Transaktionen realisiert durch Copy-on-Write
Der Mechanismus, der die Transaktionen auf den Platten realisiert, heißt Copy-on-Write. Er funktioniert so, wie in Abbildung 2 dargestellt.
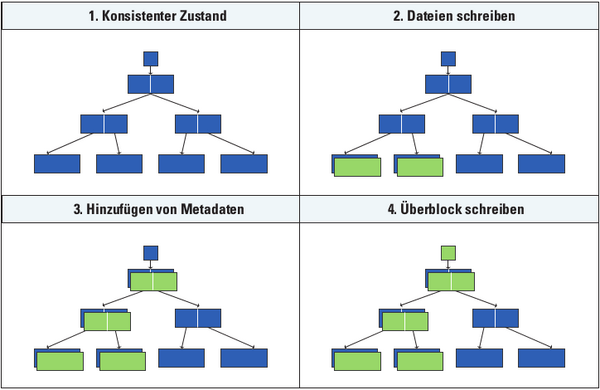 Abbildung 2: Das Schreiben einer Datei vollzieht sich in ZFS in einem mehrstufigen Prozess, der die Konsistenz für jeden Schritt garantiert. So ist auch im Problemfall kein aufwendiges Recovery nötig."]
Abbildung 2: Das Schreiben einer Datei vollzieht sich in ZFS in einem mehrstufigen Prozess, der die Konsistenz für jeden Schritt garantiert. So ist auch im Problemfall kein aufwendiges Recovery nötig."]
1. Man geht vom konsistenten Zustand aus, bei dem das Filesystem mit den blauen Blöcken vollständig in Ordnung ist. Die Daten liegen dabei nur in den Blättern des Baumes. Die inneren Knoten des Baumes enthalten lediglich Zeiger und keine sonstigen Daten. Die separat gespeicherte Wurzel des Baumes heißt bei ZFS Überblock („uberblock“ im Amerikanischen).
2. Nun sind ein paar Dateien zu schreiben. ZFS sucht dafür freie, momentan unbenutzte Blöcke (im Bild sind diese Blöcke grün hervorgehoben), es überschreibt niemals belegte. Außerdem achtet es darauf, dass die Blöcke möglichst beieinander liegen, um effizient schreiben zu können. Noch gelangen die Daten aber nicht auf die Platte, weil sonst die Transaktion nicht mehr rückgängig zu machen wäre.
3. Irgendwann schließt das Betriebssystem die Transaktion ab (commit). Dazu ist der Baum bis zur Wurzel zu aktualisieren. Der linke Block in der mittleren Ebene erhält die Zeiger auf die beiden neuen Datenblöcke. Der linke Block auf der Ebene darüber erhält links den Zeiger auf den eben modiffizierten Block, und rechts wird der unveränderte Teil eingetragen. Dieser Schritt fasst in der Regel mehrere Schreibvorgänge in einer so genannten Transaktionsgruppe zusammen.
4. Nun ist alles vorbereitet, um die Transaktion endgültig zu beenden. Dazu schreibt ZFS den Überblock (im Bild: kleines Quadrat). Ist der neue Überblock erzeugt, dann sind die eben erstellten Blöcke im Filesystem aktiv. Bricht das System aus irgendeinem Grund ab (»halt«-Kommando an der Konsole, Systemabsturz, Stromausfall, ...), dann existiert noch der alte Überblock und damit der alte Zustand in den blauen Blöcken, denn das Filesystem beschrieb lediglich Blöcke, die im Ausgangszustand (blau) unbenutzt waren.
Allerdings bestünde die Gefahr, dass beim Schreiben des Überblocks etwas schief geht und er unvollständig bleibt. Das Filesystem würde dadurch unbrauchbar. Um diese Gefahr abzuwenden, implementiert ZFS verschiedene Mechanismen:
- Zum einen gibt es nicht nur einen Überblock,sondern eine Liste von 128 Überblöcken, die ZFS zyklisch benutzt. Damit ist der vorigeÜberblock noch da, sollte es beim Schreibenein Problem geben.
- Zum anderen ist der Überblock mit einerlaufenden Nummer (Transaktionsgruppen-Nummer) versehen und mit einer Prüfsumme geschützt. Damit kann man feststellen, welches der neueste Überblock ist(höchste Transaktionsgruppen-Nummer),der korrekt auf der Platte landete.
- Außerdem ist der Überblock viermal pro Device vorhanden – je zweimal am Anfang undam Ende des Datenbereiches. Man kann alsonach einem Systemabbruch schnell den aktuellsten Überblock finden und hat damit einenkonsistenten Zustand des Filesystems.
