Storage für Microsoft SQL Server konfigurieren
Schrauben an der Datenbank

Um die ideale Storage-Konfiguration für Microsoft SQL Server zu ermöglichen, wollen wir zunächst einen genaueren Blick auf die Vorgänge beim Lesen und Schreiben werfen.
So funktionieren Schreib- und Leseprozesse
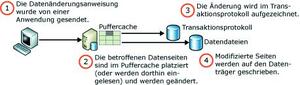
Der Schreibprozess innerhalb von Microsoft SQL Server unterteilt sich in drei Stufen, die unterschiedliche Bereiche der Hardware betreffen. Es wird zwischen logischen und physischen Schreibvorgängen unterschieden. Ein logischer Schreibvorgang findet statt, wenn Microsoft SQL Server Daten im Buffer-Pool ändert (INSERT, UPDATE, DELETE). Ein physischer Schreibvorgang wird generiert, wenn diese geänderten Daten vom Buffer-Pool auf den Datenträger geschrieben werden.
Ein Datensatz wird nicht unmittelbar physisch geschrieben, sondern im Buffer-Pool als
...Der komplette Artikel ist nur für Abonnenten des ADMIN Archiv-Abos verfügbar.
Ähnliche Artikel
-
SQL-Server für SharePoint optimieren

-
OCZ beschleunigt Datenbanken
Mit einem neuen Produkt, dem ZD-XL SQL Accelerator, will der SSD-Spezialist OCZ eine Plug-and-Play-Lösung vorstellen, die Microsofts SQL Server Beine machen soll.
-
SQL Server: Heap vs. gruppierter Index

-
Performance-Troubleshooting von Microsoft SQL Server (2)

-
Performance-Troubleshooting von Microsoft SQL Server (1)

Konfigurationsmanagement

Themen


