Was leisten Hybridfestplatten im Test?

Zwitterwesen

Die Frage, ob sich Hybridplatten lohnen, ist nicht so einfach zu beantworten, wie es auf den ersten Blick scheint. Würde man ihre Performance nämlich mit einem herkömmlichen synthetischen Benchmark messen, ließe sich in den meisten Fällen kein Unterschied zu einer gewöhnlichen Festplatte feststellen ( Abbildung 1 , erster Lauf). Das liegt an ihrer Arbeitsweise: Sie versuchen ihren relativ kleinen (und damit auch preiswerten) Flash-Speicher mit den Daten zu füllen, die am häufigsten verwendet werden. Für diese viel benutzten Daten müssen nachfolgende Zugriffe nicht mehr die vergleichsweise langsamen rotierenden Scheiben der Festplatte bemühen, denn die Daten kommen stattdessen aus dem integrierten MLC-Flash-Speichermodul.
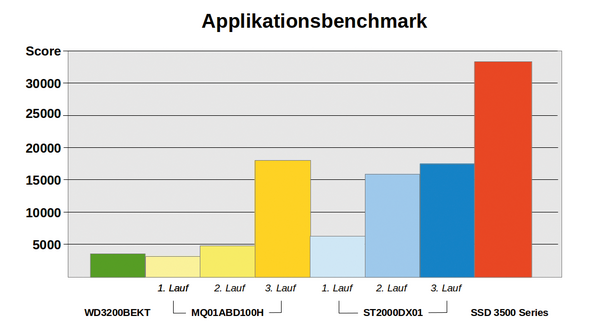 Abbildung 1: Applikations-Benchmarks belegen eindrucksvolle Performance-Gewinne für Hybridplatten – aber nur mit einem kleinen Trick: Man muss erst sorgfältig den Cache füttern.
Abbildung 1: Applikations-Benchmarks belegen eindrucksvolle Performance-Gewinne für Hybridplatten – aber nur mit einem kleinen Trick: Man muss erst sorgfältig den Cache füttern.
Häufig verwendete Daten kann der Algorithmus der Hybridplatte aber nur daran erkennen, dass sie in einem bestimmten Zeitraum mehrfach gelesen oder geschrieben werden. Ein Benchmark, der bei jedem Durchlauf neue Zufallsdaten erzeugt und sie anschließend einmalig liest, wird so immer nur von der herkömmlichen Festplatte bedient und hat nie eine Chance, seinen Lesestoff auf der schnellen SSD unterzubringen.
Manchmal ist es allerdings möglich, die Testdaten für eine mehrfache Verwendung in einem File zu speichern und wiederzuverwenden (unter anderem geht das bei
»fio«
). Auch praxisorientierte Applikations-Benchmarks können eher weiterhelfen: Ein Beispiel unter Windows ist etwa PCMark Vantage. Er testet in punkto Festplatten unter anderem Gaming und Streaming, das Hinzufügen von Musik und Bildern zu einer Medienbibliothek oder den Applikations- und Systemstart. Verschiedentlich publizierte Werte, die eine deutliche Überlegenheit der Hybridplatten ausweisen, kommen aber auch hier nur zustande, wenn man den Benchmark mehrfach nacheinander und ohne Unterbrechung durch andere Applikationen ausführt, nur so füllt sich der Cache mit den richtigen Daten (
Abbildung 1
).
Das ADMIN-Magazin hat sich zunächst einen eigenen kleinen Benchmark gebastelt, der so funktioniert: Ein Perl-Skript simuliert einen Lostopf, in dem 100 Lose liegen. Jedes Los enthält den Namen eines 100 MByte großen Testfiles. Insgesamt existieren 10 verschiedene, gleich große Testfiles (namens
»a«
bis
»j«
), die aber unterschiedlich oft auf den Losen vertreten sind: So ist zum Beispiel
»j«
nur zweimal,
»a«
viermal, aber
»d«
zehnmal und
»f«
24-mal vorhanden. Das Skript zieht nun nacheinander zufällig Los für Los, ohne sie zurückzulegen, und misst, wie lange es braucht, das auf dem Los notierte File zu lesen.
