Linux-RAID optimal konfigurieren

Eingestellt

Unter Linux ein RAID-System
zu konfigurieren, ist heutzutage keine große Sache mehr. Ein Aufruf von
»mdadm«
und
»pvcreate«
genügt, und schon steht ein RAID-5- oder RAID-10-System Gewehr bei Fuß. Tatsächlich ist die Einrichtung eines RAID so einfach, dass sich viele Administratoren einfach durch die Kommandozeile oder GUI hangeln und keine großen Gedanken auf die vielen möglichen Einstellungen verschwenden, die die Leistung beeinflussen.
RAID-5
Dieser Artikel geht davon aus, dass Sie mit den Konzepten und der Konfiguration von RAID-Systemen vertraut sind. Fehlt Ihnen dieses Wissen, finden Sie einige Dokumentation dazu online unter [1] . Das Redundant Array of Inexpensive Disks (RAID) steht für eine Sammlung von Techniken, um fehlertolerante Speichersysteme aufzubauen. Der Begriff stammt aus dem Artikel "A Case for Redundant Arrays of Inexpensive Disks" von David Patterson, Garth Gibson und Randy Katz [2] .
Fehlertolerante Storage-Systeme sind ein Mittel, Datensicherheit zu garantieren, wenn beispielsweise eine Festplatte versagt. Der einfachste Weg dazu führt über die Duplizierung der Daten auf zwei Festplatten. Das entspricht mehr oder weniger der bekannten Mirroring-Methode, die als RAID-1 bekannt ist.
Auch wenn Disk-Mirroring sicher einige der Probleme löst, ist es weder besonders elegant noch besonders effektiv. 50 Prozent des verfügbaren Speicherplatzes werden darauf verwendet, redundante Informationen zu speichern. Der ursprüngliche Artikel der RAID-Autoren untersucht alternative Wege, um auf effizientere Art Fehlertoleranz zu gewährleisten. Ein in der IT-Welt weitverbreiteter Ansatz ist das Disk-Striping mit Parity, das auch als RAID-5 bekannt ist.
RAID-5 erfordert drei oder mehr Festplatten. In einem RAID-Array mit N Festplatten landen die Daten auf N-1 Platten, während die verbleibende Disk die Parity-Informationen speichert, die zur Wiederherstellung der Originaldaten dient, wenn eine Datenplatte ausfällt. Die Anzahl von Festplatten, die zur Speicherung redundanter Daten abgestellt sind, ist deshalb 1/N. Je mehr Festplatten also im RAID-Verbund stecken, desto geringer ist die relative Verschwendung von Plattenplatz.
Täuschend
Bei RAID-Systemen garantieren die Default-Einstellungen nicht unbedingt optimale Performance. Dieser Artikel zeigt, dass die Abstimmung der Parameter von Dateisystem und RAID einen Unterschied von bis zu 15 Prozent ausmachen.
Ein Dateisystem ist eine nur scheinbar einfache Sache. Auf den ersten Blick scheint nicht viel dahinterzustecken. Eine Datei abspeichern und später wieder lesen, was kann daran schon schwierig sein? Wie so oft steckt der Teufel im Detail. Schon das Speichern einer kleinen Datei ist ein relativ komplexer Vorgang, denn beispielsweise sind auf dem Weg bis zur Festplatte einige Caches im Spiel: Der Kernel hat einen eigenen Cache, der Disk-Controller möglicherweise auch, und schließlich besitzt auch noch die Festplatten-Hardware einen kleinen Zwischenspeicher. Wenn ein Dateisystem also sicherstellen will, dass die Daten wirklich auf die Platte geschrieben wurden, wird daraus ein recht komplexer Vorgang, der auch Zeit kostet.
