Openstack als offenes Cloud-Computing-Framework

Schnittstelle

Nahezu unbeachtet von der Öffentlichkeit tobt seit einiger Zeit ein Kampf in der IT, der ausnahmsweise nichts mit mobilen Betriebssystemen und deren Hardware-Inkarnationen zu tun hat. Und doch sind die Protagonisten keine Unbekannten. Die Rede ist vom Kampf um die künftige Vorherrschaft beim so genannten Cloud Computing. Jenem Buzzword, das jetzt schon seit einiger Zeit die Phantasien von Analysten [1] , Beratungsunternehmen [2] , Hardwareherstellern, Rechenzentrumsbetreibern und nicht zuletzt CIOs und CTOs multinationaler Firmen beflügelt.
Zugrunde liegt der anhaltenden Euphorie der Traum von der bedarfsgerechten Rechen- und Speicherkapazität auf Knopfdruck. Was Amazon mit der Elastic Cloud (EC2) eingeführt hat, um brachliegende Serverkapazität außerhalb der Lastspitzen des eigenen elektronischen Einkaufsladens zu Weihnachten und Thanksgiving zu monetarisieren, ist längst von vielen Mitbewerbern kopiert worden. Immer stärker engagieren sich in diesem Segment auch klassische Hoster.
Bei all diesen Angeboten spricht man landläufig auch von der so genannten Public Cloud, einer Rechner- und Speicherwolke, die jedem Inhaber einer Kreditkarte verbrauchsabhängige Dienste über das Internet anbietet. Neben vielen Startups, die derartige Dienste nutzen, um das eigene Infrastruktur-Investment so klein wie möglich zu halten, interessieren sich auch immer mehr klassische Firmen und vor allen Dingen große Finanzdienstleister für diese Art verbrauchsbezogener Nutzungsmodelle.
Deren Sicherheitsanforderungen ließen bald den Wunsch nach einer so genannten Private-Cloud-Technologie aufkommen. In der Handhabung sollen diese Inhouse-Lösungen ebenso einfach sein wie die von Amazon angebotenen Dienste und idealerweise über gleiche Schnittstellen kommunizieren können. Diese Schnittstellengleichheit würde die Möglichkeit eröffnen, so genannte Inter-Clouds zu realisieren, die sowohl bei Überlastung der eigenen privaten Cloud (Cloud Bursting) als auch bei der Lastverteilung (Cloud Balancing) hilfreich sein könnten.
2007 betrat erstmals das als Forschungsprojekt des Departments of Computer Science der Universität von Kalifornien in Santa Barbara initiierte Eucalyptus die Bühne, das ein AWS-kompatibles API aufweist. Angeboten wird Eucalyptus in einer kommerziellen Enterprise- und in einer Community-Edition.
Dies von MySQL bekannte Geschäftsmodell ist für Regierungs- und regierungsnahe Organisationen wie die NASA ein Problem. Eine nicht wirklich offene Infrastruktur kann die Investitionen der öffentlichen Hand nicht ausreichend schützen. Um diese Infrastruktur geht es beim Cloud Computing nun mal, die IaaS-Schicht (Infrastrucure as a Service) der Cloud, die verschiedene Hardwarekomponenten virtualisiert und über ein einheitliches API zugänglich macht.
Die im Juli 2010 vom amerikanischen Hoster Rackspace, der NASA und weiteren Partnern initiierte Openstack-Initiative, soll genau diese Schicht zur Verfügung stellen und einen quelloffenen Industriestandard schaffen, der sich an die Amazon-Schnittstelle anlehnt. Seit dem 22. Oktober ist die erste Software-Release "Austin" verfügbar [3] , die eine Abstraktion auf einzelne Rechnerknoten (Openstack Compute) und die Nutzung einer verteilten Objekt-Datenbank (Openstack Storage) ermöglicht.
Intern werden beide Komponenten noch als Nova und Swift geführt, die ihren Ursprung in Produkten von Rackspace haben. Die NASA steuerte mit Nebula [4] die eigene quelloffene Hybrid-Cloud-Plattform zum Openstack-Framework bei und verließ gleichzeitig das Eucalyptus-Projekt [5] . Auch die Ubuntu Foundation ließ kürzlich vernehmen, dass sie den Weg von Eucalyptus zu Openstack einschlagen will [6] .
