NoSQL-Datenbanken – Technologie und Projekte

NoSQL

Datenbanken gibt es seit Ende der 60er- und der 70er-Jahre. Schon bevor Edgar F. Codd das relationale Datenmodell einführte, kannte man anders strukturierte Datenbankmodelle. 1979 entwickelte etwa Ken Thompson eine Hash-orientierte Datenbank, und in den 90er-Jahren erschienen mit Lotus, BerkeleyDB oder GT.M viele weitere Datenbanken. Danach setzte sich in den 80er- und 90er-Jahren allerdings das relationale Modell aus gutem Grund durch. Dafür sprachen neben dem konsistenten mathematischen Modell einige weitere Gründe: Es gab überwiegend statische Daten, die meisten Anwendungen liefen auf einem Server, und es war von Vorteil, mit Normalisierung Plattenplatz zu sparen.
Im Web-2.0-Zeitalter gibt es viele Anwendungsbereiche, in denen die oben genannten Gründe nicht mehr gelten. Zum einen sind die Daten inzwischen kaum mehr statisch. Analysen zufolge sind über 90 Prozent aller Daten im Web ständigen Änderungen unterworfen und eher unstrukturiert. Zum anderen haben Web-2.0-Firmen wie Google, Yahoo, Facebook, LinkedIn, Digg oder MySpace so viele Daten, dass sie sich nicht mehr auf einem Server hosten und verarbeiten lassen. Und schließlich muss man heutzutage kaum mehr Plattenplatz sparen.
Was heißt NoSQL?
Der Wegfall von Argumenten für das relationale Modell hat daher der Konkurrenz wieder mehr Raum gegeben und die Verbreitung von NoSQL-Datenbanken gefördert. Doch was genau ist damit gemeint? Ein Definitionsversuch findet sich auf [2] . Danach sind NoSQL-Datenbanken:
Nicht-relational: Wie bereits oben erwähnt, ist die Nicht-Relationalität eher ein Kriterium für eine NoSQL Datenbank als die fehlende Verwendung von SQL. Entscheidend ist hier, dass die Datenbank ein ganz anders Datenmodell umsetzt, beispielsweise Dokumentenstrukturen (wie JSON) oder Graphenstrukturen.
Verteilt und horizontal skalierbar: NoSQL-Datenbanken sind in der Regel auf eine einfache horizontale Skalierung ausgelegt (Scale-Out), siehe Abbildung 1 . Mit minimalem Aufwand und ohne Verlust der Erreichbarkeit lässt sich dabei weitere handelsübliche Hardware in das Datenbanksystem einfügen. Im Gegensatz dazu wurde in den 80er- und 90er-Jahren meist vertikal skaliert, das heißt, der Server aufgerüstet.
 Abbildung 1: Scale-Up versus Scale-Out – während man früher zumeist größere Server anschaffen musste, sobald man an die Leistungsgrenze kam, erlauben heutige, horizontal skalierbare Architekturen einfach das Hinzufügen weiterer Commodity-Hardware.
Abbildung 1: Scale-Up versus Scale-Out – während man früher zumeist größere Server anschaffen musste, sobald man an die Leistungsgrenze kam, erlauben heutige, horizontal skalierbare Architekturen einfach das Hinzufügen weiterer Commodity-Hardware.
Open Source: Die meisten NoSQL-Datenbanken sind Open Source. Dies kann eine Kostenersparnis bedeuten, muss es aber natürlich nicht zwingend.
Web-Scale und schemafrei: NoSQL-Datenbanksysteme sind für den skalierbaren Einsatz im Web prädestiniert. Gründe dafür sind die Datenmenge und ihre flüchtige Struktur: Webdaten ändern ihre Struktur häufig. Gleichzeitig ist eine Downtime wegen
»ALTER TABLE«
aber nicht immer akzeptabel.
Einfache Replikation: Wenn Datenbanken auf eine Scale-Out-Architektur ausgerichtet sind, dann ist Replikation ein wichtiger Faktor. Und meistens ist das ebenfalls ein Kernelement von NoSQL-Datenbanken. Replikation in NoSQL-Systemen wie CouchDB oder Riak lässt sich deshalb mit nur einer Anweisung auf der Kommandozeile oder lediglich mit einer Konfigurationseinstellung bewerkstelligen. Im Gegensatz dazu merkt man bei vielen relationalen Datenbanken, dass das Datenmodell im Vordergrund steht und Möglichkeiten für die Skalierung und Replikation erst später hinzugefügt wurden und komplizierter zu handhaben sind.
Einfache API: In relationalen Systemen ist SQL eine Schnittstelle mit vielen Vor- und Nachteilen. NoSQL-Systeme gehen hier oft ganz andere Wege und bieten unterschiedliche Schnittstellen und Abfragemodelle an. Sehr viele NoSQL-Datenbanken offerieren etwa REST-Schnittstellen, bei denen die Datenbank komplett via Web-Anfragen verwaltet wird. Des Weiteren gibt es oft Datenbankschnittstellen wie Apache Thrift [3] für alle Programmiersprachen und auch oft native Abfragen, die LINQ ähneln [4] .