Wenn Sie mit vier Festplatten ein RAID-5 (siehe Kasten) anlegen, schreibt der Linux-Kernel drei Blocks mit Nutzdaten auf drei Platten und legt die Parity-Informationen der drei Blocks auf der vierten Platte ab. Auf diese Art lassen sich die Daten wiederherstellen, selbst wenn eine der vier Platten kaputtgeht. Weil man bei Dateisystemen häufig von Blocks spricht, bezeichnen RAID-Experten die drei Datenblocks meist als "Chunks", um Verwirrung zu vermeiden.
Bei vier Festplatten gibt es drei Daten-Chunks und ein Parity-Chunk. Die Stripe-Größe ist also drei Chunks und die Parity-Stripe-Größe ein Chunk. Die Stripe-Größe ist sehr wichtig, denn ein Dateisystem sollte versuchen, alle Chunks eines Stripe gleichzeitig zu schreiben, damit der Parity-Chunk aus den drei Chunks im Hauptspeicher berechnet und dann auf die Platte geschrieben werden kann. Der zu schreibende Chunk soll im Folgenden Chunk-X heißen, der Parity-Chunk Chunk-P. Eine Möglichkeit ist es, die anderen Daten-Chunks des Stripe zu lesen, Chunk-X zu schreiben, Chunk-P neu zu berechnen und dann zu schreiben. Alternativ kann das RAID Chunk-P und den alten Chunk-X lesen und dann Chunk-P so ändern, dass er zum alten Chunk-X passt.
Wie man sieht, können sich RAID-Algorithmen ziemlich verkomplizieren, wenn man nicht nur zusammenhängende Blocks nacheinander auf das System schreibt. Noch komplexer wird es, wenn man das Dateisystem miteinbezieht, wie etwa die Metadaten, die für jede Datei und jedes Verzeichnis existieren. Wenn der Anwender zum Beispiel eine Datei anlegt oder löscht, ändern sich die Metadaten, das heißt einige wenige Daten müssen auf die Festplatte geschrieben werden.
Abhängig vom Aufbau eines Dateisystems muss es auch beim Lesen eines Verzeichnisses viele kleine Datensegmente von der Platte lesen. Wenn das Dateisystem über Chunk- und Stripe-Größe Bescheid weiß, kann es die Metadaten in Chunks ablegen, was wiederum den Zugriff vereinfacht und beschleunigt.
Am Anfang der optimalen Abstimmung der Parameter von Dateisystem und RAID steht, die Stripe- und Chunk-Größe beim Anlegen des Dateisystems richtig festzulegen. Wer XFS verwendet und das Dateisystem direkt auf dem RAID anlegt, hat es leicht, denn
»mkfs.xfs«
wählt automatisch die richtigen Werte. Wenn allerdings der Logical Volume Manager (LVM) ein RAID verwendet und man ein XFS-System auf einem Logischen LVM-Volume anlegt, optimiert
»mkfs.xfs«
die Parameter fürs Anlegen des Dateisystems nicht.
Zur Tat
Der Befehl in
Listing 1
legt ein RAID-System an. Die Default-Chunk-Größe ist dabei 64 KByte in einem Verbund von vier Festplatten. Wenn man die Festplatten/Partitions-IDs in
»/dev/disk/by-id«
verwendet, läuft man weniger Gefahr, aus Versehen die falsche Festplatte einzubinden.
Listing 1
RAID anlegen
Wir haben für Ext3 und XFS jeweils zwei Tests durchgeführt: einen mit einem Dateisystem, das mit
»mkfs«
und Standardeinstellungen angelegt wurde, den anderen mit auf das RAID abgestimmten Parametern. Es werden also vier Dateisysteme verglichen, nämlich Ext3-Standard (Ext3), Ext3-Ausgerichtet (Ext3-Aligned), XFS-Standard (XFS) und XFS-Ausgerichtet (XFS-Aligned). Die einzige Zusatzoption beim Standard-XFS ist
»lazy-count=1«
, das bei hoher Last den konkurrierenden Zugriff auf den Superblock verbessert und als Standard-Option empfehlenswert ist. Mehr Informationen zur Test-Hardware finden Sie im
Kasten "Details"
.
