Systeme: RAIN statt RAID

Geschützt im Regen

Eins ist sicher: Festplatten gehen kaputt. Sie sind sogar diejenigen Komponenten in IT-Setups, die mit Abstand am häufigsten vorzeitig das Zeitliche segnen. Zugleich gehören sie aber auch zu den Bauteilen, die moderne Infrastrukturen am notwendigsten haben. Denn Daten sind das Blut in den Adern moderner Applikationen, und die Menge an Daten, die in typischen Setups enthalten sind, wächst stetig.
In den vergangenen 25 Jahren haben sich verschiedene Ansätze herausgebildet, die den Umgang mit der hohen Fehleranfälligkeit von Festplatten erfassen. Den meisten Ansätzen ist gemein, dass sie auf RAID (Redundant Array of Independant Disks) basieren. Im Wesentlichen beschreibt RAID ein Prinzip, bei dem physische Platten zu logischen Geräten zusammengefasst werden, die gegenüber den einzelnen Festplatten einen Zusatznutzen versprechen, etwa höhere Performance oder größere Zuverlässigkeit. Im Hintergrund sorgt wahlweise ein RAID-Controller oder der Kernel des Servers dafür, dass Daten zwischen den einzelnen Platten des Verbundes hin- und herkopiert, also repliziert werden. Jede Information ist innerhalb eines RAID-Verbundes stets mehrere Male vorhanden. Daraus entsteht ein Vorteil für den Betrieb des Systems: Einzelne Datenträger können ausfallen, ohne dass der RAID-Verbund unbrauchbar wird. Die Fehlertoleranz eines RAID-Verbunds ist in allen Fällen deutlich höher als die einzelner Platten.
Mittlerweile gibt es eine ganze Reihe verschiedener RAID-Modi, die je nach Situation zum Einsatz kommen. RAID 1 beschreibt das bloße Spiegeln der Inhalte von einer Platte auf die andere, bei RAID 0 bilden zwei Platten ein logisches Laufwerk, was der Performance zuträglich ist, aber keinen Ausfallschutz bietet. Kombiniert wird daraus ein RAID 10, also gebündelte, gespiegelte Platten; lange Zeit galt dieser Modus als Königsweg im Hinblick auf Festplattenredundanz. Mittlerweile haben sich andere Varianten durchgesetzt: Der heute häufigste RAID-Modus ist RAID 5, bei dem jeweils Daten wie Metadaten über verschiedene Spindeln verteilt werden. Die höheren RAID-Level sind auch deshalb interessant, weil sie größere Arrays ermöglichen und so den gestiegenen Anforderungen in Sachen Plattenplatz gerecht werden. So ist ein RAID 5 mit dutzenden TByte kein Problem. Überdies ist besonders bei RAID 5 und RAID 6 der Overhead sehr gering, es bleibt also relativ viel von der ursprünglichen Brutto-Kapazität tatsächlich nutzbar. Ein RAID 1 benötigt für seine Redundanz stets 50 Prozent des zur Verfügung stehenden Speicherplatztes, sodass die Lösung als eher ineffizient gilt.
Insgesamt hat sich das Prinzip bewährt: Die meisten Server nutzen RAID für die Redundanz ihrer Daten, häufig liegt beispielsweise die Installation des Betriebssystems auf einem RAID 1.
Den Zenit überschritten
Und doch scheint es so, als habe RAID seinen Zenit für die großen Setups nun überschritten. In den vergangenen Jahren haben gleich mehrere Speicherlösungen den Markt aufgewühlt, und es wirkt so, als befinde sich der Storage-Markt im Umbruch. Was allen RAID-Alternativen gemein ist, ist die eine Fähigkeit, die RAID nicht bietet: Das nahtlose Skalieren in die Breite, also im Netzwerk. In Anlehnung an RAID wird der neue Ansatz auch als RAIN (Redundant Array of Inexpensive Nodes) bezeichnet.
Nahtlose Skalierbarkeit von Storage ist quasi auf der Cloud-Computing-Welle in die Planung von Rechenzentren geschwommen. Der dahinter stehende Gedanke ist einfach: Storage, das sich jederzeit um beliebige Komponenten erweitern lässt, kann beliebig groß werden und sogar Platz im PByte-Bereich bieten. Genau diese Eigenschaft allerdings fehlt im RAID-Konzept, und mithin fehlt sie auch allen auf RAID basierenden Ansätzen, darunter SAN-Storage oder typische NAS-Systeme.
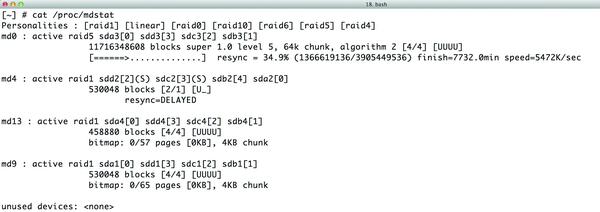 Bild 1: Bei RAID-Laufwerken – im Beispiel ein RAID 5 als Bestandteil eines NAS-Systems – kommt es im Falle eines Rebuilds zu langen Wartezeiten, während denen das Array nur sehr eingeschränkt nutzbar ist.
Bild 1: Bei RAID-Laufwerken – im Beispiel ein RAID 5 als Bestandteil eines NAS-Systems – kommt es im Falle eines Rebuilds zu langen Wartezeiten, während denen das Array nur sehr eingeschränkt nutzbar ist.
Mehrere Faktoren erschweren es, RAID-Geräte ohne Limit in die Breite zu skalieren. So weisen Festplatten eine inhärente Fehlerrate auf, deren Größe abhängig von Art und Qualität des genutzten Gerätes variiert. Besonders kritisch sind die nicht korrigierbaren Fehler, die letztlich dazu führen, dass eine Platte des Arrays auszutauschen ist. Je größer RAID-Arrays werden, desto höher ist die Wahrscheinlichkeit, dass beispielsweise im Falle eines Rebuilds mehr Platten unbehebbare Fehler aufweisen, als die spezifische RAID-Konfiguration erlaubt. Im schlimmsten Fall wird ein besonders großes RAID-Array, das viele TByte umfasst, durch unkorrigierbare Fehler unbrauchbar.
