Datenrettung mit Linux
Datenrettung mit Linux
Wenn sich der Schaden schon hörbar ankündigt, ist schnelles Handeln gefragt: Eine Festplatte liegt in den letzten Zügen und wird in absehbarer Zeit komplett den Geist aufgeben. Oder der Laptop fällt vom Tisch und hat leider keine Beschleunigungserkennung eingebaut, die blitzschnell die Plattenköpfe in die Parkposition fährt. Schlägt der Versuch fehl, das darauf befindliche Dateisystem zu mounten, sollte man weitere manuelle Reparaturaktionen am besten unterlassen, statt weiteren Schaden anzurichten.
In viele Fällen sind Schäden, ob durch Gewaltanwendung oder lange Lebensdauer, auch im SMART-Status einer Festplatte zu erkennen. So versuchen moderne Festplatten, bei einem Problem selbständig Sektoren in andere Bereiche zu verlagern, die als Reserve für solche Fälle vorgesehen sind. Der Anwender hat darauf normalerweise keinen Einfluss, die Festplatte funktioniert hierbei als Blackbox. Immerhin kann man sich mit SMART einen Einblick verschaffen, ob und wie der Plattenspeicher das tut, zum Beispiel über den Wert "Reallocated_Sector_Ct", der solche Reallocations zählt. Der "Current_Pending_Sector"-Wert verrät, wieviele Sektoren noch beim Remapping ausstehen. Abbildung 1 zeigt einen Ausschnitt des SMART-Protokolls einer Platte, die zwar noch nicht sehr alt ist, aber durch einen Sturz vom Tisch einen physischen Schaden erlitten hat. Mehr Informationen über die Diagnose mit SMART sind im Artikel [1] zu finden.
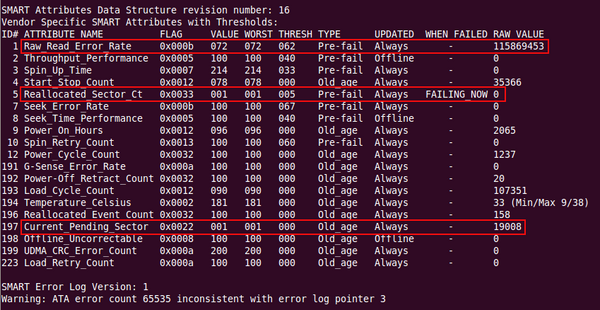 Abbildung 1: Schlechte Aussichten für diese Festplatte: Eine hohe Fehlerrate und jede Menge Pending Sectors, die keinen Platz mehr für ein Remapping finden.
Abbildung 1: Schlechte Aussichten für diese Festplatte: Eine hohe Fehlerrate und jede Menge Pending Sectors, die keinen Platz mehr für ein Remapping finden.
Image first
Statt Reparaturversuche direkt am defekten Datenträger zu starten, empfiehlt es sich, zunächst einmal ein möglichst vollständiges Image des kaputten Datenträger anzufertigen. Das Tool der Wahl ist dabei "ddrescue" [2] (in Ubuntu "gddrescue"), das ähnlich wie "dd" die Daten blockweise kopiert, ohne jedoch wie der Namensvetter bei einem Fehler abzubrechen. Stattdessen läuft "ddrescue" meist bis zum Ende durch und überspringt dabei fehlerhafte Blocks einfach. Wichtig ist dabei, ein Logfile anzulegen, in dem "ddrescue" über seinen Fortschritt, gelesene und fehlerhafte Blocks buchführt. Damit ist es auch kein Problem, das Tool abzubrechen und die Rettung später fortzusetzen:
ddrescue -v /dev/sdb4 /rescue/sdb4.img /rescue/sdb4.log
Hiermit versucht das Programm die Partition "sdb4" (vierte Partition der zweiten SATA-Platte) zu lesen und schreibt das Ergebnis in die Datei "/rescue/sdb4.img". Genauso ist es möglich, statt einer Partition die komplette Platte zu lesen, man muss sich später aber dann wieder um die Partitionen einzeln kümmern.