ZFS mit Linux
Aus lizenzrechtlichen Gründen ist es nach Meinung von Experten nicht möglich, den Quellcode von ZFS in den Linux-Kernelbaum zu integrieren. Das Ergebnis vieler Diskussionen zu diesem Thema war,dass die GPL, unter der der Kernel lizenziert ist, nicht kompatibel zur CDDL ist, unter der Sun den ZFS-Code freigegeben hat. Die erste Lösung dieses Problem bestand darin, ZFS im Userspace zu implementieren und über die FUSE-Schnittstelle mit dem Kernel zu verbinden, wie es auch andere Projeke getan haben, die lizenzrechtlich inkompatibel mit der GPL sind.
ZFS on FUSE bietet heute die meisten Features, die im freigegebenen Quellcode enthalten sind, etwadynamischen Striping (RAID-0), Spiegelung (RAID-1),RAID-Z, RAID-Z2, ZVols, NFS, Kompression, Fehlerkennung und Selbstheilung sowie Clones und Backup.
Die bessere Alternative ist aber mittlerweile das native ZFS on Linux (http://zfsonlinux.org), das vom Lawrence Livermore National Laboratory gestartet wurde, um das verteilte Lustre-Dateisystem mit ZFS-Support auszustatten. Das Projekt implementiert einen Solaris Porting Layer (SPL), über den sich der existierende ZFS-Code einfacher mit dem Linux-Kernel integrieren lässt.
Der juristische Kniff zur Umgehung der Lizenz-Kompatibilität besteht darin, den ZFS-Code nicht zusammen mit dem Quellcodes des Linux-Kernels auszuliefern, wie die FAQ des Projekts erläutert:
The ZFS code can be modified to build as a CDDL licensed kernel module which is not distributed as part of the Linux kernel. This makes a Native ZFS on Linux implementation possible if you are willing to download and build it yourself.
Eine Zeit lang hat die Firma KQ Infotech ebenfalls an einem ZFS-Port auf Linux gearbeitet. Mittlerweile ist das Projekt aber eingestellt und die Arbeit in ZFS on Linux eingeflossen.
Nach Meinung der Entwickler ist ZFS on Linux seit Version 0.6.1 reif für den produktiven Einsatz.Seit Version 0.6.3 unterstützt ZFS on Linux auch POSIX-ACLs und ist kompatibel zum Init-System Systemd, womit sich das Dateisystem besser in moderne Linux-Distributionen integrieren lässt.
Über die folgenden Adressen lassen sich die entsprechenden Repositories einbinden, um ZFS on Linux zu installieren.
- Debian: deb http://archive.zfsonlinux.org/debian wheezy main
- Fedora: rpm http://archive.zfsonlinux.org/fedora/$releasever/$basearch
- Red Hat/CentOS: rpm http://archive.zfsonlinux.org/epel/$releasever/$basearch
- Ubuntu: deb http://ppa.launchpad.net/zfs-native/stable/ubuntu _Ubuntu-Version_ main
Sind einige Überblöcke nicht geschrieben worden, muss das Filesystem zur Reparatur nur diese Schreiboperationen wiederholen, das heißt das Recovery von ZFS erfolgt mit maximal vier Block-Writes pro Platte im ZFS-Pool. Die Daten selbst sind ja schon konsistent und komplett, weil der Überblock erst im Anschluss abgelegt wird. Stimmt die Prüfsumme beim neuesten Überblock nicht, dann ist der alte Zustand des Filesystems mit dem zweitjüngsten Überblock in sich konsistent.
Die Metadaten über Allokation und Dateiattribute liegen bei UFS (Inodes) oder PCFS/VFAT (Rootdir, FAT) in besonderen Bereichen des Filesystems. ZFS speichert die Metadaten (zum Beispiel Dateiattribute) in einem Zpool-Objekt, genau wie eine normale Datei. Sobald Schritt 3 die Blöcke allokiert, modifiziert es auch die in anderen Blättern des Baumes liegenden Metadaten, indem es die neuen Datenblöcke als benutzt kennzeichnet und die alten Datenblöcke freigibt.
Der Mechanismus ist der gleiche wie beim Schreiben der Datenblöcke. Die Pfade der inneren Knoten bis zur Wurzel des Baumes zu den Daten und den Metadaten vervollständigt ZFS parallel. Mit dem Schreiben des Überblocks kennzeichnet es gleichzeitig die neuen Datenblöcke als benutzt, gibt die alten wieder frei und aktualisiert die Attribute. Damit ist sichergestellt, dass auch bei den Metadaten entweder der alte oder der neue Zustand gilt. Das Filesystem ist so zu jedem Zeitpunkt in sich konsistent und der Aufwand für ein Recovery nach einem Abbruch minimal.
