Workshop: Docker-Sicherheit

Schön eingesperrt

Docker eignet sich hervorragend dazu, eine Microservice-basierte Architektur umzusetzen. Die einzelnen Services laufen dabei komplett isoliert voneinander. Diese und ähnliche Aussagen gibt es immer wieder, wenn es um die Erfolgsgeschichten von Docker geht. Aber stimmen diese Aussagen überhaupt? Und wie unterscheiden sich Container eigentlich von komplett virtualisierten Systemen? Diese und andere Fragen betrachten wir in diesem Artikel.
Geht es um die Sicherheit von Docker-Containern, so ist es zuerst einmal wichtig den Unterschied zu komplett virtualisierten Systemen zu verstehen. Ansonsten droht schnell die Gefahr, Container lediglich als bessere virtuelle Systeme anzusehen, die sich schneller erzeugen und starten lassen. Während die letzte Aussage sicherlich stimmt, unterscheiden sich Container und virtuelle Systeme doch gewaltig voneinander.
Docker arbeitet auf Prozessebene, erzeugt also Container innerhalb einer einzelnen Linux-Instanz. Anders als bei virtuellen Systemen ist es hier nicht notwendig, ein komplettes System inklusive Hardware zu emulieren. Container teilen sich die Ressourcen des Host-Systems, auf dem sie laufen, verbrauchen daher auch recht wenig Ressourcen und sind somit im Vergleich zu virtuellen Systemen sehr schlank. Diese fehlende Isolierung zwischen Host-System und den einzelnen Containern ist jedoch auch eins der größten Probleme.
Virtuelle Systeme verwenden jeweils ihren eigenen Kernel. Möchte ein Angreifer aus einem solchen System ausbrechen, muss er verschiendenste Schutzmauern unterwandern. Selbst wenn ein Angriff auf den Kernel des Gast-Systems gelingt, so ist im nächsten Schritt der Hypervisor anzugreifen und Schutzmechanismen, wie beispielsweise SELinux, auszuhebeln, bevor ein Angriff auf den Kernel des Host-Systems erfolgen kann. Container teilen sich die Ressourcen des Hosts und haben somit auch direkten Zugriff auf den Host-Kernel. Ein Angriff auf diesen wäre also wesentlich einfacher möglich als bei virtuellen Systemen. Hier gilt es für den Verantwortlichen, zusätzliche Schutzmauern zu errichten, damit ein potenzieller Angreifer mehrere Hürden überwinden muss.
Scheinbare Isolation dank Namespaces
In den letzten Monaten wurden immer mehr solcher Schutzmauern um Docker herum aufgebaut, sodass nun eine Vielzahl von Klippen zu umschiffen sind, um erfolgreich aus einem Container auszubrechen. Grundlegend sind sogenannte Namespaces dafür zuständig, einem Container eine Art isolierte Umgebung innerhalb des Host-Systems vorzugaukeln. Docker verwendet Namespaces für fünf verschiedene Bereiche:
- UTS (Systemidentifikation): Hiermit bekommt jeder Container einen eigenen Host- und Domänennamen zugewiesen.
- IPC (Interprozess-Kommunikation): Container verwenden voneinander unabhängige IPC-Mechanismen, beispielsweise für Message-Queues.
- PID (Prozess-IDs): Jeder Container verwendet einen eigenen Raum für die Prozess-IDs. Somit können Prozesse in unterschiedlichen Containern die gleiche PID besitzen, obwohl diese auf dem gleichen Host-System ablaufen. Jeder Container kann beispielsweise einen Prozess mit der ID 1 enthalten.
- MNT (Mountpoints des Dateisystems): Prozesse in unterschiedlichen Containern haben einen individuellen "View" auf das Dateisystem und können lediglich auf Objekte zurückgreifen, die auf Dateisystemen innerhalb des eigenen Namespaces liegen.
- NET (Netzwerkressourcen): Jeder Container bekommt seinen eignen Netzwerkstack und somit auch sein eigenes Netzwerkgerät mit eigener IP-Adresse und Routing-Tabelle.
Seit dem Linux-Kernel 3.8 steht ebenfalls ein User-Namespace zur Verfügung. Prozesse außerhalb und innerhalb eines Containers können voneinander unabhängige Benutzer- und Gruppen-IDs besitzen. Das ist hilfreich, da somit ein Prozess außerhalb des Containers eine unprivilegierte ID besitzen kann, während er innerhalb des Containers als ID 0 abläuft und somit komplette Kontrolle über den Container, nicht aber über das Hostsystem besitzt. User-Namespaces sind recht neu und werden aktuell noch nicht von Docker verwendet. In der nahen Zukunft ist jedoch mit deren Einsatz zu rechnen.
Dem aufmerksamen Leser dürfte an dieser Stelle auffallen, dass zu Beginn des Artikels erwähnt wurde, dass Container Zugriff auf den Kernel des Host-Systems haben. Wie kann dies aber sein, wenn durch den MNT-Namespace ein Container lediglich Zugriff auf Objekte eines bestimmten Namespaces bekommt? Dies liegt einfach daran, dass nicht alle Dateisysteme einen eigenen Namespace erhalten. Verzeichnisse wie beispielsweise