Schwächere Transaktionsanforderungen: Was für Banken wichtig ist – nämlich ACID-Transaktionen – ist für viele Webanwendungen verzichtbar. Facebook- oder Twitter-Einträge müssen nicht transaktionsfest sein. Viele dieser Daten sind auch unzusammenhängend, müssen also auch nicht mit kostspieligen Join-Operatoren durchsucht werden. Wenn aber ACID und Join-Abfragen einen anderen Stellenwert haben, kann man ganz andere Datenbanksysteme bauen, die besser skalieren. In der Regel gelten für NoSQL-Systeme viele dieser Kriterien. Es müssen jedoch nicht zwingend alle Kriterien erfüllt sein. Die Community übersetzt NoSQL mittlerweile als "Not Only SQL" und verweist damit auch auf das Recht, über andere Lösungen als relationale Datenbanken nachzudenken.
Klassifikation
Welche Klassen von NoSQL-Datenbanken gibt es nun? Man unterscheidet – wie in Abbildung 2 (mittlere Schicht) dargestellt – meistens vier Gruppen (stores steht hier für Datenbank):
 Abbildung 2: Arbeitsweise des Map/Reduce-Verfahrens, das sich eignet, um rechenintensive Prozesse zu parallelisieren.
Abbildung 2: Arbeitsweise des Map/Reduce-Verfahrens, das sich eignet, um rechenintensive Prozesse zu parallelisieren.
- Wide Column Stores: NoSQL-DBs mit tabellenartigen Datenstrukturen für extreme Datenmengen.
- Document Stores: NoSQL-DBs, die interpretierbare Dokumente definierter Struktur (wie JSON) speichern.
- Key/Value Stores: NoSQL-DBs, die Hash-Strukturen, also beliebig viele Key/Value-Paare speichern.
- Graph Databases: Datenbanken, die Graphenstrukturen speichern.
Es gibt noch viele weitere Datenbankarten wie XML- oder Objekt-, Grid- oder Multi-Value-Datenbanken, die man unter Umständen auch dem NoSQL-Bereich zurechnen kann. Jedoch stehen die NoSQL-Datenbanken der oben genannten vier Gruppen im Hauptfokus der NoSQL-Bewegung.
Zusammenfassend ergeben sich – in Bezug auf den Vergleich mit relationalen Datenbanken – Unterschiede in drei Ebenen, die Abbildung 3 darstellt. Zugriff auf die NoSQL-Datenbank erhält man meistens über ein REST-Protokoll, das erwähnte Thrift, ein einfaches Get/Put für Hashes oder über die unzähligen Sprachanbindungen. Auf der Schicht des Datenmodells gibt es (Wide) Column Families, eindeutig definiert parsierbare Dokumente, Key/Value-Strukturen (Hashes) und Graphenstrukturen.
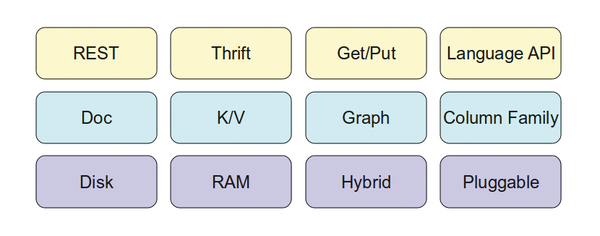 Abbildung 3: Sowohl in der Zugriffsschicht wie auf der Ebene der Datenmodelle wie auch im Speichermodell ergeben sich Unterschiede zwischen den vier Hauptgruppen der NoSQL- und relationalen Datenbanken.
Abbildung 3: Sowohl in der Zugriffsschicht wie auf der Ebene der Datenmodelle wie auch im Speichermodell ergeben sich Unterschiede zwischen den vier Hauptgruppen der NoSQL- und relationalen Datenbanken.
Interessant ist aber auch, dass einige Datenbanken auch im Speichermodell ungewöhnliche Wege gehen. Zwar speichern die meisten Programme immer noch auf Platte, daneben aber gibt es viele RAM- und RAM-Hybrid Lösungen. Programme wie Scalaris oder Hazelcast setzen vollständig auf RAM und sorgen für transparente Replikation. Nach Argumentation dieser Programme ist repliziertes RAM nicht unsicherer als das Schreiben auf die Platte. Andere NoSQL-Datenbanken wie MongoDB oder Redis setzen auf eine Hybridlösung. Auch hier sollten alle Daten (oder mit Virtual Memory mindestens als Schlüssel) in den RAM passen, sie werden in konfigurierbaren Zeitintervallen mit der Festplatte synchronisiert. Dies hat extreme Performancevorteile, ist aber vielleicht nicht hundertprozentig ausfallsicher. Als letzte Variante erlauben viele NoSQL-Datenbanken die Definition einer beliebigen Speicher-Engine. Sogar auch relationale Datenbanken lassen sich oft als Unterbau einsetzen.
Abschließend bleibt anzumerken, dass viele der NoSQL-Datenbanken von Web-2.0-Firmen selbst entwickelt wurden, die sie dann häufig als Open Source freigaben. So geschehen bei Yahoo, das Hadoop erschaffen hat, oder beim Akamai Team, das Riak entwickelte.
NoSQL kann nicht ordentlich ohne etwas theoretischen Hintergrund verstanden werden. Dabei gibt es ganz grob fünf Konzepte, auf denen verteilte NoSQL-Systeme aufbauen. Sie können hier nur kurz angesprochen werden, weiterführende Literatur wie [1] hilft dabei, diese Themen zu vertiefen.
Ähnliche Artikel
-
CouchDB-Gründer verabschiedet sich von Apache-Projekt
Der Erfinder der NoSQL-Datenbank CouchDB wendet sich vom Apache-Projekt ab und widmet sich der Neuentwicklung seiner Datenbank unter dem Namen Couchbase. Im CouchDB-Markt konkurrierende Unternehmen stecken nun ihre Felder ab.
-
NoSQL-Datenbanken lokal und in der Cloud

-
Alternativen zu SQL

-
Microsoft veröffentlicht Redis für Windows
Die neue Initiative Microsoft Open Technologies legt als erstes freies Produkt einen Port der NoSQL-Datenbank Redis für Windows vor.
-
Tipps, Tricks & Tools

Konfigurationsmanagement

Themen


