Monitoring und Alerting mit Open Source

Alarmstufe Rot

In der Juli-Ausgabe 2019 haben wir über Teile des sogenannten TICK-Stacks (Telegraf, InfluxDB, Chronograf, Kapacitor) als Monitoringtool berichtet [1]. Anstatt "C" setzte der Workshop jedoch auf "G" wie Grafana für die grafische Oberfläche. Das Werkzeug ist verbreiteter als Chronograf und beherrscht neben InfluxDB auch andere Datenquellen. Zudem beschränkte sich die Telegraf-Konfiguration darauf, SNMP-Informationen aktiver Komponenten wie beispielsweise eines NAS abzurufen und grafisch darzustellen.
Als Erweiterung des damaligen Workshops geht es nun darum, mit Hilfe von Telegraf-Plug-ins und dem alternativen Tool "collectd" wichtige Metriken über den Zustand aktiver Komponenten und Sensoren zu erhalten und entsprechende Alarme zu definieren. Das Monitoringsystem kann dann rechtzeitig den Administrator warnen, falls Betriebsparameter außerhalb des grünen Bereichs operieren. Im Beispiel nutzen wir einen Telegram-Bot, um Alarme via Messaging-Dienst an eine Gruppe von Administratoren zu senden. Zudem sollen essenzielle Netzwerkdienste wie der DNS-Service oder andere Applikationen überwacht werden.
Statusabfrage des DNS-Dienstes
Zu den wichtigsten Diensten im Rechenzentrum gehört der DNS-Service. Egal, ob dieser standalone arbeitet oder als Teil eines Verzeichnisdienstes – ohne DNS funktioniert der Großteil der Netzwerkinfrastruktur nicht. Oft jagen Administratoren kuriosen Fehlern hinterher, nur um dann festzustellen, dass DNS-Probleme die Ursache waren – oder eine fehlerhafte Zeitsynchronisation. Daher sollten Sie den Zustand Ihrer DNS-Server stets im Blick haben. Telegraf selbst liefert bereits ein passendes Plug-in für den DNS-Dienst. Wir gehen davon aus, dass Sie auf dem Influx-Server bereits eine Telegraf-Instanz laufen haben. Die Konfiguration unter "/etc/telegraf/telegraf.conf" bekommt nun weitere Zeilen:
[[inputs.dns_query]]
servers = ["<IP-Adresse des ersten Nameservers>","<IP-Adresse des zweiten Nameservers>"]
network = "udp"
domains = ["<Abzufragende FQDN>"]
record_type = "A"
port = 53
timeout = 2
Der Eintrag "servers" enthält die IP-Adressen aller DNS-Server im lokalen Netzwerk. Die Konfiguration "domain" gibt an, nach welchem Namen gefragt werden soll. Hier liegt es in Ihrem Ermessen, ob Sie einen hausinternen Namen verwenden und damit die Funktion der lokalen DNS-Zone prüfen. Auch ein externer Name ist möglich und prüft kontrolliert die Verbindung zum Internet und dem DNS-Forwarding-Dienst. Das Angeben mehrerer FQDNs ist erlaubt.
Um den neuen Input zu testen, starten Sie Telegraf zunächst im Debug-Modus für einzelne Filter:
telegraf -input-filter dns_query -test –debug
Das Ergebnis sieht dann in etwa so aus:
dns_query,
domain=(<Abgefragte FQDN>),
host=(<Name des Hosts, auf dem Telegraf läuft>),
rcode=NOERROR,record_type=A,result=success,
server=(<IP des abgefragten DNS-Servers>),
query_time_ms=0.514688,rcode_value=0i,result_code=0i
Telegraf stendet alle Werte an die Influx-Datenbank zur Auswertung. Für den Administrator sind vor allem die Informationen aus "query-Time" und "result_ code" von Interesse. Der letztgenannte Parameter liefert "0" für OK, "1" für Timeout und "2" für einen Fehler zurück. Später wird Grafana hierfür einen Alert im Stil von "Wenn Result_code nicht 0, dann Alarm" erstellen.
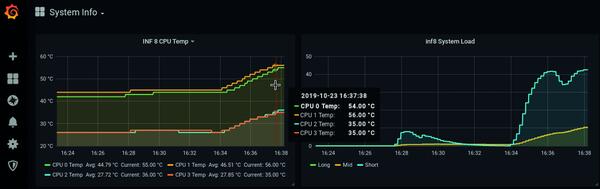 Bild 1: Dieses Panel kombiniert Werte, die collectd vom Server (Load) und via IPMI (CPU-Temperatur) sammelt. Der Chart zeigt, wie die CPU-Temperaturen steigen, wenn das System unter Last steht.
Bild 1: Dieses Panel kombiniert Werte, die collectd vom Server (Load) und via IPMI (CPU-Temperatur) sammelt. Der Chart zeigt, wie die CPU-Temperaturen steigen, wenn das System unter Last steht.
Webdienste via HTTP-Abfrage prüfen
Ähnlich einfach kann Telegraf den Webdienst oder die API eines Services via HTTP-Abfrage prüfen. In unserem Beispiel soll das Monitoring überwachen, ob der Managementserver des Red-Hat-Virtualization-Clusters erreichbar ist und antwortet. Das Plug-in "inputs.http_response" von Telegraf erlaubt eine Fülle von Konfigurationsoptionen für Benutzernamen, Kennwort und Zertifikate. Für einen ganz simplen Check, ob der Dienst am Leben ist oder nicht, braucht es aber gar keine komplexe Abfrage. Im Beispiel fragt Telegraf einfach die API des Diensts an, erwartet ein "Unauthorized" als Antwort und ignoriert dabei das selbstsignierte HTTPS-Zertifikat des Diensts:
[[inputs.http_response]]
urls = ["https://rhvm.local.ip/ovirt-engine/api"]
response_timeout = "5s"
method = "GET"
response_string_match = "Unauthorized"
insecure_skip_verify = true
Wie schon beim DNS-Check kann Telegraf mehrere Hosts abfragen und auch hier erhalten wir eine "response_time" und einen "result_code" als Antwort, was sich später für Alarme nutzen lässt. Nach diesem Beispiel können Sie fast jeden beliebigen Netzwerkdienst mit einem Web-Frontend oder einer API abfragen.
Ähnliche Artikel





Konfigurationsmanagement

Themen