Details
Dieser Artikel konzentriert sich auf die Ext3- und XFS-Dateisysteme. Beim Test kam ein RAID-5 mit vier 500-GByte-Festplatten zum Einsatz. Im Einzelnen waren es drei Samsung HD501LJ mit 500 GByte und eine Samsung HD642JJ mit 640 GByte. Ein Vorteil von Linux besteht darin, dass man sein RAID-System auch über Platten unterschiedlicher Größe verteilen kann, solange die Partitionen gleich groß sind. Das im Test eingesetzte RAID belegte 343 525 896 Blocks auf jeder Festplatte, was in einem Dateisystem von etwas weniger als 1 TByte resultiert. Das verwendete Mainboard war ein Gigabyte P35.
Der Aufruf von
»mkfs«
ist in
Listing 2
zu sehen. Um die Funktion der Parameter zu verdeutlichen, sind die Werte in aussagekräftigen Variablen gespeichert. Der Stride-Parameter teilt Ext3 mit, wie groß jeder RAID-Chunk in 4 KByte großen Disk-Blocks ist. Der Stripe-Width-Parameter legt fest, wie groß ein einzelnes Stripe in Daten-Blocks ist. Effektiv entspricht es bei der RAID-5-Konfiguration mit vier Platten dreimal dem Wert von Stride.
Listing 2
Ext3 optimiert
Den entsprechenden Aufruf für XFS zeigt das folgende Listing. Die Parameter
»sunit«
und
»swidth«
ähneln
»stride«
und
»stripe-width«
bei Ext3, allerdings werden die Werte in 512-Byte-Blocks angegeben:
mkfs.xfs -f -l lazy-count=1 -d sunit=$(($CHUNK_SZ_KB*2)),swidth=$(($CHUNK_SZ_KB*2*$NON_PARITY_DRIVE_COUNT)) $RAID_DEVICE
Für die Benchmarks kamen Bonnie++ und Iozone zum Einsatz. Bonnie++ ist als Dateisystem-Benchmark recht bekannt und testet zeichen- sowie blockweises Lesen und Schreiben, Rewrite, Seek und Metadatei-Operationen wie Anlegen und Löschen. Iozone führt eine ganze Reihe an Lese- und Schreibtests mit unterschiedlichen Größen durch. Das Ergebnis lässt sich abhängig von den Größen in einem dreidimensionalen Graphen darstellen.
Abbildung 1
zeigt das erste Bonnie-Ergebnis beim Lesen und Schreiben. Weil
»mkfs.xfs«
wie erwähnt die RAID-Konfiguration erkennt und die Parameter anpasst, unterscheiden sich die Werte von XFS und XFS-Aligned nicht, deshalb ist im Diagramm nur XFS zu sehen. Bei Ext3 ist bereits ein sehr großer Unterschied zwischen Standard- und optimiertem Dateisystem zu erkennen. Auf eine um 10 MByte/s verbesserte Schreibperformance wird man nur ungern verzichten wollen!
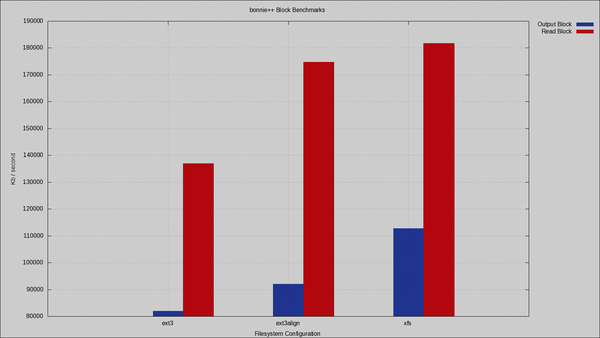 Abbildung 1: Bonnie-Benchmark-Ergebnisse für Lesen und Schreiben. Die Performances zwischen Standard-Ext3 und für RAID optimiertem Ext3 sind bereits enorm.
