichern soll. SNMP organisiert die Informationen in einer Baumstruktur und identifiziert sie an Hand einer Zahlenfolge – ihres so genannten Objekt-Bezeichners (engl.: object identifier, OID). Das konkret Gerät bezeichnet ein Host Block in der Konfiguration. Darin wird angegeben, wie das Gerät zu erreichen ist und in welchem Intervall es zu kontaktieren ist. Listing 3 zeigt die Definition von zwei NetApp-spezifischen Datentypen via SNMP. Für ein Fein-Tuning der zurückgegebenen Werte und Details zur Abfrage eines Geräts stehen noch weitere Konfigurationsparameter zur Verfügung. Details finden sich in der Dokumentation des SNMP-Plugins [9].
Im Projekt-Wiki gibt es unter [10] eine Sammlung vorgefertigter Daten-Definitionen für verschiedene Geräte, wie beispielsweise NetApp File-Server oder USV-Geräte (Unnterbrechungsfreie Stromversorgung). In manchen Fällen lassen sich wichtige Informationen nur aus Log-Dateien extrahieren. Das Tail-Plugin bietet die Möglichkeit, mit regulären Ausdrücken Werte aus Dateien zu extrahieren. In der Konfiguration des Tail-Plugins lassen
sich eine oder mehrere Dateien angeben. Dazu gehört jeweils eine Liste von regulären Ausdrücken, die auf jede Zeile der Datei anzuwenden sind. Dabei kann entweder ein Wert aus der Zeile extrahiert oder die Anzahl der übereinstimmenden Zeilen gezählt werden. Listing 4 zeigt, wie der Admin aus der Log-Datei des Postfix Mailservers Informationen über die Anzahl der geöffneten Verbindungen, sowie die Größe von übertragenen E-Mails sammelt. Das Plugin unterstützt verschiedene Methoden, um extrahierte Werte zusammenzufassen. Diese und andere Möglichkeiten des Plugins sind auf der Handbuchseite [11] dokumentiert.
Im Projekt-Wiki gibt es unter [12] eine Sammlung von vorgefertigten Konfigurationen für verschiedene Dienste, wie beispielsweise die EMail-Server Exim und Postfix.
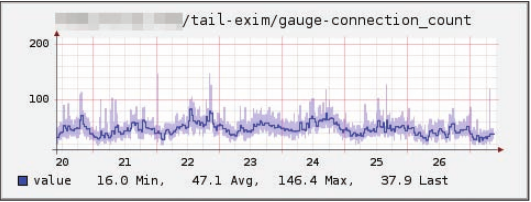 Abbildung 6: Anzahl der Verbindungen (pro Sekunde) zu einem Exim Mailserver. Diese Information wurde mittels dem Tail-Plugin aus den Log-Dateien von Exim extrahiert.
Abbildung 6: Anzahl der Verbindungen (pro Sekunde) zu einem Exim Mailserver. Diese Information wurde mittels dem Tail-Plugin aus den Log-Dateien von Exim extrahiert.
Listing 3: SNMP Konfiguration
# ... LoadPlugin snmp # ... <Plugin snmp> # Daten‑Definitionen <Data "netapp_cpu_system"> Type "cpu" Table false Instance "system" Values ".1.3.6.1.4.1.789.1.2.1.2.0" </Data> <Data "netapp_if_octets"> Type "if_octets" Table false Instance "net" Values ".1.3.6.1.4.1.789.1.2.2.12.0" ".1.3.6.1.4.1.789.1.2.2.14.0" </Data>
# abzufragende Geräte <Host "gw1.mydomain.tld"> Address "42.23.0.1" Version 2 Community "community_string" Collect "netapp_cpu_system" "netapp_octets" Interval 120 </Host> <Host "gw2.mydomain.tld"> Address "42.23.0.2" Version 2 Community "community_string" Collect "netapp_cpu_system" "netapp_if_octets" Interval 120
</Plugin>
 Abbildung 7: Last einer USV, die mittels SNMP abgefragt wurde. Etwa ein halbes Jahr zuvor wurde die Kapazität ausgebaut, was an dem Abfall der Last deutlich zu erkennen ist.
