
Einrichten eines hochverfügbaren Speicherbereichs
openATTIC hat bei der Initialisierung der Datenbank die beiden angelegten Volume-Gruppen erkannt und stellt sie zur Nutzung zur Verfügung. Für unser Beispiel legen Sie nun ein unformatiertes Volume namens "vms01" in der Volume-Gruppe "volgrp1" an (Bild 2). Jetzt erscheint ein Fenster, das Ihnen als zusätzliche Option das Spiegeln des Volumes anbietet. Klicken Sie auf den entsprechenden Button und füllen Sie das erscheinende Formular aus: Ausgewählt werden "Host oa02 "und seine Volume-Group "volgrp2" sowie "30M" bei der Synchronisationsrate.
Nach dem Klick auf “Choose” legt openATTIC eine DRBD-Konfiguration an, die derjenigen sehr ähnlich sieht, die wir für die Datenbank händisch konfiguriert haben. Bestätigt wird das durch das Setzen eines grünen Hakens an der Mirror-Option. Diese Verbindung taucht in der Oberfläche als neues Volume auf, das Sie anschließend über den Knopf “Create Filesystem” formatieren können. Wenn alles erledigt ist, sollte Ihre Volume-Verwaltung aussehen wie in Bild 3 dargestellt.
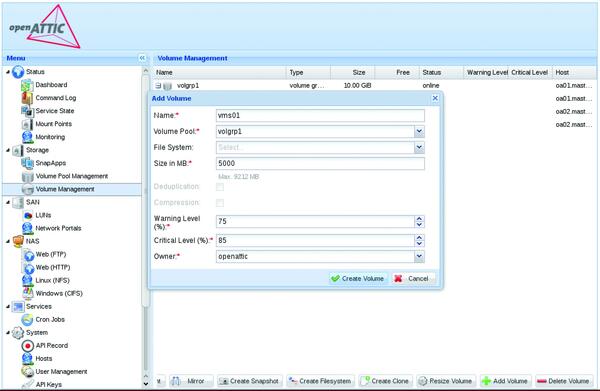 Bild 2: Das Formular zum Anlegen eines Volumes ist schnell ausgefüllt.
Bild 2: Das Formular zum Anlegen eines Volumes ist schnell ausgefüllt.
Wie bereits bei der Datenbank besteht auch hier das Problem, dass zur Hochverfügbarkeit noch ein automatisches Failover fehlt. Das konfigurieren wir wieder über Pacemaker (siehe Listing 3: Pacemaker für Volumes).
Diese Konfiguration ist analog zu der für die Datenbank angelegt. Sie weist Pacemaker an, das DRBD-Volume auf einem Node zum Primary zu ernennen, zu mounten, per NFS zu exportieren und anschließend die IP-Adresse 172.16. 14.252 auf dem Primary hinzuzufügen. Über diese IP-Adresse können Sie nun das Volume als Datenspeicher in vSphere hinzufügen.
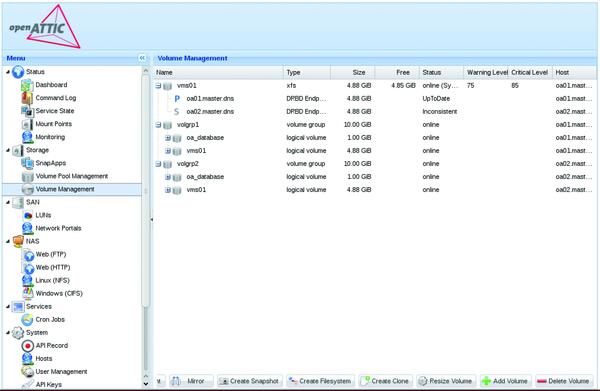 Bild 3: Das Dateisystem ist erfolgreich angelegt und die Volumes lassen sich verwalten.
Bild 3: Das Dateisystem ist erfolgreich angelegt und die Volumes lassen sich verwalten.
Einrichtung des Datastores in vSphere
Die Einbindung der Freigabe als Datenspeicher funktioniert wie bei jedem anderen NFS-Datenspeicher. Sie müssen nur berücksichtigen, dass Sie als Server-Adresse die Cluster-IP (172.16.14.252) angeben und nicht die IP-Adresse des ersten Nodes, denn die Cluster-IP zieht im Fehlerfall um und stellt auf diese Weise die Hochverfügbarkeit sicher. Ist der Datenspeicher eingebunden, kann der bereitgestellte Speicher für virtuelle Maschinen genutzt werden.
Ähnliche Artikel
-
openATTIC 1.2.0 veröffentlicht

Die freie Storage-Lösung openATTIC wurde in einer neuen Version veröffentlicht, die das Management von Snapshots verbessert.
-
Know-how: Virtuelle Workloads im Storage ausführen

-
Suse übernimmt openATTIC
Das Storage-Management-Framework soll künftig auch das Management der Storage-Lösung von Suse ermöglichen.
-
SUSE entwickelt neues Dashboard für Ceph
Statt openATTIC weiterzuentwickeln, erweitert SUSE jetzt das von Ceph ausgelieferte Dashboard-Tool.
-
Version 1.0 der freien Storage-Lösung OpenAttic 1.0 veröffentlicht
Das erste stabile Release der freien Storage-Lösung integriert Btrfs und ZFS.
Konfigurationsmanagement

Themen