Abbildung 1: Bonnie-Benchmark-Ergebnisse für Lesen und Schreiben. Die Performances zwischen Standard-Ext3 und für RAID optimiertem Ext3 sind bereits enorm.
Die von Bonnie gemessene Rewrite-Leistung ist ein aussagekräftiger Wert, wenn man beispielsweise auf einem Dateisystem eine Datenbank betreiben möchte. Zwar ersetzen auch typische Desktop-Anwendungen wie das Speichern einer Datei, eine komplette Datei in einer Operation, aber Datenbanken überschreiben häufig Daten an ihrem altem Speicherort.
Die Rewrite-Leistung ist in Abbildung 2 zu sehen. Auch wenn zeichenbasierte Ein-/Ausgabe weniger wichtig ist als blockbasierte, beläuft sich der Gewinn bei einem optimal ausgerichteten Ext3-Dateisystem auf einen Unterschied von 2 MByte/s, also etwa 6 Prozent mehr Leistung.
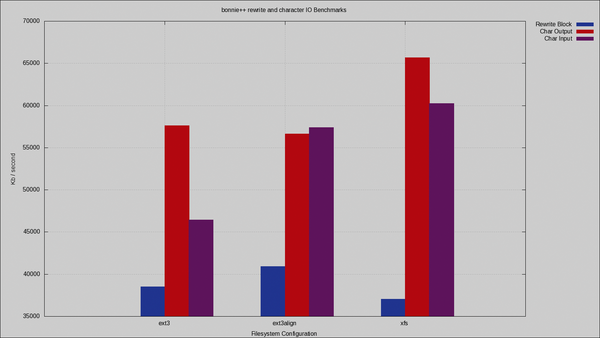 Abbildung 2: Bonnie-Ergebnisse für Rewrite und zeichenweises Lesen und Schreiben. Auch hier sind bei korrekter Ausrichtung des Ext3-Systems Performance-Gewinne zu verzeichnen.
Abbildung 2: Bonnie-Ergebnisse für Rewrite und zeichenweises Lesen und Schreiben. Auch hier sind bei korrekter Ausrichtung des Ext3-Systems Performance-Gewinne zu verzeichnen.
Die Iozone-Ergebnisse für Ext3 und Ext3-Aligned sind sehr ähnlich, zeigen aber einige Anomalien, auf die es wert ist hinzuweisen. Die Lese-Performance ist in den Abbildungen 3 und 4 zu sehen. Man sieht, dass Ext3-Aligned beim Lesen kleiner Datenmengen schneller ist als Ext3. Eigenartigerweise fällt die Performance aber mit Ext3-Aligned bei Dateien größer 16 MByte ab.
 Abbildung 4: Iozone-Ergebnisse fürs Lesen mit dem ausgerichteten Ext3. Bemerkenswert ist die Mulde um eine Dateigröße von 16 386 Bytes herum.
Abbildung 4: Iozone-Ergebnisse fürs Lesen mit dem ausgerichteten Ext3. Bemerkenswert ist die Mulde um eine Dateigröße von 16 386 Bytes herum.
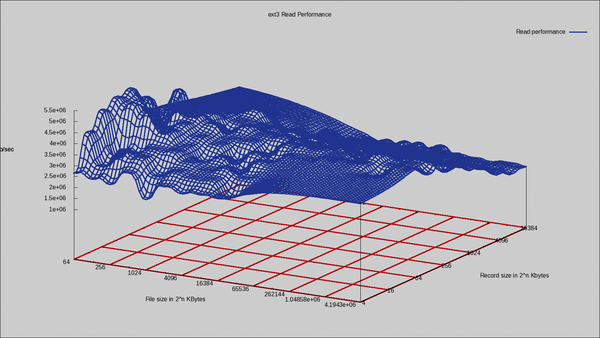 Abbildung 3: Iozone-Ergebnisse fürs Lesen mit Ext3.
Abbildung 3: Iozone-Ergebnisse fürs Lesen mit Ext3.
Ähnliche Artikel





Konfigurationsmanagement

Themen