Daraus ergibt sich zwangsläufig, dass RAID-Verbunde nicht beliebige Größen erreichen können. Bei 4 TByte liegt momentan das Limit für Platten, die zu erschwinglichen Preisen verfügbar sind. Größere Geräte existieren zwar, reißen aber empfindliche Löcher ins Budget – und sind wegen der genannten Fehlerrate auch nicht beliebig miteinander in RAID-Verbünden kombinierbar. Ein RAID 5 oder 6 über 12 4-TByte-Platten gilt beispielsweise bereits als relativ groß und findet sich in freier Wildbahn eher selten.
Auch ohne unkorrigierbare Fehler haben RAID-Systeme ein Problem, wenn ein Rebuild der RAID-Metadaten notwendig wird. Bereits der Rebuild eines RAID mit 12 TByte Nettokapazität nimmt etliche Stunden in Anspruch, und während des Rebuilds stehen die auf dem RAID abgelegten Daten praktisch nicht zur Verfügung; der Rebuild frisst soviel Bandbreite, dass auf der Nutzerseite kaum noch Plattenperformance ankommt. Gleichzeitig steigt durch die lange Dauer des Rebuilds die Wahrscheinlichkeit, dass währenddessen wieder Fehler auftreten. Ähnliches gilt für die Parity-Checks, die bei RAID-Verbünden regelmäßig empfohlen sind – auch hier ist die Performance so stark vermindert, dass die effektive Nutzung des Dienstes während des Checks im Grunde unmöglich ist.
Apropos Performance: Handelsübliche Server können nur eine bestimmte Anzahl von Platten überhaupt aufnehmen, und an typische SATA- oder SAS-Controller lassen sich ebenfalls nur begrenzte Mengen an Platten anschließen. Wer als Admin möglichst viele Platten in ein System zwängen will, stößt früher oder später zwangsläufig auf Probleme: Entweder genügt die Bandbreite des Controllers nicht oder die im Server verbaute Backplane bietet nicht genügend Leistungsreserven. Und selbst wenn Admins das Maximum aus der Hardware herausholen, gelangen sie irgendwann an den Punkt, an dem nichts mehr geht: Ist das Gehäuse mit großen Platten voll, war's das und das Skalieren nimmt ein abruptes Ende.
Verteilter Storage als Lösung
Nun ist es nicht so, als sei die mangelnde Skalierbarkeit einzig und allein der RAID-Technik in die Schuhe zu schieben. Vielmehr war RAID über viele Jahre sehr nützlich, um aus denkbar schlechten Grundvoraussetzungen möglichst viel zu machen. Denn die fehlende Skalierbarkeit ist den Festplatten in die Wiege gelegt. Bei einer Festplatte handelt es sich bekanntlich um ein Block-Device, also ein Speichermedium, dessen Firmware den Speicher intern in einzelnen Blöcken verwaltet. Jeder handelsübliche Datenträger ist ein Block-Device, beispielsweise fällt auch ein USB-Stick in diese Kategorie.
Block-Devices sind ab Werk für Betriebssysteme zunächst nicht sinnvoll zu nutzen; zwar wäre es möglich, Daten auf ihnen abzulegen, doch müsste ein Client anschließend den kompletten Datenträger nach eben jenem Stück Information wieder absuchen, weil Block-Geräte zunächst keine logische Verwaltung haben. Dateisysteme rüsten auf der Ebene des Betriebssystems diese Organisationsschicht nach, allerdings sind handelsübliche Dateisysteme stets sehr eng mit den Datenträgern verbunden, auf denen sie installiert sind. Es ist beispielsweise nicht möglich, ein bereits existierendes Dateisystem in mehrere Schnipsel aufzuteilen und diese dann auf verschiedene Platten zu verteilen, also ein verteiltes System zu schaffen. Das ist aber die oberste Voraussetzung dafür, einen nahtlos skalierbaren Speicher zu konstruieren: das beliebige Verteilen der Daten.
RAID hat Admins über Jahre dabei geholfen, aus der Situation das Bestmögliche zu machen: Einerseits hat es viele physische Geräte zu größeren logischen Geräten zusammengefasst, andererseits hat es sich intern um die Redundanz der Daten gekümmert. Die vorher genannten Gründe zeigen, dass RAID nun am Ende seiner Möglichkeiten angekommen ist. Und Nachfolger stehen bereit: GlusterFS, Ceph und XtreemFS sind nur drei Ansätze, die seine Nachfolge antreten wollen.
Ähnliche Artikel
-
Das verteilte Dateisystem XtreemFS

-
Die verteilten Speichersysteme GlusterFS und Ceph im Vergleich

-
GlusterFS einrichten und nutzen

-
Workshop: Neue Features in DRBD 9

-
Red Hat kauft Ceph-Anbieter Inktank

Nach GlusterFS verleibt sich der Open-Source-Hersteller noch ein weiteres verteiltes Dateisystem ein.
Konfigurationsmanagement

Themen