Dabei erkennt man eine klare Abhängigkeit der Lesegeschwindigkeit von der Lesehäufigkeit: Je öfter ein File gelesen wurde, je höher ist die durchschnittliche Transfergeschwindigkeit. Sieht man genauer auf die Werte, bemerkt man, dass der erste Zugriff immer langsam und alle weiteren schnell sind, was den Mittelwert um so stärker anhebt, je mehr schnelle Durchläufe folgen ( Abbildung 2 ).
 Abbildung 2: Abgesehen von der von Haus aus schnelleren SSD (hier nur an einem SATA-II-Controller) zeigen sowohl die normale Fetplatte (WD3200BEKT) wie die beiden Hybridmodelle von Seagate und Toshiba eine nahezu identische Abhängikeit der Transferrate von der Lesehäufigkeit.
Abbildung 2: Abgesehen von der von Haus aus schnelleren SSD (hier nur an einem SATA-II-Controller) zeigen sowohl die normale Fetplatte (WD3200BEKT) wie die beiden Hybridmodelle von Seagate und Toshiba eine nahezu identische Abhängikeit der Transferrate von der Lesehäufigkeit.
Der I/O-Stack
Die Sache hat nur einen Pferdefuß: Das passiert ganz unabhängig davon, ob man auf eine normale Festplatte oder eine Hybridplatte schaut! Woran liegt das? An der ein wenig komplizierteren Architektur des I/O-Stacks im Betriebssystem – in diesem Beispiel Linux.
Fordert eine Applikation wie der Benchmark Daten von einem Masssenspeicher an, durchläuft dieser Auftrag eine Abfolge verschiedener Schichten im Betriebssystem. Die oberste Ebene bildet der VFS-Layer. Er sorgt dafür, dass sich unterschiedliche Filesysteme gegenüber dem Userspace mit einer einheitlichen Schnittstelle präsentieren, sodass Applikationen immer mit denselben Systemcalls wie
»open()«
»read()«
und
»write()«
auf sie zugreifen können. Von den speziellen Fähigkeiten der verschiedenen Dateisysteme wird dabei abstrahiert, das Ergebnis ist ein virtueller gemeinsamer Nenner für alle (
Abbildung 3
).
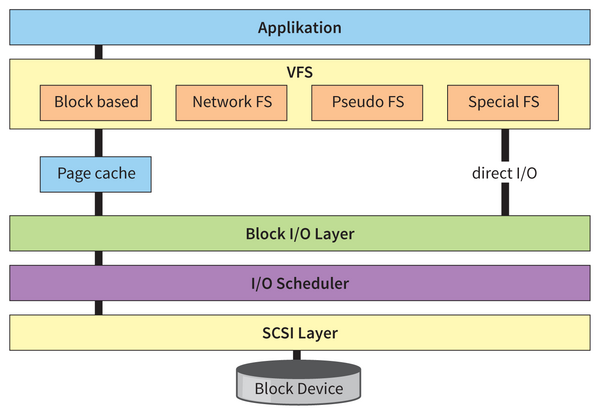 Abbildung 3: Der Linux-I/O-Stack: Verschiedene Layer bieten den jeweils darüberliegenden Schichten ein einheitliches, virtuelles Interface und verbergen so Komplexität und Eigenheiten der ihnen untergeordneten Welt.
Abbildung 3: Der Linux-I/O-Stack: Verschiedene Layer bieten den jeweils darüberliegenden Schichten ein einheitliches, virtuelles Interface und verbergen so Komplexität und Eigenheiten der ihnen untergeordneten Welt.
Die nächste Schicht des I/O-Stack stellt eine ganz ähnliche Abstraktion dar, nur geht es hier nicht um das Filesystem, sondern um sogenannte Blockdevices. Ein Blockdevice ist ein Massenspeicher, dessen Daten in Blöcken fester Größe (Sektoren) organisiert sind und der darauf einen wahlfreien Zugriff erlaubt (Random Access). Das Gegenstück wären Speicher, die nur einen sequentiellen Zugriff zulassen wie etwa Bandlaufwerke.
