Prüfsummen sichern Daten bis in den Hauptspeicher
In bisherigen Speichersystemen (Filesysteme, Volume-Manager, Platten-Subsysteme) verlässt man sich auf die Sektorprüfsummen auf den Platten sowie darauf, dass die Platten mit einem RAID-Level gesichert sind. Damit wiegt man sich leider in einer trügerischen Sicherheit, denn:
- Die Sektorprüfsummen sind relativ kurz(meistens 8-16 bit), weshalb sie im schlimmsten Fall einen von 256 Fehlern nicht entdecken.
- RAID-1 (Spiegeln), RAID-5 (Striping mitParity) und RAID-6 (Striping mit zweifacherParity) schützen zwar vor den Folgen des Totalausfalls einer Platte, aber verfälschte Datenerkennen die RAID-Methoden (außer RAID2) nicht.Solche Fehler können verschiedene Ursachenhaben:
- Bit-Rot: Dieser Fehler entsteht, wenn die Daten in einem Sektor sich durch äußere Einflüsse spontan verändern („bit rot“, Verrottender Bits). Das kann durch Höhenstrahlung,Vibration, mechanische Einwirkung durchAbriebteilchen, Entladung von elektrostatisch aufgeladenen Staubteilchen an einemChip-Bein und so weiter passieren.Als Fehlerrate („non recoverable read errors“)rechnet man bei aktuellen Platten mit einemdefekten Sektor pro 1016 gelesener Bits. Dasentspricht 1,25 * 1015 Bytes oder 2.44 * 1012 Sektoren oder 1,136 TByte. Das heißt: Wer dieseDatenmenge liest, kann im Mittel einen Fehlererwarten, und nur einen Teil davon erkennt dieSektorprüfsumme. Dieser Fehler wird um sobrisanter, je mehr Daten gespeichert sind und jelänger sie ohne Umkopieren (und der damit verbundenen Neu-Magnetisierung) auf der Platteliegen.
- Fehlpositionierung: Andere Probleme resultieren aus einer Fehlpositionierung derLese- oder Schreibköpfe. Hier liegt die Fehlerrate bei etwa einer Fehlpositionierung pro108 Positionierungen, was bei Volllast einermodernen Platte (4 ms mittlere Zugriffszeit)schon nach 111 Stunden erreicht ist. Die Fehler äußern sich dann dadurch, dass die Platteeinen falschen Block liest (Misdirected Read)oder beschreibt (Misdirected Write) oder dieDaten über mehrere Sektoren verschmiert,wo sie nicht mehr auffindbar sind (PhantomWrite). Diese Fehler lassen sich mit Sektorprüfsummen nicht erkennen, da das Lesendie Prüfsumme als korrekt erkennt, obwohes der falsche Block ist.
- Fehler im Datenpfad: Bei der Datenübertragung verändert eine Komponente die Datenunbemerkt. Auslöser hierfür können sein:die Platten-Firmware, ein RAID-Controller, schlechte Anschlussleitungen, ein FibreChannel- oder Netzwerk-Switch, der HostBus-Adapter, die Firmware in einer Komponente oder die Treiber des Betriebssystems.Diese Fehler sind schwer zu quantifizieren, daviele verschiedene Parteien die Komponentenliefern und Sicherungsmaßnahmen verschiedener Qualität nutzen (wie Parity oder ECC).Solche Maßnahmen erkennen und behebeneinen Teil dieser Fehler durch Wiederholungdes Lesevorganges. Darauf machen meistMeldungen auf der Konsole aufmerksam.Das Ziel von ZFS ist es, alle diese Fehler vollständig zu erkennen und – sofern es eine redundante Speicherung gibt – auch zu beheben.Dazu ist in der bereits vorgestellten Baumstruktur bei jedem Blockzeiger eine Prüfsumme desBlocks gespeichert. Die Prüfsumme ist 256 bitlang, so dass nicht erkannte Fehler sehr viel unwahrscheinlicher sind als bei herkömmlichenSektorprüfsummen. Beim Lesen eines Blocksberechnet ZFS jedes Mal die Prüfsumme dergelesenen Daten und kann so feststellen, ob derBlock noch mit dem ursprünglich geschriebenen identisch ist. Einen falschen Block erkenntdas Filesystem nur mit der Wahrscheinlichkeitvon 1 zu 2256 als korrekt.
Redundanz und Self Healing
ZFS kann Daten selbstständig redundant speichern. Dazu beherrscht es ohne die Zuhilfenahme eines externen Volume-Managers das Spiegeln (RAID-1). ZFS legt dafür innerhalb seiner Datenstruktur die Daten doppelt auf der Platte und der Spiegelplatte ab. Außerdem beherrscht es eine RAID-5-Variante (Raidz, Raidz1) und eine RAID-6-Variante (Raidz2). Bei Raidz2 sind die Daten selbst dann noch verfügbar, wenn zwei Platten der RAID-Gruppe ausfallen. Das ist an und für sich ein bekannter Vorgang, zusammen mit den Prüfsummen ergibt sich jedoch eine neue Qualität: das sich selbst heilende Filesystem (Self Healing). Wenn ein herkömmliches Filesystem einen defekten Block liest, bleibt das unbemerkt. Eine Applikation verarbeitet die defekten Daten und liefert falsche Ergebnisse, meldet Fehler oder stürzt ab. Betrifft der Fehler einen Metadatenblock, der defekte Struktur-Informationen oder Attribute enthält, dann kann das System nur eine Kernel-Panik auslösen. Selbst wenn der Block eindeutig defekt ist und ein Spiegel vorliegt, gibt es bei den bisherigen Volume-Managern keinen Mechanismus, mit dessen Hilfe das System auf die wahrscheinlich intakte Kopie der anderen Spiegelseite (oder den zurückgerechneten Block in RAID-5) zugreifen könnte. ZFS dagegen kann sich mit den integrierten RAID-Leveln und den Prüfsummen selbst heilen.
