Dinodes
Betrachtet man den Quelltext von GFS2, fällt der Begriff Dinode auf. Dies hat nichts mit der dynamischen Inode-Allokierung zu tun. Dinode steht für Disk Inode und ist die Repräsentation des Inode im Speicher. (Vergleiche: Die Repräsentation der Inode im Virtual Filesystem, VFS, heißt Vnode.) Um konkurrierende Blockzugriffe zu vermeiden, ordnet GFS2 jedem Block höchstens einen Inode zu (Abbildung 3).
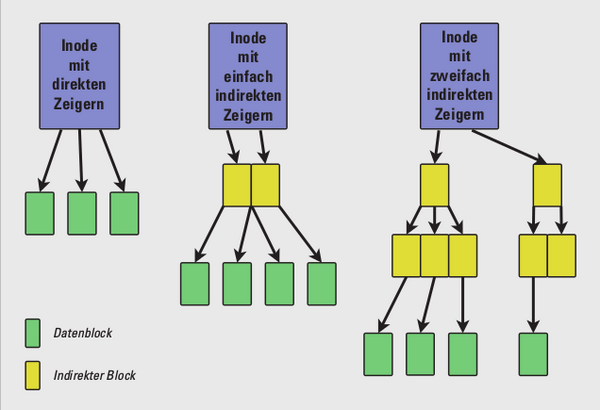 Abbildung 3: Die Datenblockzeiger eines GFS2-Inodes kennen stets nur eine Stufe der Indirektion.
Abbildung 3: Die Datenblockzeiger eines GFS2-Inodes kennen stets nur eine Stufe der Indirektion.
Im Inode-Header finden sich die üblichen Angaben: Inode-Nummer, RG-Nummer, UID und GID, Dateimodus, Anzahl der Hardlinks, Blöcke und Bytes, Zeitinformationen über den letzten Zugriff und die letzte Änderung. Im InodeBlock befinden sich entweder direkt die Nutzerdaten – man spricht dann von einem stuffed Inode – oder aber Zeiger auf weitere Blöcke. Diese weiteren Blöcke enthalten dann entweder die Daten oder aber weitere Zeiger auf weitere Blöcke. Die Stufe der Indirektion errechnet sich aus der Größe der Datei und der Dateisystemblöcke. Das traditionelle UFS-Konzept von direkten, indirekten und zweifach-indirekten Zeigern ist im GFS2 abgewandelt. Es treten immer nur Zeiger einer Stufe der Indirektion auf, also nur direkte Zeiger, nur einfach indirekte oder nur zweifach indirekte (Abbildung 3).
Für eine performante Verzeichnisverwaltung nutzt GFS2 das Extendible Hashing (Abbildung 4). Zu jeder Datei speichert GFS2 die ersten n Bits des Hash-Werts über den vollständigen Dateinamen in einer Hash-Tabelle. Der zugehörige Eintrag verweist auf einen so genannten Leaf Block auf der Platte. Dieser Block entspricht dann einem Verzeichnis, das die Datei enthält. Mit wachsender Anzahl von Dateien wächst n und damit die Größe der Hash-Tabelle. Das System vergrößert die Hash-Tabelle stets durch Verdoppeln. Hash-Tabelle und Leaf Block speichert GFS2 in normalen Datenblöcken.
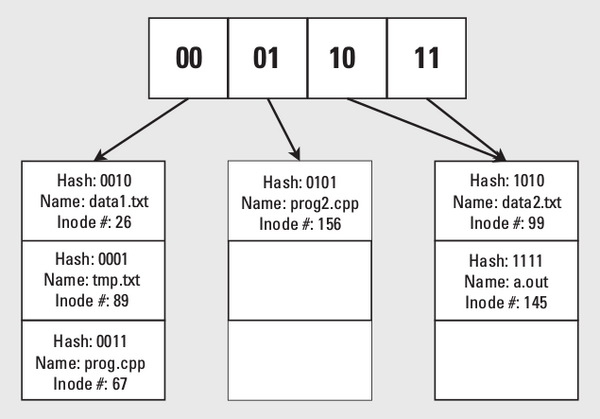 Abbildung 4: Eine zweibittige Hashtabelle für das Extendible Hashing von GFS2.