Je nach Schaden kann das Lesen ziemlich lange dauern, hier sollte man geduldig sein. Im konkreten Fall einer defekten NTFS-Partition dauerte es mehrere Tage, nur 50 GByte zu lesen! Glücklicherweise ging es dann beim unversehrten Teil wesentlich schneller.
Gut ausgedacht
Im Normalfall gibt es keinen Grund, "ddrescue" mit besonderen Optionen zu starten, denn es verwendet schon von Haus aus einen vernünftigen und effektiven Algorithmus, um möglichst viele Daten zu retten:
- Im ersten Durchgang geht es, wie erwähnt, über defekte Blocks hinweg und kopiert soviele lesbare Blocks wie möglich.
- Im zweiten Durchlauf versucht es noch einmal, defekte Blocks zu lesen und setzt dabei bei dessen Sektoren einmal von vorne und einmal von hinten an, um möglichst viele Sektoren jenseits der Fehlerstelle zu lesen. Hierbei nimmt, wenn alles gut geht, die Menge der defekten Daten ab (Abbildung 2). Unter Umständen steigt aber die Anzahl der Fehler, weil statt eines Fehlers mehrere defekte Sektoren gezählt werden.
- Beim dritten Versuch kommen die verbliebenen defekten Sektoren noch einmal dran. Mit dem Schalter "-r" (--retry-passes) versucht das Tool dies sogar mehrmals.
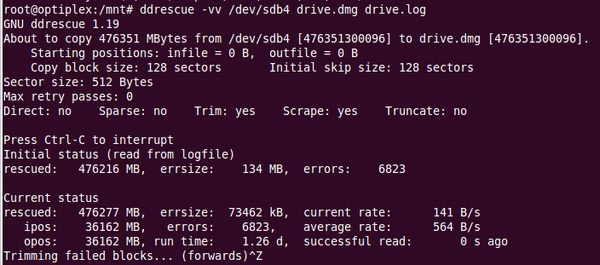 Abbildung 2: Im zweiten Durchlauf versucht "ddrescue", die im ersten Durchgang übersprungenen fehlerhaften Sektoren zu lesen. Mit etwas Glück sinkt hier die Fehlerquote.
Abbildung 2: Im zweiten Durchlauf versucht "ddrescue", die im ersten Durchgang übersprungenen fehlerhaften Sektoren zu lesen. Mit etwas Glück sinkt hier die Fehlerquote.
Die Kopie kann in einer Image-Datei oder direkt in einer Partition landen. Letzteres hat den Vorteil, dass man nicht mehrere Hundert Gigabyte große Dateien herumschieben muss. Dafür ist die Option "-f" nötig, die bestätigt, dass man wirklich eine existierende Partition überschreiben möchte. Dagegen bietet "ddrescue" bei Image-Dateien den Vorteil, sie als Sparse-Dateien schreiben zu können, die leeren Platz effizient verwalten. Das ist möglicherweise günstig, wenn man eine Partition retten will, auf der sich wenig Daten befinden. Der dazu gehörige Kommandozeilenschalter lautet "-S".
Sollte wider Erwarten ein schwerer Fehler auftreten, der zum Abbruch des "ddrescue"-Tools führt, ist es auch möglich, den Lesevorgang von hinten zu beginnen, um sich der Problemzone von der anderen Seite zu nähern. Dazu dient der Schalter "-R". Alternativ oder ergänzend dazu lässt sich ein Leseversuch mit "-i" an einer bestimmten Stelle (in Bytes gerechnet) starten. in allen Fällen ist die Verwendung des Logfile obligatorisch, denn nur damit kann "ddrescue" von den bisher erarbeiteten Ergebnissen profitieren. Eine Übersicht aller verfügbaren Kommandozeilenschalter ist in der Manpage von "ddrescue" zu finden [3].
Ähnliche Artikel
-
Eine Tour durch die Debugging- und Rettungs-Tools in Knoppix

- Festplattenpartitionen über das Netzwerk sichern
-
Microsoft Windows File Recovery
-
Partition Logic beherrscht jetzt GPT
Der freie Partitionsmanager kann in der neuesten Version mit GPT-Partitionstabellen umgehen.
-
Schwerpunkt: Daten auf SSDs wiederherstellen

Konfigurationsmanagement

Themen