Anatomie von Openstack
Cloud-Computing-Dienste wie Amazons EC2 und S3 nutzen bestimmte Entitäten für die Verwaltung von System- und Speicherkomponenten. Um eine Schnittstellenkompatibilität zu Amazons Webservices zu erzielen, sind demnach ähnliche Entitäten nötig. Wer Dienste des Amazon-Webservice kennt, den wird die Existenz folgender Entitäten in Openstack nicht überraschen:
- Nutzer und Projekte: Ein Nutzer kann mehrere Projekte haben. Jeder Nutzer verfügt über ein Schlüsselpaar (private, public) für den Zugriff auf ein oder mehrere Projekte. Jedes Projekt verfügt über bestimmte Kontingente an Prozessorkernen, Festplatten- und Hauptspeicher und so weiter.
- Jedem Projekt sind virtuelle Maschinen zugeordnet, die sich als Images starten lassen. Zur Kommunikation mit dem Hypervisor (KVM, Xen, Hyper-V, Qemu) dient ein API.
- Instanzen sind virtuelle Maschinen, die innerhalb der Cloud laufen.
- Volumes sind Block-basierte Speichermedien.
- Local Storage bezeichnet ein lokales Speichermedium.
- Die Nutzung des API wird über Role Based Access Control (RBAC) geregelt. Rollen können dabei zum Beispiel sein: System- oder Netzwerk-Administrator, Projektmanager, Basisnutzer und so weiter [7] .
Aus technischer Sicht besteht das Openstack-Framework aus folgenden Komponenten (siehe Abbildung 1 ).
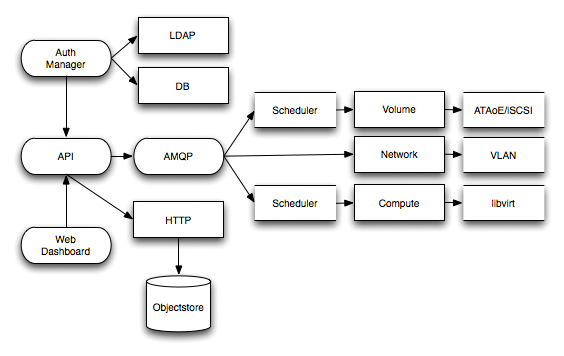 Abbildung 1: Openstack umfasst eine Reihe von Komponenten, darunter den Message Broker AMQP.
Abbildung 1: Openstack umfasst eine Reihe von Komponenten, darunter den Message Broker AMQP.
Alle Informationen und Einstellungen der Cloud sind in der Datenbank gespeichert. Über das REST-API lassen sich alle Cloud-Komponenten ansprechen. In der Regel wird man dies nicht über die Kommandozeile tun, wie in der aktuellen Release von Openstack, sondern eher über Fat Clients oder Webanwendungen (Web Dashboard). Der Auth-Manager regelt den Rollen-basierten Zugriff auf die Funktionalität des API, sodass nicht alle Nutzer einzelne Instanzen hoch- und runterfahren können. Der Scheduler verteilt Zugriffe und Rechenzeit auf die einzelnen virtuellen Komponenten.
In der aktuellen Release sind noch nicht alle Komponenten von Openstack voll ausgebaut. So ermöglicht der Object Store aktuell nur die Speicherung von Objekten, die kleiner als 5 GByte sind. Auch Rollen-basierte Quotas fehlen noch.
Einfacher Knoten
Bei Licht betrachtet und nach Studium der aktuellen, aber vorläufigen Dokumentation der ersten Openstack-Release, finden sich alte Bekannte und noch nicht allzu viel Neues. Nova kümmert sich um den Openstack-Computing-Teil (siehe Abbildung 1 ). Um mit Openstack eigene virtuelle Maschinen erzeugen und verwalten zu können, bedarf es nicht viel mehr als eines aktuellen Linux-Systems. Vorzugsweise Debian, Ubuntu oder Centos in einer aktuellen Release, da dort die nötigen Pakete über die Installations-Manager verfügbar sind. Folgende Schritte sind für einen ersten Test nötig:
1. Einrichten eines Openstack-Administrators.
2. Erzeugung eines Openstack-Projekts.
3. Generierung geeigneter privater und öffentlicher Schlüssel.
4. Anlegen eines geeigneten Image für den Betrieb von virtueller Maschinen-Instanzen.
5. Hochladen der Images und Start der Instanz(en).
Im folgenden Installationsbeispiel soll Ubuntu als Testsystem dienen. Openstack Compute baut auf dem Messaging-Server Rabbit-MQ [8] und der NoSQL-Datenbank Redis [9] auf. Zusammen mit Nova lassen sich diese wie folgt installieren:
apt-get install rabbitmq-server redis-server apt-get install python-nova apt-get install nova-api nova-objectstore nova-compute nova-scheduler nova-network
Schließlich wird noch die Euca2ool-Suite [10] benötigt, die ein Kommandozeilen-Tool für die Kommunikation mit dem REST-basierten Webservice von Openstack ermöglicht. Im Funktionsumfang den Amazon-Kommandozeilen-Tools sehr ähnlich, lassen sich damit die Images, Instanzen und Volumes managen:
apt-get install euca2ools unzip
Sind alle Tools beisammen, ist mit Hilfe des Nova-Manage-Tools ein geeigneter Nutzer als Administrator anzulegen:
nova-manage user admin rwartala
Dabei werden sowohl ein Zugriffs- als auch ein Sicherheitsschlüssel erzeugt:
export EC2_ACCESS_KEY=713211a4-7a15-470f-ae54-346b52e30a0e export EC2_SECRET_KEY=244de6a1-8aa3-4e12-9521-03ac756abbdf
Der nächste Schritt besteht im Anlegen eines neuen Nova-Projekts (
»OSTEST«
steht hier für Openstack-Test). Der Befehl
nova-manage project create OSTEST rwartala
erzeugt danach das Projekt, die nötigen Zertifikate sowie die privaten und öffentlichen Schlüssel ( Listing 1 ).
Listing 1
Schlüssel erzeugen
Mit
»unzip nova.zip«
packt der Nutzer diese Daten in das Homeverzeichnis aus. Was jetzt noch fehlt, ist ein geeignetes Image, das instanziiert werden kann. Rackspace bietet ein vorgefertigtes Test-Image für den Betrieb einer virtuellen Maschine an. Unter
wget http://c2477062.cdn.cloudfiles.rackspacecloud.com/images.tgz
lässt es sich herunterladen und mit
tar xvzf images.tgz
auspacken. Um daraus für Openstack Compute ein ausführbares Image zu erzeugen, wird die Euca2ool-Suite bemüht. Mit
euca-bundle-image -i images/aki-lucid/image -p kernel --kernel true Checking image Tarring image Encrypting image Splitting image... Part: kernel.part.0 Generating manifest /tmp/kernel.manifest.xml
und
euca-bundle-image -i images/ari-lucid/image -p ramdisk --ramdisk true
werden ein entsprechendes Kernel-Ramdisk-Paar aus dem Image und ein entsprechendes Image-Manifest erzeugt. Dieses beschreibt das Image und enthält darüber hinaus die erzeugten Zertifikate. Beide Images können dann in die Cloud geladen werden, und zwar mit Hilfe von:
euca-upload-bundle -m /tmp/kernel.manifest.xml -b mybucket euca-upload-bundle -m /tmp/ramdisk.manifest.xml-b mybucket
Was jetzt noch fehlt, sind entsprechende Schlüssel, um Zugang zur Instanz über SSH zu bekommen. Mit
euca-add-keypair rwartala_key > rwartala_key.priv chmod 600 rwartala_key.priv
werden die Schlüssel erzeugt. Dann lässt sich die Instanz mit Hilfe von
euca-run-instances ami-g06qbntt --kernelami-fcbj2non --ramdisk ami-orukptrc -krwartala_key
starten. Läuft die VM, kann man sich mit Hilfe des zuvor generierten SSH-Schlüssels und
ssh -i rwartala_key.priv root@10.0.0.3
auf die Maschine verbinden.
Ähnliche Artikel
-
OpenStack "Diablo" mit Management-GUI
Im neuen Release mit dem Namen "Diablo" integriert das Cloud-Computing-Framework OpenStack eine grafische Oberfläche fürs Management.
-
OpenStack-Workshop, Teil 1: Einführung in OpenStack

-
OpenStack: Der Shooting Star unter den Clouds

-
OpenStack 2012.1 veröffentlicht
Das Cloud-Computing-Framework OpenStack bringt Version 2012.1 und konsolidiert dabei einige Altlasten. Gerüchte über den Beitritt von Red Hat und IBM zum OpenStack-Projekt.
-
OpenStack entfernt Hyper-V-Support
In der Entwicklerversion von OpenStack gibt es ab sofort keine Unterstützung mehr für Microsofts Hypervisor.
Konfigurationsmanagement

Themen