Abbildung 4: Eine zweibittige Hashtabelle für das Extendible Hashing von GFS2.
Der Locking-Mechanismus gewährleistet, dass jeweils nur ein Cluster-Rechner einen Inode ändern kann. Schreiben viele Knoten gleichzeitig in ein Verzeichnis, führt das zu Leistungseinbußen, da der Schreib-Lock ständig hin- und herwandert. Es ist zu prüfen, ob jeder Rechner ein separates Verzeichnis erhalten kann. Die aus GFS Version 1 bekannten Context Dependent Path Names (CDPN) gibt es in Version 2 nicht mehr. Das Konzept von CPDN erlaubt das Anlegen von Verzeichnissen, die den gleichen Namen haben, aber abhängig vom Betrachtungspunkt sind. Unter GFS1 war folgendes Szenario möglich: Im Beispiel-Cluster ist ein GFS1 auf den zwei Knoten »test1« und »test2« unter »/data« gemountet. Dazu kommen zwei Unterverzeichnisse mit jeweils einer Datei, die als Namen die Hostnamen der beiden ClusterRechner verwenden. Der Admin legt nun einen symbolischen Link »/data/testrechner« an, wobei die Quelle den CDPN des Hostnamens verwendet. Je nachdem, welcher Rechner auf das Verzeichnis »/data/testrechner« zugreift, erfolgt der tatsächliche Zugriff dann auf das Verzeichnis »/data/test1.beispiel. de« oder »/data/test2. beispiel.de«.
Bei GFS2 kann der Admin unter Verwendung der so genannten Bind Mounts ein ganz ähnliches Setup entwerfen. Im Vergleich zu GFS1 sind allerdings mehr Schritte nötig und der Systemadministrator muss zudem bestimmte Kommandos auf jedem Cluster-Knoten ausführen. Das für GFS1 gezeigte Szenario ist auf diese Weise im Beispiel-Cluster auch unter GFS2 umgesetzt. Beim Dateizugriff ergibt sich wieder genau das gewünschte Verhalten. Die höhere Flexibilität der Bind Mounts bei GFS2 im Vergleich zu den CDPN von GFS1 geht allerdings auch mit einem deutlich höheren Wartungsaufwand einher.
Verwaltung
Zur Basisverwaltung von GFS2 stehen die üblichen Tools zur Verfügung: »mkfs.gfs2«, »mount.gfs2« und »fsck.gfs2«. Aufgrund der besonderen Natur des Cluster-Dateisystems muss der Admin beim Anlegen des GFS2 einige Infos bereitstellen: die Anzahl der Journale, den Locking-Mechanismus und einen Lock-TableNamen. Aus dem gleichen Grund muss man das Anlegen des GFS2 nur auf einem Knoten durchführen. Die Anzahl der Journale entspricht der Anzahl der Cluster-Knoten, die auf das GFS2 zugreifen sollen. Eine nachträgliche Erhöhung
der Journal-Anzahl ist nur möglich, wenn noch freier Storage vorhanden ist. In der Standardeinstellung beträgt die Journalgröße 128 MByte. Der Admin kann dies während der Installation auf einen anderen Wert setzen, 32 MByte ist die Mindestgröße. Der Locking-Mechanismus ist entweder »lock_dlm«, oder im Single-Node-Betrieb auch »lock_nolock«. Der Name der Lock-Tabelle besteht aus zwei durch einen Doppelpunkt getrennten Zeichenketten. Der erste String ist der Cluster-Name, zu entnehmen aus der Cluster-Konfiguration. Die zweite Stelle ist für den Namen des Dateisystems reserviert. Dieser muss Cluster-weit eindeutig sein. Über weitere Optionen kann man auch die Blockgröße und/oder die Größe der RG abweichend vom Standardwert festlegen – hier sei auf die Manpage von »mkfs.gfs2« verwiesen.
