Was wäre wenn? Mathematische Lastsimulation mit Perl

Berechenbare Performance

Drei aufeinanderfolgende Prozesse machen das Performance-Management aus: Monitoring, Analyse und Modellierung ( Abbildung 1 ). Das Monitoring sammelt die Daten, die Analyse erkennt in ihnen wiederkehrende Muster, und Modelle sagen auf dieser Grundlage künftige Ereignisse wie etwa Ressourcen-Engpässe voraus. PDQ (Pretty Damn Quick) ist ein Queueing-Analysetool in Gestalt eines Perl-Moduls, das dazu dient, solche Vorhersagen zu ermöglichen.
 Abbildung 1: Die drei Phasen des Performance-Managements – Monitoring, Analyse und Modeling – sind eng miteinander verknüpft.
Abbildung 1: Die drei Phasen des Performance-Managements – Monitoring, Analyse und Modeling – sind eng miteinander verknüpft.
Einführung
Eine passende Monitoring-Lösung ist ausgewählt, installiert und konfiguriert – jetzt läuft sie im Produktivbetrieb. Das aber ist nicht etwa das Ende, sondern ein neuer Anfang und Ausgangspunkt. Eine wesentliche Voraussetzung besteht zunächst darin, die Leistung zu messen und Performancedaten zu sammeln. Ohne Daten lassen sich die Leistungseigenschaften der zu überwachenden Systeme und Applikationen nicht quantifizieren. Dies ist die Aufgabe der Monitoring-Phase.
Das Monitoring auf sich alleine gestellt ist aber so sinnlos wie das bloße Starren auf die tänzelnden Zeiger im Cockpit eines Autos. Um die Lage richtig einschätzen zu können, muss man außerdem durch die Windschutzscheibe schauen, um andere Fahrzeuge in der Nähe zu erkennen. Mit anderen Worten: Wer sich ausschließlich auf das Monitoring verlässt, der erhält lediglich einen kurzfristigen Eindruck vom Systemverhalten ( Abbildung 2 ).
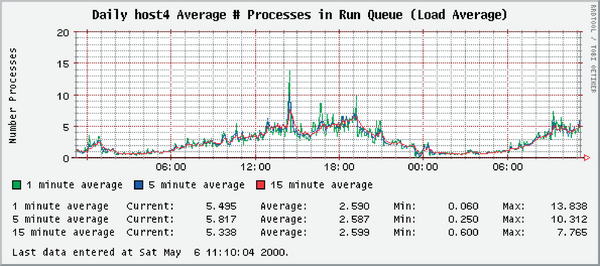 Abbildung 2: Ein 24-Stunden-Protokoll der durchschnittlichen Auslastung, das die Orca-Tools für Linux
Abbildung 2: Ein 24-Stunden-Protokoll der durchschnittlichen Auslastung, das die Orca-Tools für Linux
Der Blick aus dem Fenster eröffnet dagegen die Fernsicht. Doch je weiter weg ein Beobachtungsobjekt ist, desto schwieriger lässt sich mit Bestimmtheit sagen, wie wichtig es einmal werden könnte. Um aus Beobachtungswerten später Prognosen ableiten zu können, muss man die Leistungsdaten aus der Überwachungsphase mit Zeitstempeln versehen und sie in einer Datenbank speichern. Darauf baut die nächste Phase, die Performance-Analyse auf, die den Admin in die Lage versetzt, die gewonnenen Daten aus einer historischen Perspektive zu betrachten, um in ihnen Muster und Trends zu erkennen.
Auf das Performance-Modeling baut anschließend die Leistungsvorhersage auf, die Phase des Performance-Managements, die einen in die Lage versetzt, aus dem Fenster und in die Zukunft zu blicken. Dafür benötigt man zusätzliche Tools, welche die Daten so aufbereiten, dass sie in Leistungsmodelle eingehen können. Dazu ist etwas Mathematik nötig.
Statistik versus Warteschlange
Es gibt zwei klassische Ansätze für das Performance-Modeling: die statistische Datenanalyse und das Warteschlangenmodell. Beide Methoden schließen sich gegenseitig nicht aus. Die Unterschiede lassen sich so beschreiben: Die statistische Datenanalyse, eine Aufgabe, die jede Buchhaltung kennt, basiert auf der Berechnung von Trends in den Rohdaten. Statistiker entwickelten viele schlaue Techniken und Tools im Laufe der Jahre, und ein Großteil dieser Intelligenz ist in Form von Open-Source-Paketen für das statistische Modeling erhältlich. Ein Beispiel für ein mächtiges freies Tool dieser Art ist R [2] .
Dieser Ansatz ist jedoch dadurch begrenzt, dass er sich ausschließlich auf bestehende Daten stützt. Wenn die Zukunft jedoch (angenehme oder unangenehme) Überraschungen bereithält, die sich aus den aktuellen Daten nicht erkennen lassen, leidet die Zuverlässigkeit der Vorhersage. Und wer sich etwa mit der Börse beschäftigt, der weiß, dass dies ständig geschieht.
Warteschlangenmodelle sind von diesen Beschränkungen nicht betroffen. Das liegt daran, dass sie per Definition mithilfe des Queueing-Paradigmas vom realen System abstrahieren. Allerdings verursacht diese Vorgehensweise einen größeren Aufwand als die Trendanalyse in den Rohdaten, und sie setzt voraus, dass die Queueing-Abstraktion das echte System genau nachbildet. Je stärker das Modell von der Wirklichkeit abweicht, desto höher ist die Ungenauigkeit der Vorhersagen. Wie dieser Artikel demonstriert, ist es aber bei Weitem nicht so schwer, Warteschlangenmodelle zu entwickeln als man vermuten würde. In Wirklichkeit ist es oft erstaunlich einfach.
Ähnliche Artikel





Konfigurationsmanagement

Themen


