Bremse Komplexität
Das Defizit bei der I/O-Performance hat aber noch einen zweiten Grund: Das I/O-Subsystem unter Linux ist sehr komplex, doch seine Komponenten sind oft unzureichend aufeinander abgestimmt. Wie schnell eine Applikation die angeforderten Daten erhält, hängt unter anderem ab
- von der Geschwindigkeit der Festplatte
- vom in die Platte integrierten Controller und Cache
- vom Bussystem zwischen der Platte und dem Controller
- vom Controller des Rechners
- vom Treiber des Betriebssystems
- vom I/O-Scheduler der Betriebssystems
- vom Disk Cache
- von Typ und Einstellung des Filesystems
- vom Zugriffsmuster der Applikation
Viele Komponenten auf diesem so genannten I/O-Path wissen nichts voneinander und können sich in die Quere geraten. Außerdem puffern sie die Daten unter Umständen mehrfach und verschwenden mit unnötigen Kopieraktionen Rechenzeit.
Das I/O-Subsystem
Das alles macht es für den Performance-Analysten nicht gerade einfacher. Um sich orientieren zu können, braucht er zunächst unbedingt eine Vorstellung vom schematischen Aufbau des I/O-Subsystems (Abbildung 1).
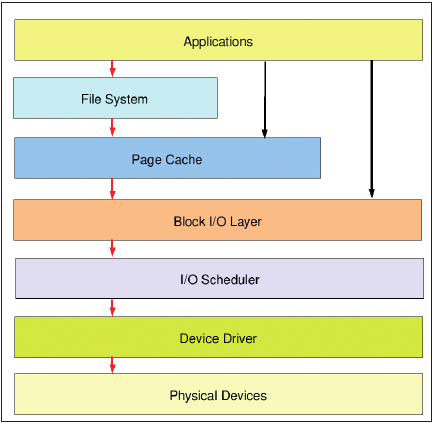 Abbildung 1: Der schematische Aufbau des I/O-Subsystems unter Linux.
Abbildung 1: Der schematische Aufbau des I/O-Subsystems unter Linux.
Die oberste Schicht unterhalb der Applikationsebene bildet das Filesystem. Es verbirgt die physische Struktur der Blockgeräte vor dem menschlichen Anwender und seinen Programmen und bietet ihm anstelle der Blocknummern, Spuren und Sektoren einen einfacher zu handhabenden Namensraum mit Datei- und Verzeichnisnamen. Daneben speichert es Metadaten wie Zeitstempel oder Attribute.
Unterhalb des Filesystems verwaltet das Betriebssystem einen Cache, der die geringe Zugriffsgeschwindigkeit der Massenspeicher teilweise kompensiert, indem er Anfragen nach kürzlich gelesenen Daten aus dem schnellen RAM bedient und vermutlich benötigte bereits vorausschauend puffert (Read Ahead). Auch Schreiboperationen aktualisieren die Daten zunächst im Cache und kopieren sie erst auf die Platte, wenn sich eine Anzahl zusammenhängender Blöcke ergeben hat (Write Behind).
Die Zugriffe selber steuert eine weitere Abstraktionsschicht, der Block I/O Layer, der eine einheitliche Schnittstelle zu allen Blockgeräten bietet. Der Linux-Kernel erhielt mit der Version 2.6 einen in weiten Teilen neu geschriebenen Block I/O Layer der viele Altlasten der Vorgängerversion – etwa die Beschränkung auf zwei TByte – über Bord werfen konnte.
Zwischen Block I/O Layer und den Treibern findet sich eine Komponente, die gar nicht zwingend notwendig wäre (und tatsächlich verzichten manche Unixe auch ganz darauf): der I/O-Scheduler. Seine Aufgabe ist es, die Reihenfolge der Schreib- und Leseanforderungen so neu zu ordnen, dass sie die Festplatte möglichst effektiv – das heißt vor allem mit wenigen Kopfbewegungen – verarbeiten kann. Es gibt verschiedene Scheduler mit jeweils eigenen Strategien.
Aus der Perspektive des I/O-Schedulers ist der Block Layer die Quelle der I/O-Requests und der Treiber, der seinerseits direkt mit der Hardware kommuniziert, ihr Ziel. Das Problem dabei ist: Der I/O-Scheduler ist nicht die einzige Komponente mit diesem Anliegen. Unter anderem versucht die Festplatte selber mit eigener Intelligenz ebenfalls die Reihenfolge der Requests zu optimieren. Da sich Platte und Scheduler dabei aber bislang nicht abstimmen können, kann sich der Effekt durchaus ins Gegenteil verkehren.
Die unterste Ebene bildet die Hardware, deren Vermögen natürlich die Grundlage der erreichbaren Performance legt. Manchmal gerät das aus dem Blick: Aber eine alte IDE-Platte macht kein noch so raffinierter Performance-Kniff zum Renner. Als Anhaltspunkt zeigt Abbildung 2 die maximalen Transferraten einiger Festplatten-Schnittstellen.
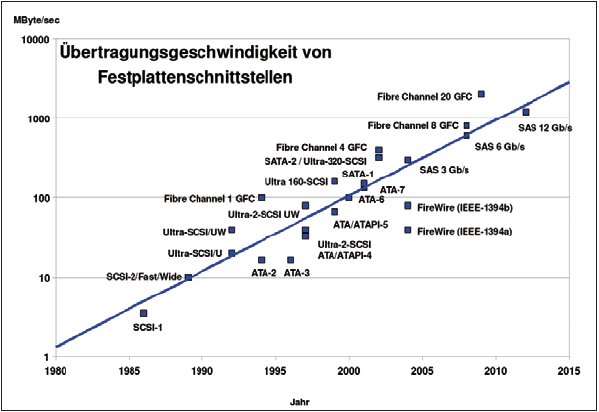 Abbildung 2: Die Entwicklung der maximalen Transferraten einiger Festplattenschnittstellen in den letzten Jahrzehnten und der nahen Zukunft.
Abbildung 2: Die Entwicklung der maximalen Transferraten einiger Festplattenschnittstellen in den letzten Jahrzehnten und der nahen Zukunft.
Ähnliche Artikel





Konfigurationsmanagement

Themen