»/sys«
oder
»/proc«
stellt der Host allen Containern zur Verfügung. Glücklicherweise stehen diese mittlerweile lediglich als Read-only-Ressourcen zur Verfügung, sodass sich das Verhalten des Host-Kernels nicht aus einem Container heraus verändern lässt. Das folgende Beispiel demonstriert dies recht anschaulich:
# docker run --rm -t -i fedora /bin/bash
# cat /proc/sys/net/ipv4/ip_forward1
# echo 0 > /proc/sys/net/ipv4/ ip_forward
bash: /proc/sys/net/ipv4/ip_forward: Read-only file system
Nachdem ein Container auf Basis eines Fedora-Images gestartet worden ist, enthält die Datei
»/proc/sys/net/ipv4/ip_forward«
den gleichen Wert wie auf dem Host-System. Ein Ändern der Datei ist aus dem Container heraus allerdings nicht möglich, da das Dateisystem
»/proc/sys«
lediglich read-only eingebunden wurde. Gleiches gilt übrigens auch für
»/sys, /proc/sysrq-trigger, /proc/irq«
und
»/proc/bus«
.
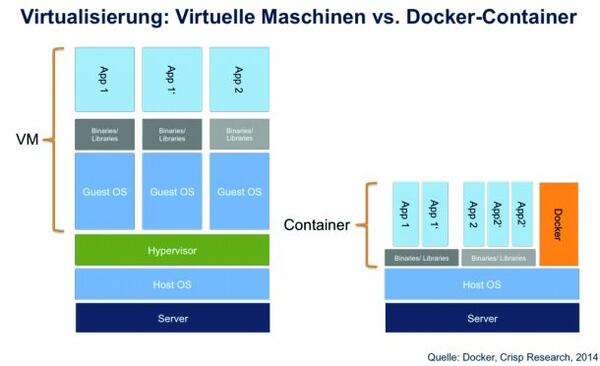 Zwischen virtuellen Systemen und Containern existieren gravierende Unterschiede in der Architektur.
Zwischen virtuellen Systemen und Containern existieren gravierende Unterschiede in der Architektur.
Cgroups bieten Schutz vor DoS
Unter anderem, um Container vor möglichen Denial-of-Service-Angriffen zu schützen, greift Docker auf Cgroups zurück. Hiermit lassen sich einzelne Prozesse zu Gruppen zusammenfassen, um für diese dann Ressource-Limits zu definieren. Somit kann es nicht mehr passieren, dass Prozesse eines einzelnen Containers sämtliche Ressourcen eines Hosts in Anspruch nehmen und somit die Stabilität des gesamten Systems gefährden. Docker unterstützt die Limitierung von CPU, Speicher und Block-I/O. Im einfachsten Fall geben Sie die gewünschten Limits einfach beim Starten eines Containers an oder passen sie zur Laufzeit an. Das folgende Beispiel startet einen Container mit einem vorinstallierten Load-Generator und limitiert die Speichernutzung für diesen Container auf 512 MByte. Der Load-Generator wird zeitgleich angewiesen, Speicher bis zu 2 GByte zu allokieren:
# docker run -it --rm -m 512m fedora:stress --vm 1 --vm-bytes 2G --vm-hang 0
stress: info: [1] dispatching hogs: 0 cpu, 0 io, 1 vm, 0 hdd
stress: FAIL: [1] (415) <-- worker 7 got signal 9
stress: WARN: [1] (417) now reaping child worker processes
stress: FAIL: [1] (421) kill error: No such process
stress: FAIL: [1] (451) failed run completed in 2s
Erzeugen Sie einen neuen Container, ohne den Speicher mittels der Option
»-m«
zu beschränken, wird dies ohne Probleme funktionieren. Allerdings empfehlen wir an dieser Stelle ausdrücklich, Container immer mit einem Limit für Memory und CPU zu starten, um zu vermeiden, dass ein einzelner Container sämtliche Ressourcen in Anspruch nehmen kann.
Das Cgroup-Subsystem ist auch dafür verantwortlich, einem Container lediglich eine gewisse Anzahl von Gerätedateien des Hosts einzubinden. Diese bekommen keinen eigenen Namespace zur Verfügung gestellt, sodass Sie hier diesen Trick über die Cgroups verwenden müssen. Schließlich möchten Sie sicherlich nicht, dass Prozesse aus einem Container heraus auf Dateien wie beispielsweise
»/dev/mem«
oder
»/dev/sd*«
des Hosts zurückgreifen können. Üblicherweise bekommt ein Prozess Zugriff auf sämtliche Geräte-Dateien:
# cat /sys/fs/cgroup/devices/system.slice/docker.service/devices.list
a *:* rwm
Für einen Container-Prozess sieht diese Liste jedoch anders aus:
# cat
# /sys/fs/cgroup/devices/system.slice/<docker-container-id>.scope/devices.list
c *:* m
b *:* m
c 5:1 rwm
c 4:0 rwm
c 4:1 rwm
c 136:* rwm
c 5:2 rwm
c 10:200 rwm
c 1:3 rwm
c 1:5 rwm
c 1:7 rwm
c 5:0 rwm
c 1:9 rwm
c 1:8 rwm
Ähnliche Artikel
-
Docker-Workshop (1): Installation, erste Schritte

-
Workshop: Anwendungsvirtualisierung mit Docker
-
Docker 1.3 erlaubt signierte Images

Die digitale Signatur von Container-Images soll für mehr Sicherheit sorgen.
-
VMware veröffentlicht Docker-Security-Guide

Der Virtualisierungsexperte hat zusammen mit dem Center for Internet Security einen Sicherheitsleitfaden für Docker erarbeitet.
-
Docker 1.2 veröffentlicht

Die neuen Restart-Policies ermöglichen es, dass Docker-Container im Fehlerfall neu starten.
Konfigurationsmanagement

Themen