Beispiele für ZFS-Kommandos
zpool create test c2t0d0
Dieses Kommando erzeugt auf der gesamten Platte unter»/dev/dsk/c2t0d0« einen neuen ZFS-Pool namens »test« mitsamt einem Filesystem. Dieses Dateisystem wird unter »/test«gemountet und so in die Systemkonfiguration eingetragen, dass es beim nächsten Reboot automatisch wieder an derselben Stelle erscheint. Die nötigen Informationen speichertder Zpool, so dass sie auch nach dessen Export und Importauf einem anderen System wieder verfügbar sind.
zpool create tank mirror c3t0d0 c4t0d0
Dieser Befehl erzeugt einen gespiegelten Zpool. Für RAID-5artige Speicherung verwendet man statt »mirror« das Schlüsselwort »raidz« und die entsprechende Menge von Platten.Als Datenspeicher können auch Partitionen der Plattendienen oder normale Dateien (für Tests). Das Kommandokommt sofort zurück, egal wie groß die Platten sind, weil esdie Daten nicht vorsorglich spiegelt, sondern erst während des Schreibens. Dies ist ein weiterer Vorteil des integrierten Volume-Managers.
zpool add tank mirror c3t1d0 c4t1d0
Dieses Kommando vergrößert den Zpool-Tank um zwei gespiegelte Platten.
zfs create tank/home zfs set mountpoint=/export/home tank/home zfs set compression=on zfs set mountpoint=none tank
Diese Kommandosequenz erzeugt ein hierarchisch untergeordnetes Filesystem, setzt dessen Mountpoint auf »/export/home« und schaltet die Kompression dafür ein. Der Zpool-Tank soll in diesem Fall nicht mehr gemountet werden.
zfs create tank/home/anna zfs create tank/home/bertram zfs create tank/home/christa zfs set compression=off tank/home/christa zfs set mountpoint=legacy tank/home/bertram
Die oben aufgeführten Kommandos erzeugen weitereDateisysteme unterhalb von »tank/home« und ergänzen dabei die Mountpunkte logisch derart, dass aus »tank/home/anna« automatisch »/export/home/anna« wird. Die Directories erzeugt es automatisch. Die Filesysteme erben ebenfallsdie eingeschaltete Kompression. Für den User Christa wird sielokal ausgeschaltet. Das Filesystem »tank/home/bertram«soll ZFS nicht automatisch mounten, statt dessen montiertes der Anwender wie früher über die »vfstab« und/oder das»mount«-Kommando.
zfs set quota=66g tank/home zfs set reservation=50g tank/home/christa
Diese Befehle limitieren den für »tank/home« nutzbaren Platzauf insgesamt 66 GByte, wobei der User Christa 50 GByte festreserviert erhält. Alle anderen User können demzufolge zusammen maximal 16 GByte anlegen was auch via »df« fürsie erkennbar ist.
zfs export tank
Das obige Kommando exportiert den ZFS-Pool »tank«, dendanach ein anderes System mit dem Kommndo »import«wieder importieren kann. Die Mounteinträge (sofern vorhanden) und alle anderen Attribute wandern zusammen mitdem Zpool zum neuen Host. Diese Beispiele sollen die vereinfachte Administration mit ZFS belegen. Eine vollständige Listealler ZFS- und Zpool-Kommandos und ihrer Optionen findetsich unter [2].
Snapshots – implementiert als Funktion des Dateisystems
Snapshots bezeichnen eine Kopie eines Filesystems zu einem bestimmten Zeitpunkt, die nicht mehr veränderlich ist. In ZFS lässt sich ein solcher Snapshot sehr einfach herstellen: Man merkt sich lediglich den Zeiger auf den Wurzelknoten des Filesystems und hat damit den Snapshot ohne großen Aufwand bereits realisiert. Bei den Metadaten braucht man nur die Unterschiede zu verwalten. Ein Snapshot braucht zusätzlich eine Liste der Blöcke, die er referenziert (Referenzliste), – sie wird mit der Used-Liste für das Filesystem initialisiert. Die Used-Liste des Snapshot ist dagegen zu Beginn leer, da die Blöcke alle dem Filesystem gehören. Das Filesystem selbst kann sich weiter entwickeln, in seiner Used-Liste kommen dann weitere Blöcke hinzu. Gibt das Dateisystem Blöcke frei, dann prüft es, ob der letzte Snapshot diesen Block benötigt. Trifft das zu, wird der Block in die Used-liste des Snapshot eingetragen, dem er nun gehört. Das Löschen eines Snapshot behandelt die Blöcke genauso. Es prüft die Referenzliste des jüngsten Snapshot (sofern vorhanden) und überantwortet ihm die noch benötigten Blöcke. Für einen Snapshot braucht es so keinerlei Kopieraktionen. Der Snapshot wird lediglich benannt und der Root-Pointer sowie die Allokationsliste des Filesystems als Referenzliste mit Copy-on-Write dupliziert. Das sind alles Aktionen, die nicht viel mit der Datenmenge im Filesystem zu tun haben, daher sind Snapshots in ZFS sehr schnell.