Abbildung 7: Last einer USV, die mittels SNMP abgefragt wurde. Etwa ein halbes Jahr zuvor wurde die Kapazität ausgebaut, was an dem Abfall der Last deutlich zu erkennen ist.
Daten filtern
Seit der Version 4.6 bietet Collectd mit dem Filter-Chain-Mechanismus eine mächtige Infrastruktur zur flexiblen Verarbeitung der gesammelten Daten. Damit ist es möglich Werte zu ignorieren, zu modifizieren oder nur an bestimmte Ausgabe-Plugins zu senden. Dies ist beispielsweise nützlich, wenn ein Plugin selbst keine Auswahl von bestimmten Datensätzen unterstützt oder diese Auswahl nicht auf einem ausreichend fein-granularem Level möglich ist. Weiterhin ermöglicht das beispielsweise das Umbenennen kryptischer Namen (etwa aus LM-Sensors) in verständliche Bezeichner.
Das grundsätzliche Konzept ist von dem Netfilter/IPtables-Subsystem des Linux Kernels inspiriert. Die gesammelten Werte werden an sogenannte Chains übergeben. Derzeit existieren zwei solcher Chains – eine bearbeitet die Werte bevor sie in den globalen Cache von Collectd gelangen (»PreCacheChain«) und eine andere danach (»PostCacheChain«). Der Cache dient dazu, gesammelte Werte über externe Schnittstellen (etwa das Unixsock-Plugin) verfügbar zu machen, um Zählerwerte in Raten zu konvertieren und fehlende Werte zu erkennen. Das Umbenennen von Bezeichnern sollte in der Regel in der »PreCacheChain« passieren, da sonst die Ergebnisse beim Zugriff auf den Cache nicht mit den Daten auf der Festplatte übereinstimmen. Andererseits kann es Sinn machen, Daten erst in der »PostCacheChain« zu verwerfen – sie können dann weiter abgefragt und mit anderen Anwendungen weiterverarbeitet werden, landen aber nicht auf der Festplatte.
Die Abarbeitung der Werte geschieht mittels sogenannter Matches und Targets. Matches wählen einen Wert an Hand verschiedener Kriterien
aus (zum Beispiel anhand eines regulären Ausdrucks). Ein Target definiert eine Aktion, die auf oder mit dem Wert ausgeführt wird (wie das Ändern des Bezeichners oder das Ignorieren eines Datensatzes). Mehrere Matches und Targets zusammengefasst bilden eine Filterregel. Wenn alle Matches der Regel auf einen Wert zutreffen, dann werden die Targets der Reihe nach ausgeführt. Mehrere Filterregeln bilden schließlich eine Chain. Bei ihrer Abarbeitung werden die angegebenen Filterregeln der Reihe nach ausgeführt. Weiterhin lässt sich ein Default Target angeben, das nach Abarbeitung von allen Filterregeln ausgeführt wird. Verschiedene Matches innerhalb einer Filterregel werden mit »und« verknüpft, während Matches von verschiedenen Filterregeln mit »oder« verbunden sind. Die Abarbeitung von Filterregeln und Chains ist durch den Rückgabewert eines Targets beeinflussbar. Er gibt an, ob die Abarbeitung einer Chain abgebrochen oder der aktuelle Datensatz an das nächste Target beziehungsweise die nächste Filterregel weitergegeben wird. Im ersten Fall kann der Filtermechanismus die Abarbeitung des Datensatzes entweder komplett abbrechen oder an den Aufrufer (in der Regel den Daemon selbst oder aber eine andere Chain) zur weiteren Verarbeitung zurückgeben.
Details zur Konfiguration der Filter Chains finden sich auf der Handbuchseite der Konfigurationsdatei von Collectd [6].
Listing 4: Tail-Plugin Konfiguration
<File "/var/log/mail.log"> Instance "postfix"
<Match> Regex "\\<postfix\\/smtpd\\[[0‑9]+\\]: connect from\\>" DSType "CounterInc" Type "mail_counter" Instance "connection‑in‑open" </Match> # ... <Match> Regex "size=([0‑9]*)" DSType "CounterAdd" Type "ipt_bytes" Instance "size" </Match>
</File>
Ähnliche Artikel





Konfigurationsmanagement

Themen


