Systeme: PostgreSQL 9.4
Moderne Datenbank

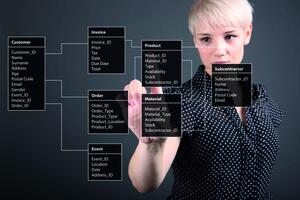
Schon länger verfügt PostgreSQL über einen JSON-Datentyp, der das Speichern von JSON-Dokumenten in relationalen Datenbeständen vereinfacht. Er ist geeignet, um JSON-Dokumente als ganze Entität zu betrachten und nicht auf ein relationales Datenmodell abzubilden. Dies ermöglicht die Datenhaltung innerhalb einer Datenbank, mit allen Vorteilen, die PostgreSQL für den Anwender bereithält, wie kompromisslose Transaktionssicherheit, hervorragende Erweiterbarkeit, aber auch Skalierbarkeit in derselben Softwarekomponente.
Die ursprüngliche Implementierung des JSON-Datentyps wies jedoch einen großen Nachteil auf: JSON-Dokumente wurden in der Datenbank als Zeichenkette gespeichert und erforderten bei jedem Zugriff das Parsen und Analysieren des Dokuments. Auch ist es sehr aufwendig, bei einer derartigen Repräsentation eines Dokuments auf Bestandteile eines Dokuments zuzugreifen, geschweige denn sie effizient zu indizieren.
Mit JSONB hat PostgreSQL 9.4 nun einen Datentyp eingeführt, der JSON-Dokumente als strukturierten, binären Datentypen behandelt und speichert. Dies erlaubt effizienten Zugriff auf JSON-Dokumente und sogar die Implementierung
...Der komplette Artikel ist nur für Abonnenten des ADMIN Archiv-Abos verfügbar.
Ähnliche Artikel
-
Hochverfügbarkeit und Replikation für PostgreSQL

-
PostgreSQL 10

-
Überblick zu PostgreSQL 14.4

-
Neuerungen in PostgreSQL 12

-
PostgreSQL 9.4 veröffentlicht

Die lange erwartete PostgreSQL-Version mit besserem JSON-Support und neuen Replikationsmechanismen wurde jetzt freigegeben.
Konfigurationsmanagement

Themen