Beispiele für ZFS-Kommandos (Fortsetzung)
Backup/Restore mit ZFSDurch die einfache Einbindung von Snapshots ist es leichtmöglich, das Filesystem zu einem Zeitpunkt konsistent zu sichern. Einen Snapshot erzeugt
zfs create tank/home/anna@monday
Der Snapshot erscheint automatisch im Root-Verzeichnis desFilesystems, im Beispiel also unter »/export/home/anna/.zfs/snapshot/monday«. Allerdings sind die Vorgaben konfigurierbar. Der Snapshot enthält die Daten von »/export/home/anna« zum Zeitpunkt des Kommandos und ist nicht schreibbar. Das ursprüngliche Filesystem bleibt die ganze Zeit überweiter benutzbar. Mit dem Kommando
zfs clone tank/home/anna@monday tank/home/anna_recov
kann man eine schreibbare Variante des Snapshot erzeugen. Dieses Filesystem ist separat mountbar, bleibt aber vomSnapshot abhängig. Die Abhängigkeiten kann man mitzfs promote tank/home/anna_recov
kappen, und danach ist es möglich, den Snapshot und dasalte Filesystem zu löschen.Eine andere Möglichkeit für eine Sicherung ist die Serialisierung eines Snapshot:
zfs send tank/home/anna@monday > /tmp/anna.zfssend
Dies erzeugt eine serielle Form des Dateisystems, die manwieder als neues Filesystem auf dem gleichen oder einemanderen Rechner einlesen kann.
zfs receive restore/anna < /net/server/tmp/anna.zfssend
Man kann auch inkrementell arbeiten und nur die Unterschiede zwischen zwei Snapshots serialisieren, beispielsweisezwischen Montag und Dienstag:
zfs send -i tank/home/anna@monday tank/home/anna@tuesday >...
Weitere Funktionen im Überblick
ZFS kann durch die Nutzung des Schreib-Cache von Plattendie Performance erhöhen, ohne dass bei einem Stromausfall Daten verloren gehen. Es gibt Unterkommandos von »zpool«und »zfs«, um die Attribute zu listen, die Konfiguration der Platten auszugeben oder die augenblickliche Auslastung einesZFS-Filesystems anzuzeigen. Defekte Platten lassen sich jederzeit – auch durch nicht baugleiche Modelle – ersetzen.In OpenSolaris sind schon einige der zukünftigen Features implementiert oder demnächst zu erwarten. Dazu gehören die Verschlüsselung der Daten (alle im Betriebssystem installierten Algorithmen), die auch vom User aus steuerbar ist. Für sensitive Environments wird sicheres Löschen implementiert. Weiterhin erhält OpenSolaris gerade Funktionen, die das Booten von einem ZFS-Filesystem ermöglichen .Darauf aufbauend wird im Projekt ZULU die Funktionalität "Live Upgrade für ZFS" implementiert (für UFS schon verfügbar), bei der der Anwender in einem Clone des Root-Filesystems eine neue Version des Betriebssystems (Patch, Upgradeoder Neuinstallation) ohne Produktionsunterbrechung installieren kann.
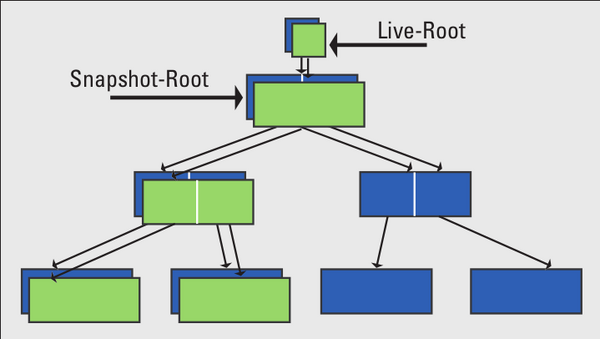 Abbildung 3: Snapshots sind bei ZFS eine Funktion des Filesystems. Es erzeugt sie – unabhängig von ihrer Größe – in einem Augenblick.
Abbildung 3: Snapshots sind bei ZFS eine Funktion des Filesystems. Es erzeugt sie – unabhängig von ihrer Größe – in einem Augenblick.
Ähnliche Artikel
-
ZFS unter FreeBSD – Datensicherheit auf neuen Wegen

-
Ein Btrfs-Praxis-Check und -Workshop

-
Infortrend baut EonNAS-Familie aus
Die Speicherlösungen der EonNAS-Familie von Infortrend erhalten leistungsstarken Zuwachs.
-
Experimenteller Windows-Support für Deduplication-Filesystem
Das von Opendedup entwickelte Deduplikations-Dateisystem SDFS wurde nun auf Windows portiert.
-
Linux-Dateisysteme administrieren (1)

Konfigurationsmanagement

Themen


