
Benachrichtigung
Wurde eine Störung erkannt, muss der Benutzer davon erfahren. Was so einfach klingt, ist tatsächlich deutlich komplizierter. Denn es ergeben sich zahlreiche Ausnahmen und Sonderfälle: Während einer geplanten Auszeit etwa möchte man keine Nachrichten erhalten, nachts nur im Notfall, beispielsweise ab einem bestimmten Schweregrad. Der Chef soll erst angefunkt werden, wenn die Sache eskaliert oder kein Mitarbeiter bestätigt hat, dass er das Problem bearbeitet. An Sonn- und Feiertagen sollen andere Regeln gelten als werktags. Manchmal soll ein Einzelner zu Hilfe gerufen werden, manchmal eine Gruppe. Der eine ist am besten via E-Mail erreichbar, ein zweiter via SMS, der Dritte per Telefon oder Piepser. Wenn klar ist, was der Auslöser des Problems ist, sollen etwaige Folgefehler nicht auch noch Alarme initiieren. Und so weiter und so fort.
OpenNMS: OpenNMS kann Benachrichtigung sowohl an Benutzer und Gruppen als auch an vordefinierte Rollen verschicken. Dabei lassen sich ganze Benachrichtigungsketten an unterschiedliche Personen, Gruppen und Rollen über unterschiedlichste Medien wie SMS, Instant Messaging oder E-Mail aufbauen. Die Ketten können auf Wunsch durch eine Bestätigung unterbrochen werden. Innerhalb geplanter Auszeiten können das Polling, die Benachrichtigung, das Thresholding und die Data Collection deaktiviert werden. Um Folgefehler zu unterdrücken, ist die Konfiguration von Path Outages möglich, die Alarme für abhängige Nodes unterdrücken.
Zabbix: Wiederholte Benachrichtigungen, beliebig viele Eskalationsstufen, automatische Mitteilungen bis zur Problembeseitigung und im Erfolgsfall – auch Zabbix beherrscht das ganze Arsenal der Notifications. Mithilfe seiner Trigger, zwischen denen auch Abhängigkeiten definiert werden können, erlaubt Zabbix auch das Unterdrücken von Folgefehlern. Das geht in seinem Fall sogar mehrstufig: Ein lokaler Host kann beispielsweise von einem Switch an seinem Standort und zugleich von einem entfernten Router und zugleich von einem zentralen Router abhängen und würde dann nicht als defekt gemeldet, wenn tatsächlich eine der übergeordnete Komponente die eigentliche Ursache ist.
Icinga: Bei der Vielfalt der Benachrichtigungsformen steht auch Icinga nicht zurück, es beherrscht ebenfalls etwa die mehrstufige Eskalation, und es unterdrückt abgeleitete Fehler, nachdem sie einmal bestätigt wurden. Eine Spezialität von Icinga sind Voice-Notifications, die sogar Menüs enthalten können, mit denen sich etwa die Ansage wiederholen oder der Erhalt der Nachricht auch fern von einer Tastatur bestätigen lässt. Daneben ist auch Icinga in der Lage, durch vorher festgelegte Eltern-Kind-Beziehungen die bloße Nichterreichbarkeit von einem tatsächlichen Ausfall zu unterscheiden.
Nagios: Schließlich kann in dieser Sparte auch das klassische Nagios überall sein Kreuzchen machen. Im Wesentlichen beherrscht es dieselben Benachrichtigungstechniken wie die Konkurrenz.
Das Benutzerinterface – in der Regel eine Weboberfläche – bestimmt die Usability entscheidend mit. Das klassische Vorbild bringt Nagios mit: Die Ampeldarstellung haben später viele Nachfahren übernommen. Mittlerweile wirkt das Design allerdings ein wenig antiquiert. Heutzutage erwartet man eher ein Dashboard mit frei platzierbaren Elementen, die Visualisierung von Zeitreihen durch Diagramme, eingebettete Karten und Grundrisszeichnungen oder Grafiken, die die Auswirkungen auf Business-Prozesse illustrieren.
Benutzerinterfaces
In dieser Disziplin hat sich besonders Icinga ( Abbildung 3 ) mit einem innovativen Konzept hervorgetan. Ob es dafür nun gleich der Wortneuschöpfung "Cronk" für ein GUI-Element bedurft hätte oder nicht – das Webinterface von Icinga ist innovativ und voller praktischer Lösungen. So kann man alle Spalten der Status-Übersichten beliebig gruppieren und nach jeder Spalte sortieren, es gibt zahlreiche Filter- und Suchmöglichkeiten. Zudem lassen sich einzelne Kommandos gleichzeitig an eine Auswahl von Hosts verschicken. Der Admin kann sich Views vorkonfigurieren oder auch an andere weitergeben – dank des flexiblen Berechtigungskonzepts wahlweise auch als Nur-Lese-Ansicht.
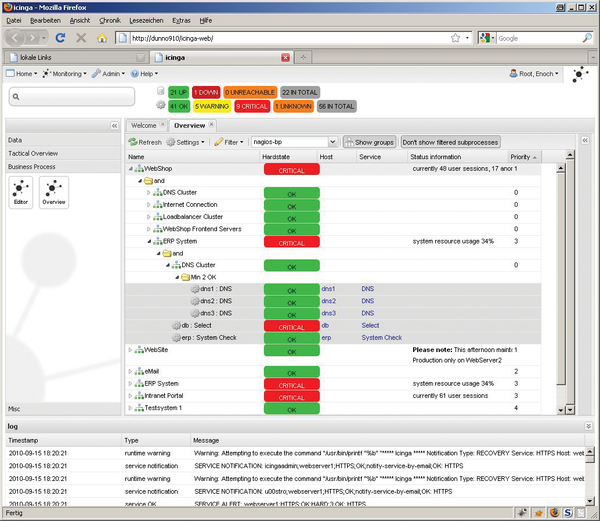 Abbildung 3: Icinga, hier mit dem Plugin Business Process View, bietet eine moderne und innovative Web-Benutzeroberfläche.
Abbildung 3: Icinga, hier mit dem Plugin Business Process View, bietet eine moderne und innovative Web-Benutzeroberfläche.
Das freie Nagios ist davon, wie gesagt, recht weit entfernt, auch wenn sich das eine oder andere dort noch über ein Plugin nachträglich einfügen lässt. Wesentlich näher dran ist da schon OpenNMS, das ebenfalls benutzerspezifische Sichten kennt und bei dem sich die Benutzerrechte auch fein justieren lassen. Eine weitere Gemeinsamkeit von OpenNMS und Icinga sind die teils bereits vorgefertigten Reports, die besonders das Management beeindrucken.
Damit sieht es bei Zabbix nicht ganz so gut aus, aber immerhin RRD-Diagramme oder Maps gehören auch dort zum Standard.
Ähnliche Artikel
-
Viel Neues in Sachen Monitoring

-
Einkaufsführer Open-Source-Monitoring

-
Monitoring-Gipfel
Eine Zwischenbilanz des Icinga-Projekts gehört mittlerweile zur Tradition der Nürnberger Open Source Monitoring Conference (OSMC). Daneben boten aber auch wieder viele andere Vorträge interessante Einsichten.
-
Icinga 1.3.0 veröffentlicht
Das Icinga-Entwicklerteam hat eine neue stabile Version seines Monitoring-Tools veröffentlicht.
-
Netzwerkmonitoring mit OpenNMS

Konfigurationsmanagement

Themen


