
Konfiguration des Galera Clusters
Der Galera Cluster wird, wie man es von MySQL gewohnt ist, in der Datei
»/etc/my.cnf«
konfiguriert. Die Parameter, die Galera betreffen, beginnen mit
»wsrep_«
. Zusätzlich müssen auch noch einige MySQL-Parameter berücksichtigt werden. Folgende Parameter sind in der
»my.cnf«
in die Sektion
»[mysqld]«
einzupflegen (
Listing 3
).
Listing 3
MySQL-Parameter
Der Galera Cluster verlangt zwingend das neue, in MySQL 5.1 hinzugekommene, Row Bases Replication Format (RBR). Und wie bereits weiter oben erwähnt, läuft Galera Cluster zurzeit ausschließlich mit InnoDB-Tabellen. Da der Query Cache lokal pro Knoten arbeitet und sich die Caches nicht über ihre Inhalte austauschen, muss er aus Daten-Konsistenz-Gründen ausgeschaltet werden.
Die minimale Galera Cluster Konfiguration besteht aus folgenden Parametern, die ebenfalls in die
»[mysqld]«
-Sektion gehören: Der Parameter
»wsrep_provider«
teilt MySQL mit, wo es das Galera Plugin findet.
»wsrep_cluster_name«
benennt dagegen einen Cluster im Netzwerk eindeutig. Dieser Parameter dient vor allem dazu, dass sich ein wildfremder Knoten beim Starten nicht fälschlicherweise in den Cluster verirrt. Er muss auf allen Knoten unseres Clusters gleich sein. Der Parameter
»wsrep_node_name«
gibt den Knoten eindeutige, sprechende Namen. Dieser Parameter muss auf allen drei Knoten unterschiedlich sein. Der Parameter
»wsrep_cluster_address«
teilt dem Knoten mit, wo er einen seiner Kollegen vorfindet, um mit dessen Hilfe in den Cluster-Verbund aufgenommen zu werden. Beim Starten des ersten Knotens ist natürlich noch kein weiterer Knoten verfügbar, daher lautet der Eintrag
»gcomm://«
. Alle anderen Knoten können beim Starten auf diesen ersten Knoten verweisen. Wird jedoch der erste Knoten neu gestartet, würde er mit
»gcomm://«
versuchen, einen neuen Cluster zu bilden. Daher muss nach dem initialen Starten dieses Knotens
»wsrep_cluster_address«
auf einen anderen Knoten umgestellt werden.
Es empfiehlt sich folgendes Vorgehen beim ersten Starten des Galera Clusters:
node1: gcomm:// node2: gcomm://192.168.56.101 node3: gcomm://192.168.56.102
Anschließend die my.cnf von Knoten node1 wie folgt anpassen:
node1: gcomm://192.168.56.103
Jetzt kann jeder Knoten beliebig gestoppt und wieder gestartet werden. Nur, wenn man den Cluster neu initialisieren wollte, müsste man den ersten Knoten wieder mit
»gcomm://«
starten.
Die Parametern
»wsrep_sst_method«
und
»wsrep_sst_auth«
teilen dem Galera Cluster mit, welche Methode er für den SST verwenden soll und welcher Benutzer mit welchem Password dafür infrage kommt. Wenn mehr als ein Interface verwendet wird, sollte
»wsrep_sst_receive_address«
auf dasjenige Interface verweisen, auf dem der SST empfangen (und gesendet) werden soll. Andernfalls könnte es passieren, dass Galera das falsche Interface "errät" und der SST aus diesem Grunde fehlschlägt. Jetzt kann es endlich losgehen: Nachdem alle drei Knoten gestoppt sind, aktiviert man
»wsrep_provider«
in allen drei
»my.cnf«
-Dateien und startet den ersten Knoten:
/etc/init.d/mysql start
Zur Sicherheit sollte man das MySQL Error-Log unter
»/var/lib/mysql/node1.err«
auf mögliche Probleme prüfen. Wenn Fehlermeldungen wie in
Listing 5
auftauchen, liegt das daran, dass SELinux eingeschaltet ist. Das sollte man besser ausschalten. Temporär durch:
Listing 5
Fehlermeldungen
echo 0 >/selinux/enforce
und permanent in der Datei /etc/selinux/config:
SELINUX=permissive
Ist der Galera-Knoten erfolgreich gestartet, dann sieht man Ausgaben wie in Listing 6 . Der Knoten ist connected, ready und synced. Die Cluster-Größe ist zurzeit 1 und die lokale ID (Index) 0. Jetzt kann man den zweiten Knoten starten. Für eine kurze Zeit erscheint der Knoten 1 im Status "Donor":
Listing 6
Erfolgreicher Start
| wsrep_local_state_comment | Donor (+) |
Dies bedeutet, dass er auserwählt wurde, im Zuge des SST dem Knoten 2 die Daten zu übermitteln. Nach erfolgreichem Start des zweiten Knoten lässt sich der dritte Knoten starten. Sind alle Knoten erfolgreich gestartet, sehen die Status-Informationen wie in Listing 7 aus:
Listing 7
Cluster läuft
Anschließend darf nicht vergessen werden, auf dem ersten Knoten die Zeilen mit der
»wsrep_cluster_address«
auszutauschen:
# wsrep_cluster_address = "gcomm://192.168.56.103" # wsrep_cluster_address = "gcomm://"
Sonst findet der Knoten
»node1«
bei Neustart den Cluster nicht und versucht, einen neuen eigenen Cluster zu bilden. Anschließend lassen sich alle Knoten beliebig starten und stoppen.
Mit Loadbalancer
Aus Datenbank-Backend-Sicht existiert jetzt zwar ein hoch verfügbarer Datenbankcluster, aus Applikationssicht sieht das Ganze aber noch anders aus. Angenommen die Applikation verbindet sich gegen den Knoten 2 und dieser stirbt, dann muss sich die Applikation automatisch wieder mit einem anderen Knoten des Clusters konnektieren. Dies bewerkstelligt man am besten mit einem Loadbalancer. Dafür gibt es verschiedene Möglichkeiten:
- Man kann den Load-Balancing-Mechanismus in die Applikation direkt einbauen.
- Bei Java- oder PHP-Applikationen lässt sich die Failover-Funktionalität des entsprechenden Connectors nutzen (Connector/J [4] , mysqlnd-ms [3] ).
- Wenn man die Applikation nicht beeinflussen kann oder will, lässt sich alternativ ein Loadbalancer vorschalten. Das ist in Form eines Hardware-Loadbalancers, eines Software-Loadbalancers (wie zum Beispiel Pen [6] , GLB [7] , HAProxy [9] , LVS [8] , und so weiter) oder mit MySQL-Proxy [5] lösbar.
Grundsätzlich gibt es zwei Möglichkeiten, einen Loadbalancer zu platzieren: Zusammen mit der Applikation (auf dem Applikationsserver) oder bei größeren Setups zentral auf einem eigenen Server ( Abbildung 2 ).
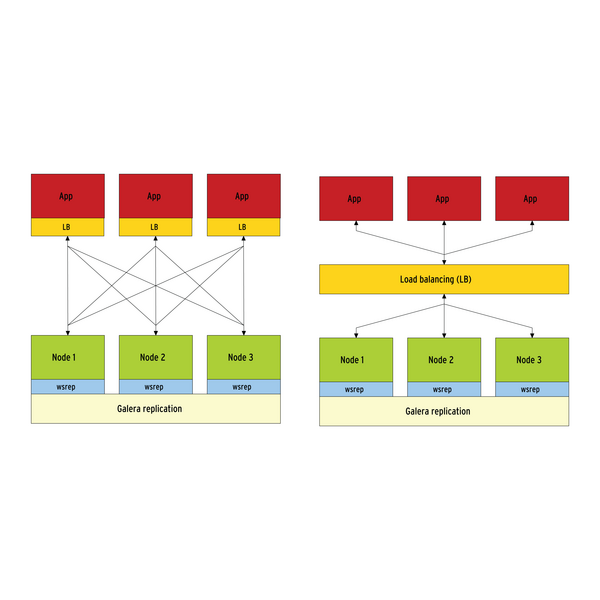 Abbildung 2: Grundsätzlich gibt es zwei Möglichkeiten, den Loadbalancer zu platzieren: auf dem Applikationsserver oder auf einem eigenen Server.
Abbildung 2: Grundsätzlich gibt es zwei Möglichkeiten, den Loadbalancer zu platzieren: auf dem Applikationsserver oder auf einem eigenen Server.
Muss man eine große Anzahl von Applikationen oder Servern verwalten, empfiehlt es sich, den zentralen Ansatz zu verfolgen. Handelt es sich aber nur um wenige Applikationen, ist der Aufwand für eine Installation, bei der sich Loadbalancer und Applikation auf derselben Maschine befinden, geringer und benötigt weniger Hardware.
Ähnliche Artikel
-
Multi-Master-MariaDB mit Galera

-
Galera Cluster für MariaDB
Auch die Entwickler des MySQL-Forks MariaDB haben nun die Galera-Cluster-Technologie implementiert.
-
Hochverfügbarkeit mit MariaDB

-
MaxScale-Proxy bringt LoadBalancing für MariaDB und MySQL
Ein Datenbank-Proxy mit Open-Source-Lizenz hilft bei der Skalierung von Datenbanken und schafft Ausfallsicherheit.
-
Workshop: Dienste ohne Pacemaker hochverfügbar betreiben

Konfigurationsmanagement

Themen