Liest es einen defekten Datenblock, erkennt es den Fehler anhand der Prüfsumme, egal welcher der oben erwähnten Fehler auftrat. Da ZFS auch die redundante Speicherung implementiert, weiß es, an welcher Stelle der Spiegel zu finden ist oder wie der Datenblock aus RAID-5 oder RAID-6 zurückzurechnen ist. Es ist so in der Lage, den korrekten Block zu lesen beziehungsweise zu berechnen. Die Applikation (bei Daten) und der ZFS-Treiber (bei Metadaten) arbeiten also immer mit dem korrekten Block. Weiterhin kann ZFS den defekten Block sogar reparieren, indem es ihn einfach neu schreibt. ZFS repariert so Fehler nicht nur on-the-fly bei der Benutzung automatisch, es kann mit Hilfe eines speziellen Kommandos auch vorsorglich alle Spiegel oder die gesamte RAID-Zeile lesen und gegebenenfalls korrigieren (Scrubbing). Diese Funktionalität ist Stand heute (Mai 2007) allein in ZFS vorhanden weil sie an die Integration des Volume-Managers ins Filesystem gebunden ist.
Tabelle 1. ZFS im Vergleich
|
Parameter |
UFS (mit SVM) |
VxFS (mit VxVM) |
ZFS |
|---|---|---|---|
|
Maximale Größe |
16 TByte |
8 EByte |
16 EByte |
|
Transaktionen |
nein |
nein |
ja |
|
Konsistenzprüfung |
offline (»fsck«) |
offline (»fsck«) |
online (»zpool scrub«) |
|
Snapshots |
ja |
ja |
ja |
|
Filesystem-Vergrößerung |
ja (Volume + FS) |
ja (Volume + FS) |
ja (Zpool-Attribut) |
|
Filesystem-Verkleinerung |
nein |
ja (Volume + FS) |
ja (Zpool-Attribut) |
|
Filesystem-Clones |
nein |
nein |
ja |
|
Filesystem über mehrere Volumes |
nein |
ja |
ja |
|
Filesystem Quota |
ja, statisch |
ja, statisch |
ja, dynamisch änderbar |
|
Online modifizierbare Parameter |
einige |
wenige |
alle |
|
Erweiterte Attribute |
ja |
nein |
ja |
|
Kompression durch Filesystem |
nein |
nein |
ja |
|
Little-/Big-Endian-Unabhängigkeit |
nein |
nein |
ja |
|
Entdecken von Datenfehlern |
nein |
nein |
ja |
|
Online-Fehlerkorrektur |
nein |
nein |
ja |
|
Datenlayout |
statisch |
statisch |
dynamisch |
|
Benutzbar als Root-Filesystem |
ja |
nein |
geplant |
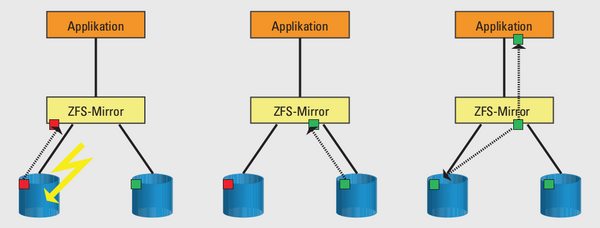 Abbildung 4: Nur in ZFS möglich: Das Filesystem erkennt und korrigiert defekte Blöcke mit Hilfe der unversehrten Kopie auf der zweiten Spiegelhälfte selbst oder dem Ergebnis einer Rückrechnung bei RAID-5 oder -6.
Abbildung 4: Nur in ZFS möglich: Das Filesystem erkennt und korrigiert defekte Blöcke mit Hilfe der unversehrten Kopie auf der zweiten Spiegelhälfte selbst oder dem Ergebnis einer Rückrechnung bei RAID-5 oder -6.
Bei herkömmlichen RAID-1, RAID5 oder RAID-6 Implementierungen können weitere Fehler auftreten, wenn es beim Schreiben einer RAID-Zeile zu einem Systemabbruch kommt, auch Schreibloch genannt (Write Hole). Dann stimmen die Spiegel nicht überein, oder die Parity stimmt nicht mehr. ZFS benutzt die erwähnten Transaktionen, um alle Spiegel beziehungsweise die gesamte RAID-Zeile auf einmal zu aktivieren. Das Schreibloch von Software-RAID kann also bei ZFS nicht auftreten, obwohl es auch eine Art Software-RAID implementiert.
durch Bit-Rot oder Fehlpositionierung defekte Daten liefern kann. Mit Self Healing prüft ZFS für jeden Block des Filesystems bei jedem Lesen Daten und Metadaten. Scrubbing entspricht dem »fsck« – im Unterschied zu »fsck«, lässt sich die Prüfung aber auch durchführen während das Filesystem in Benutzung ist. So kann man sich auch bei einem lange laufenden System auf die Integrität des Dateisystems verlassen.
Ähnliche Artikel
-
ZFS unter FreeBSD – Datensicherheit auf neuen Wegen

-
Ein Btrfs-Praxis-Check und -Workshop

-
Infortrend baut EonNAS-Familie aus
Die Speicherlösungen der EonNAS-Familie von Infortrend erhalten leistungsstarken Zuwachs.
-
Experimenteller Windows-Support für Deduplication-Filesystem
Das von Opendedup entwickelte Deduplikations-Dateisystem SDFS wurde nun auf Windows portiert.
-
Linux-Dateisysteme administrieren (1)

Konfigurationsmanagement

Themen