Das Einhängen des GFS2 mit dem MountKommando erfolgt ganz wie gewohnt. Mittels Mount-Optionen kann man dabei bestimmte Informationen aus dem Superblock des Dateisystems überschreiben, zum Beispiel den LockingMechanismus. Besonders erwähnenswert ist die Option »acl« die die Unterstützung von Access Control Lists aktiviert. Im Normalfall sind die Dabei ist zu beachten, dass der erste Knoten, der das GFS2 mountet, alle Journale einliest und auswertet. Jeder weitere Knoten prüft nur noch sein eigenes Journal.
Ein Dateissystemcheck sollte im Normalbetrieb überhaupt nicht vorkommen, da bei Ausfall eines Knotens, ein anderer Cluster-Rechner dessen Journal auswertet. Dazu kommt, dass man »fsck.gfs2« nicht auf gemountete Dateisysteme anwenden kann. Ein Aushängen des GFS2 muss damit Cluster-weit erfolgen, was letztlich eine Deaktivierung des Cluster mit sich bringt. Wie in der Unix-Welt üblich, erfolgt ein Dateisystemcheck in mehreren Phasen. Nach einer Initialisierungsphase, in der »fsck.gfs2« unter anderem die Journal-Dateien säubert, findet zunächst eine Überprüfung der Metadaten der RG statt. Danach checkt das Tool die Datenblöcke und im Anschluss die Inodes. Zum Abschluss aktualisiert das System die Metadaten der Resource Groups.
Das GFS2 im Beispiel-Cluster bekommt zunächst nur zwei Journal-Dateien. Der erste Teil der Lock-Tabelle muss mit dem Cluster-Namen aus der »cluster.conf« (siehe Listing 2) übereinstimmen und lautet daher »gfs2«. Der Clusterweit eindeutige Dateisystemname ist »gfs2test«. Wie bereits beschrieben, übernimmt DLM das Locking. Die Größe der Dateisystemblöcke, der Journale und der Resource Groups entspricht den Standardwerten. Das vollständige Kommando inklusive Konsolenausgaben ist in Listing 4 dargestellt.
Listing 4: »mkfs« und »mount«
# mkfs.gfs2 ‑j 2 ‑t gfs2:gfs2test /dev/sda1 This will destroy any data on /dev/sda1.
Are you sure you want to proceed? [y/n] y
Device: /dev/sda1 Blocksize: 4096 Device Size 18.01 GB (4721094 blocks) Filesystem Size: 18.01 GB (4721094 blocks) Journals: 2 Resource Groups: 73 Locking Protocol: "lock_dlm" Lock Table: "gfs2:gfs2test" UUID: 0EA2D58C‑7D9F‑743A‑456E‑5047AD0F0FC6
# mount ‑t gfs2 /dev/sda1 /gfs2data/ # tail /var/log/messages ... Sep 5 13:43:43 test1 kernel: GFS2: fsid=: Trying to join cluster "lock_dlm", "gfs2:gfs2test" Sep 5 13:43:43 test1 kernel: dlm: Using TCP for communications Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: Joined cluster. Now mounting FS... Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=0, already locked for use Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=0: Looking at journal... Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=0: Done Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=1: Trying to acquire journal lock... Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=1: Looking at journal... Sep 5 13:43:43 test1 kernel: GFS2: fsid=gfs2:gfs2test.0: jid=1: Done
# umount /gfs2data/ # # fsck.gfs2 /dev/sda1 Initializing fsck Recovering journals (this may take a while). Journal recovery complete. Validating Resource Group index. Level 1 RG check. (level 1 passed) Starting pass1 . Starting pass5 Pass5 complete Writing changes to disk gfs2_fsck complete #
Ähnliche Artikel





Konfigurationsmanagement

Themen