Obwohl Blockdevices technisch sehr verschieden realisiert sein können, je nachdem ob es sich zum Beispiel um Festplatten, CD-ROMs oder SSDs handelt, bietet der Block-I/O-Layer wieder ein einheitliches Interface für die darüberliegenden Schichten. Auf den Block-I/O-Layer folgt einer aus einer Auswahl verschiedener I/O-Scheduler, dessen Aufgabe es ist, die Zugriffe so zu sortieren und zusammenzufassen, dass möglichst wenig zeitraubende Kopfbewegungen der Festplatte nötig sind. Darauf folgt der eigentlich in drei Schichten gegliederte SCSI-Layer, der eine einheitliche Behandlung der verschiedenen Speichergeräte erlaubt, egal ob sie zum Beispiel über ein SAS- oder ein Fibre-Channel-Interface angeschlossen sind. Auf der untersten Ebene erscheint schließlich das physische Gerät.
Zwischen VFS- und Block-I/O-Layer liegt der sogenannte Page Cache, für den Linux fast den gesamten Hauptspeicher verwendet, den es nicht anderweitig braucht. Prinzipiell gelangen alle gelesenen Daten in diesen Page Cache (aus dem sie allerdings auch wieder herausfallen können, wenn sie längere Zeit nicht erneut gebraucht wurden). Das ist der Grund, weshalb wiederholte Lesevorgänge, die auf dieselben Daten zugreifen, aus dem Cache bedient werden und nicht von der physischen Festplatte. So erklärt sich, wieso auch ganz normale Festplatten oft gebrauchte Daten schneller zur Verfügung stellen: Sie kommen dann nämlich aus dem Cache (und damit aus dem RAM) und gar nicht von der Platte.
Die Daten können sogar einen noch kürzeren Weg nehmen, und zwar dann, wenn bereits die Applikation cachet. Das ist bei unserem Benchmark zum Beispiel der Fall, wenn wir in Perl den dortigen I/O-Layer
»perlio«
verwenden, der sich noch über dem I/O-Stack des Betriebssystems etabliert. Dann erreichen die wiederholen Leseanforderungen auf ihrem Weg abwärts durch den Stack unter Umständen noch nicht einmal den Kernel, sondern werden schon aus dem Perl-eigenen Cache bedient.
Eher Cache als Platte
Zugriffe, die gar nicht erst bei der Platte landen, können auch nicht durch die Platte beschleunigt werden – egal ob sie ein Flash-Modul hat oder nicht. Diesen Zusammenhang kann man sich auch noch auf andere Weise verdeutlichen: Zum Beispiel gibt das Kommando
»time«
, wenn man es mit dem Parameter
»-v«
oder dem Formatstring
»%F«
verwendet, eine Statistik aus, die unter anderem besagt, wie häufig eine von ihm überwachte Applikation (hier der Benchmark) einen sogenannten Major Page Fault ausgelöst hat, also eine Page anforderte, die nicht im Cache zu finden war und deshalb von der Platte gelesen werden musste.
Dazu löscht man zuerst den Cache mit:
# sync && echo "3" > /proc/sys/vm/drop_caches
und beginnt dann den ersten Durchlauf:
root@hercules:/Benchmark# /usr/bin/time -f "%F major page faults" ./readbench.pl... 15 major page faults
Startet man daraufhin unmittelbar im Anschluss einen zweiten Lauf, ist das Ergebnis:
Das heißt, beim ersten Mal wurden für das Lesen aller Testfiles bei leerem Cache noch 15 Zugriffe auf das physische Medium gebraucht. Dabei wurden maximal 199,41 MByte/s im Schnitt erreicht, und zwar bei dem File, das 24mal gelesen wurde. Das nur zweimal gelesene File kam nur auf 114 MByte/s im Schnitt. Beim zweiten Mal konnten alle Zugriffe aus dem Page Cache bedient werden, kein einziger physischer Plattenzugriff war nötig und die Transferrate betrug deshalb unabhängig von der Zugriffshäufigkeit bei allen Files rund 206,5 MByte/s, also rund das Doppelte der Rate des selten gelesenen Files.
Ähnliche Artikel





Konfigurationsmanagement

Themen


